 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAD-CARE: A Guideline-grounded, Modality-agnostic LLM Agent for Real-world Alzheimer's Disease Diagnosis with Multi-cohort Assessment, Fairness Analysis, and Reader Study
Mar 26, 2026Alzheimer's disease (AD) is a growing global health challenge as populations age, and timely, accurate diagnosis is essential to reduce individual and societal burden. However, real-world AD assessment is hampered by incomplete, heterogeneous multimodal data and variability across sites and patient demographics. Although large language models (LLMs) have shown promise in biomedicine, their use in AD has largely been confined to answering narrow, disease-specific questions rather than generating comprehensive diagnostic reports that support clinical decision-making. Here we expand LLM capabilities for clinical decision support by introducing AD-CARE, a modality-agnostic agent that performs guideline-grounded diagnostic assessment from incomplete, heterogeneous inputs without imputing missing modalities. By dynamically orchestrating specialized diagnostic tools and embedding clinical guidelines into LLM-driven reasoning, AD-CARE generates transparent, report-style outputs aligned with real-world clinical workflows. Across six cohorts comprising 10,303 cases, AD-CARE achieved 84.9% diagnostic accuracy, delivering 4.2%-13.7% relative improvements over baseline methods. Despite cohort-level differences, dataset-specific accuracies remain robust (80.4%-98.8%), and the agent consistently outperforms all baselines. AD-CARE reduced performance disparities across racial and age subgroups, decreasing the average dispersion of four metrics by 21%-68% and 28%-51%, respectively. In a controlled reader study, the agent improved neurologist and radiologist accuracy by 6%-11% and more than halved decision time. The framework yielded 2.29%-10.66% absolute gains over eight backbone LLMs and converges their performance. These results show that AD-CARE is a scalable, practically deployable framework that can be integrated into routine clinical workflows for multimodal decision support in AD.
Implicit In-Context Learning: Evidence from Artificial Language Experiments
Mar 31, 2025Humans acquire language through implicit learning, absorbing complex patterns without explicit awareness. While LLMs demonstrate impressive linguistic capabilities, it remains unclear whether they exhibit human-like pattern recognition during in-context learning at inferencing level. We adapted three classic artificial language learning experiments spanning morphology, morphosyntax, and syntax to systematically evaluate implicit learning at inferencing level in two state-of-the-art OpenAI models: gpt-4o and o3-mini. Our results reveal linguistic domain-specific alignment between models and human behaviors, o3-mini aligns better in morphology while both models align in syntax.
DiM-Gesture: Co-Speech Gesture Generation with Adaptive Layer Normalization Mamba-2 framework
Aug 01, 2024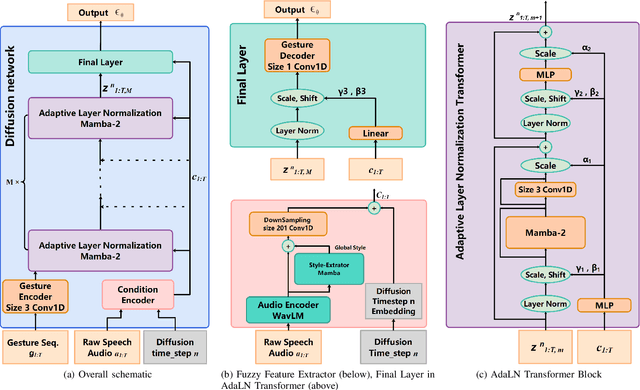
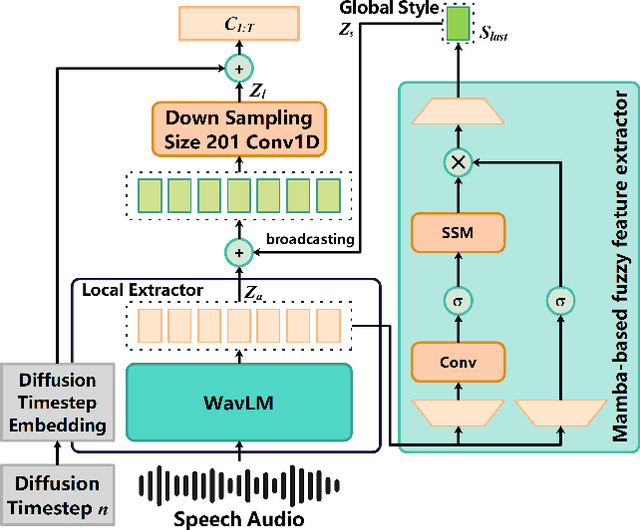
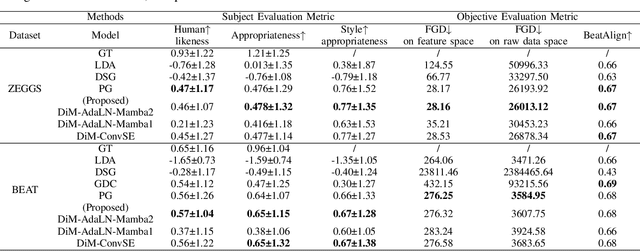
Speech-driven gesture generation is an emerging domain within virtual human creation, where current methods predominantly utilize Transformer-based architectures that necessitate extensive memory and are characterized by slow inference speeds. In response to these limitations, we propose \textit{DiM-Gestures}, a novel end-to-end generative model crafted to create highly personalized 3D full-body gestures solely from raw speech audio, employing Mamba-based architectures. This model integrates a Mamba-based fuzzy feature extractor with a non-autoregressive Adaptive Layer Normalization (AdaLN) Mamba-2 diffusion architecture. The extractor, leveraging a Mamba framework and a WavLM pre-trained model, autonomously derives implicit, continuous fuzzy features, which are then unified into a singular latent feature. This feature is processed by the AdaLN Mamba-2, which implements a uniform conditional mechanism across all tokens to robustly model the interplay between the fuzzy features and the resultant gesture sequence. This innovative approach guarantees high fidelity in gesture-speech synchronization while maintaining the naturalness of the gestures. Employing a diffusion model for training and inference, our framework has undergone extensive subjective and objective evaluations on the ZEGGS and BEAT datasets. These assessments substantiate our model's enhanced performance relative to contemporary state-of-the-art methods, demonstrating competitive outcomes with the DiTs architecture (Persona-Gestors) while optimizing memory usage and accelerating inference speed.
ToMChallenges: A Principle-Guided Dataset and Diverse Evaluation Tasks for Exploring Theory of Mind
May 24, 2023



Theory of Mind (ToM), the capacity to comprehend the mental states of distinct individuals, is essential for numerous practical applications. With the development of large language models, there is a heated debate about whether they are able to perform ToM tasks. Previous studies have used different tasks and prompts to test the ToM on large language models and the results are inconsistent: some studies asserted these models are capable of exhibiting ToM, while others suggest the opposite. In this study, We present ToMChallenges, a dataset for comprehensively evaluating Theory of Mind based on Sally-Anne and Smarties tests. We created 30 variations of each test (e.g., changing the person's name, location, and items). For each variation, we test the model's understanding of different aspects: reality, belief, 1st order belief, and 2nd order belief. We adapt our data for various tasks by creating unique prompts tailored for each task category: Fill-in-the-Blank, Multiple Choice, True/False, Chain-of-Thought True/False, Question Answering, and Text Completion. If the model has a robust ToM, it should be able to achieve good performance for different prompts across different tests. We evaluated two GPT-3.5 models, text-davinci-003 and gpt-3.5-turbo-0301, with our datasets. Our results indicate that consistent performance in ToM tasks remains a challenge.
Evaluating Transformer Models and Human Behaviors on Chinese Character Naming
Mar 22, 2023Neural network models have been proposed to explain the grapheme-phoneme mapping process in humans for many alphabet languages. These models not only successfully learned the correspondence of the letter strings and their pronunciation, but also captured human behavior in nonce word naming tasks. How would the neural models perform for a non-alphabet language (e.g., Chinese) unknown character task? How well would the model capture human behavior? In this study, we evaluate a set of transformer models and compare their performances with human behaviors on an unknown Chinese character naming task. We found that the models and humans behaved very similarly, that they had similar accuracy distribution for each character, and had a substantial overlap in answers. In addition, the models' answers are highly correlated with humans' answers. These results suggested that the transformer models can well capture human's character naming behavior.
How do we get there? Evaluating transformer neural networks as cognitive models for English past tense inflection
Oct 17, 2022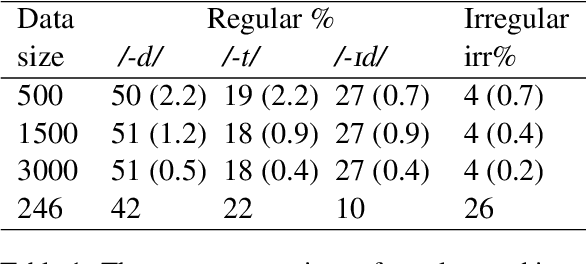


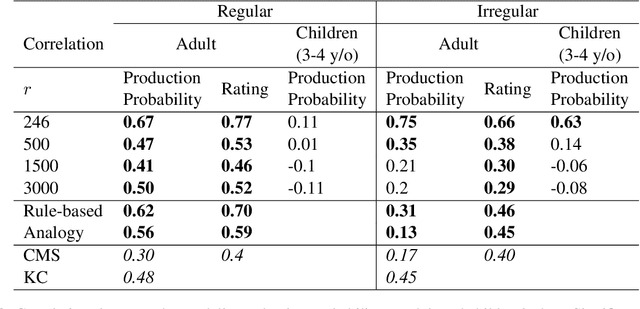
There is an ongoing debate on whether neural networks can grasp the quasi-regularities in languages like humans. In a typical quasi-regularity task, English past tense inflections, the neural network model has long been criticized that it learns only to generalize the most frequent pattern, but not the regular pattern, thus can not learn the abstract categories of regular and irregular and is dissimilar to human performance. In this work, we train a set of transformer models with different settings to examine their behavior on this task. The models achieved high accuracy on unseen regular verbs and some accuracy on unseen irregular verbs. The models' performance on the regulars is heavily affected by type frequency and ratio but not token frequency and ratio, and vice versa for the irregulars. The different behaviors on the regulars and irregulars suggest that the models have some degree of symbolic learning on the regularity of the verbs. In addition, the models are weakly correlated with human behavior on nonce verbs. Although the transformer model exhibits some level of learning on the abstract category of verb regularity, its performance does not fit human data well, suggesting that it might not be a good cognitive model.