 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive-KD: Multi-Teacher Distillation for VLMs in Autonomous Driving
Jan 29, 2026Autonomous driving is an important and safety-critical task, and recent advances in LLMs/VLMs have opened new possibilities for reasoning and planning in this domain. However, large models demand substantial GPU memory and exhibit high inference latency, while conventional supervised fine-tuning (SFT) often struggles to bridge the capability gaps of small models. To address these limitations, we propose Drive-KD, a framework that decomposes autonomous driving into a "perception-reasoning-planning" triad and transfers these capabilities via knowledge distillation. We identify layer-specific attention as the distillation signal to construct capability-specific single-teacher models that outperform baselines. Moreover, we unify these single-teacher settings into a multi-teacher distillation framework and introduce asymmetric gradient projection to mitigate cross-capability gradient conflicts. Extensive evaluations validate the generalization of our method across diverse model families and scales. Experiments show that our distilled InternVL3-1B model, with ~42 times less GPU memory and ~11.4 times higher throughput, achieves better overall performance than the pretrained 78B model from the same family on DriveBench, and surpasses GPT-5.1 on the planning dimension, providing insights toward efficient autonomous driving VLMs.
AutoDriDM: An Explainable Benchmark for Decision-Making of Vision-Language Models in Autonomous Driving
Jan 21, 2026Autonomous driving is a highly challenging domain that requires reliable perception and safe decision-making in complex scenarios. Recent vision-language models (VLMs) demonstrate reasoning and generalization abilities, opening new possibilities for autonomous driving; however, existing benchmarks and metrics overemphasize perceptual competence and fail to adequately assess decision-making processes. In this work, we present AutoDriDM, a decision-centric, progressive benchmark with 6,650 questions across three dimensions - Object, Scene, and Decision. We evaluate mainstream VLMs to delineate the perception-to-decision capability boundary in autonomous driving, and our correlation analysis reveals weak alignment between perception and decision-making performance. We further conduct explainability analyses of models' reasoning processes, identifying key failure modes such as logical reasoning errors, and introduce an analyzer model to automate large-scale annotation. AutoDriDM bridges the gap between perception-centered and decision-centered evaluation, providing guidance toward safer and more reliable VLMs for real-world autonomous driving.
Solving the Food-Energy-Water Nexus Problem via Intelligent Optimization Algorithms
Apr 10, 2024The application of evolutionary algorithms (EAs) to multi-objective optimization problems has been widespread. However, the EA research community has not paid much attention to large-scale multi-objective optimization problems arising from real-world applications. Especially, Food-Energy-Water systems are intricately linked among food, energy and water that impact each other. They usually involve a huge number of decision variables and many conflicting objectives to be optimized. Solving their related optimization problems is essentially important to sustain the high-quality life of human beings. Their solution space size expands exponentially with the number of decision variables. Searching in such a vast space is challenging because of such large numbers of decision variables and objective functions. In recent years, a number of large-scale many-objectives optimization evolutionary algorithms have been proposed. In this paper, we solve a Food-Energy-Water optimization problem by using the state-of-art intelligent optimization methods and compare their performance. Our results conclude that the algorithm based on an inverse model outperforms the others. This work should be highly useful for practitioners to select the most suitable method for their particular large-scale engineering optimization problems.
MOGAN: Morphologic-structure-aware Generative Learning from a Single Image
Mar 04, 2021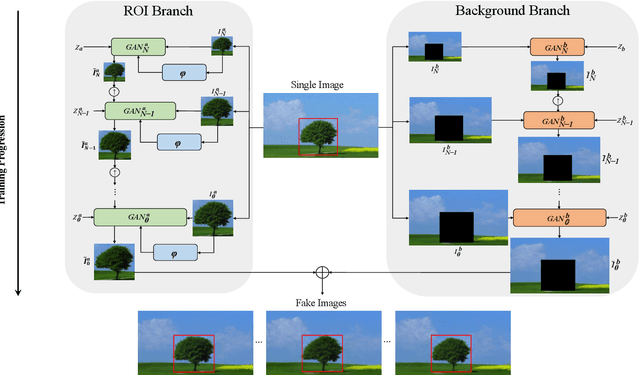
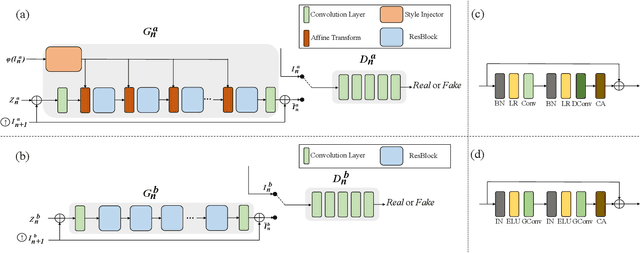
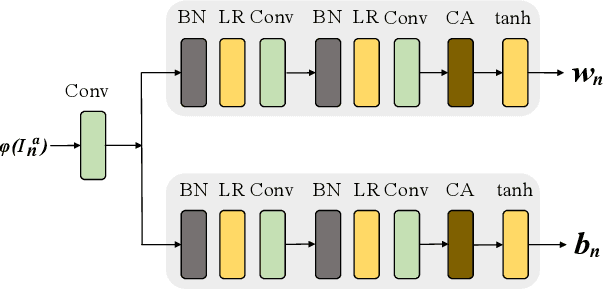

In most interactive image generation tasks, given regions of interest (ROI) by users, the generated results are expected to have adequate diversities in appearance while maintaining correct and reasonable structures in original images. Such tasks become more challenging if only limited data is available. Recently proposed generative models complete training based on only one image. They pay much attention to the monolithic feature of the sample while ignoring the actual semantic information of different objects inside the sample. As a result, for ROI-based generation tasks, they may produce inappropriate samples with excessive randomicity and without maintaining the related objects' correct structures. To address this issue, this work introduces a MOrphologic-structure-aware Generative Adversarial Network named MOGAN that produces random samples with diverse appearances and reliable structures based on only one image. For training for ROI, we propose to utilize the data coming from the original image being augmented and bring in a novel module to transform such augmented data into knowledge containing both structures and appearances, thus enhancing the model's comprehension of the sample. To learn the rest areas other than ROI, we employ binary masks to ensure the generation isolated from ROI. Finally, we set parallel and hierarchical branches of the mentioned learning process. Compared with other single image GAN schemes, our approach focuses on internal features including the maintenance of rational structures and variation on appearance. Experiments confirm a better capacity of our model on ROI-based image generation tasks than its competitive peers.