 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit In-Context Learning: Evidence from Artificial Language Experiments
Mar 31, 2025Humans acquire language through implicit learning, absorbing complex patterns without explicit awareness. While LLMs demonstrate impressive linguistic capabilities, it remains unclear whether they exhibit human-like pattern recognition during in-context learning at inferencing level. We adapted three classic artificial language learning experiments spanning morphology, morphosyntax, and syntax to systematically evaluate implicit learning at inferencing level in two state-of-the-art OpenAI models: gpt-4o and o3-mini. Our results reveal linguistic domain-specific alignment between models and human behaviors, o3-mini aligns better in morphology while both models align in syntax.
Does Conceptual Representation Require Embodiment? Insights From Large Language Models
May 30, 2023



Recent advances in large language models (LLM) have the potential to shed light on the debate regarding the extent to which knowledge representation requires the grounding of embodied experience. Despite learning from limited modalities (e.g., text for GPT-3.5, and text+image for GPT-4), LLMs have nevertheless demonstrated human-like behaviors in various psychology tasks, which may provide an alternative interpretation of the acquisition of conceptual knowledge. We compared lexical conceptual representations between humans and ChatGPT (GPT-3.5 and GPT-4) on subjective ratings of various lexical conceptual features or dimensions (e.g., emotional arousal, concreteness, haptic, etc.). The results show that both GPT-3.5 and GPT-4 were strongly correlated with humans in some abstract dimensions, such as emotion and salience. In dimensions related to sensory and motor domains, GPT-3.5 shows weaker correlations while GPT-4 has made significant progress compared to GPT-3.5. Still, GPT-4 struggles to fully capture motor aspects of conceptual knowledge such as actions with foot/leg, mouth/throat, and torso. Moreover, we found that GPT-4's progress can largely be associated with its training in the visual domain. Certain aspects of conceptual representation appear to exhibit a degree of independence from sensory capacities, but others seem to necessitate them. Our findings provide insights into the complexities of knowledge representation from diverse perspectives and highlights the potential influence of embodied experience in shaping language and cognition.
ToMChallenges: A Principle-Guided Dataset and Diverse Evaluation Tasks for Exploring Theory of Mind
May 24, 2023



Theory of Mind (ToM), the capacity to comprehend the mental states of distinct individuals, is essential for numerous practical applications. With the development of large language models, there is a heated debate about whether they are able to perform ToM tasks. Previous studies have used different tasks and prompts to test the ToM on large language models and the results are inconsistent: some studies asserted these models are capable of exhibiting ToM, while others suggest the opposite. In this study, We present ToMChallenges, a dataset for comprehensively evaluating Theory of Mind based on Sally-Anne and Smarties tests. We created 30 variations of each test (e.g., changing the person's name, location, and items). For each variation, we test the model's understanding of different aspects: reality, belief, 1st order belief, and 2nd order belief. We adapt our data for various tasks by creating unique prompts tailored for each task category: Fill-in-the-Blank, Multiple Choice, True/False, Chain-of-Thought True/False, Question Answering, and Text Completion. If the model has a robust ToM, it should be able to achieve good performance for different prompts across different tests. We evaluated two GPT-3.5 models, text-davinci-003 and gpt-3.5-turbo-0301, with our datasets. Our results indicate that consistent performance in ToM tasks remains a challenge.
MOGAN: Morphologic-structure-aware Generative Learning from a Single Image
Mar 04, 2021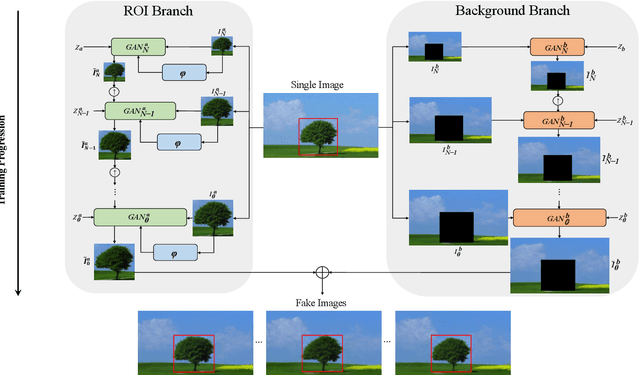
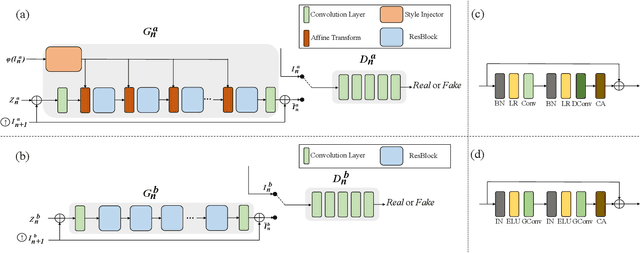
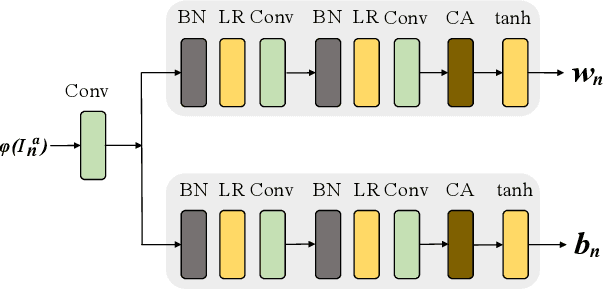

In most interactive image generation tasks, given regions of interest (ROI) by users, the generated results are expected to have adequate diversities in appearance while maintaining correct and reasonable structures in original images. Such tasks become more challenging if only limited data is available. Recently proposed generative models complete training based on only one image. They pay much attention to the monolithic feature of the sample while ignoring the actual semantic information of different objects inside the sample. As a result, for ROI-based generation tasks, they may produce inappropriate samples with excessive randomicity and without maintaining the related objects' correct structures. To address this issue, this work introduces a MOrphologic-structure-aware Generative Adversarial Network named MOGAN that produces random samples with diverse appearances and reliable structures based on only one image. For training for ROI, we propose to utilize the data coming from the original image being augmented and bring in a novel module to transform such augmented data into knowledge containing both structures and appearances, thus enhancing the model's comprehension of the sample. To learn the rest areas other than ROI, we employ binary masks to ensure the generation isolated from ROI. Finally, we set parallel and hierarchical branches of the mentioned learning process. Compared with other single image GAN schemes, our approach focuses on internal features including the maintenance of rational structures and variation on appearance. Experiments confirm a better capacity of our model on ROI-based image generation tasks than its competitive peers.