 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiM-Gesture: Co-Speech Gesture Generation with Adaptive Layer Normalization Mamba-2 framework
Paper and Code
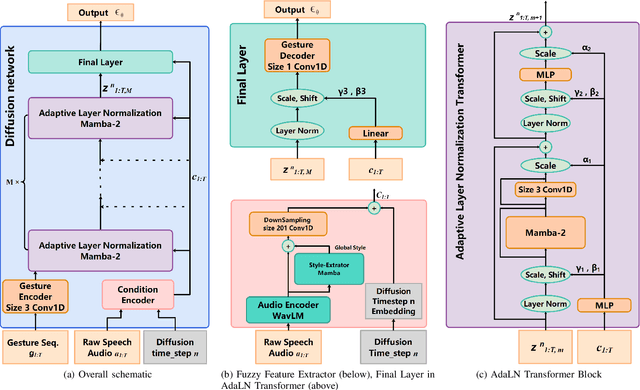
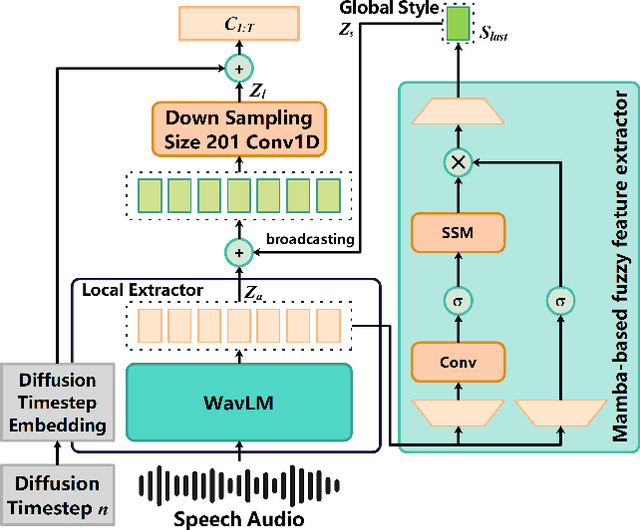
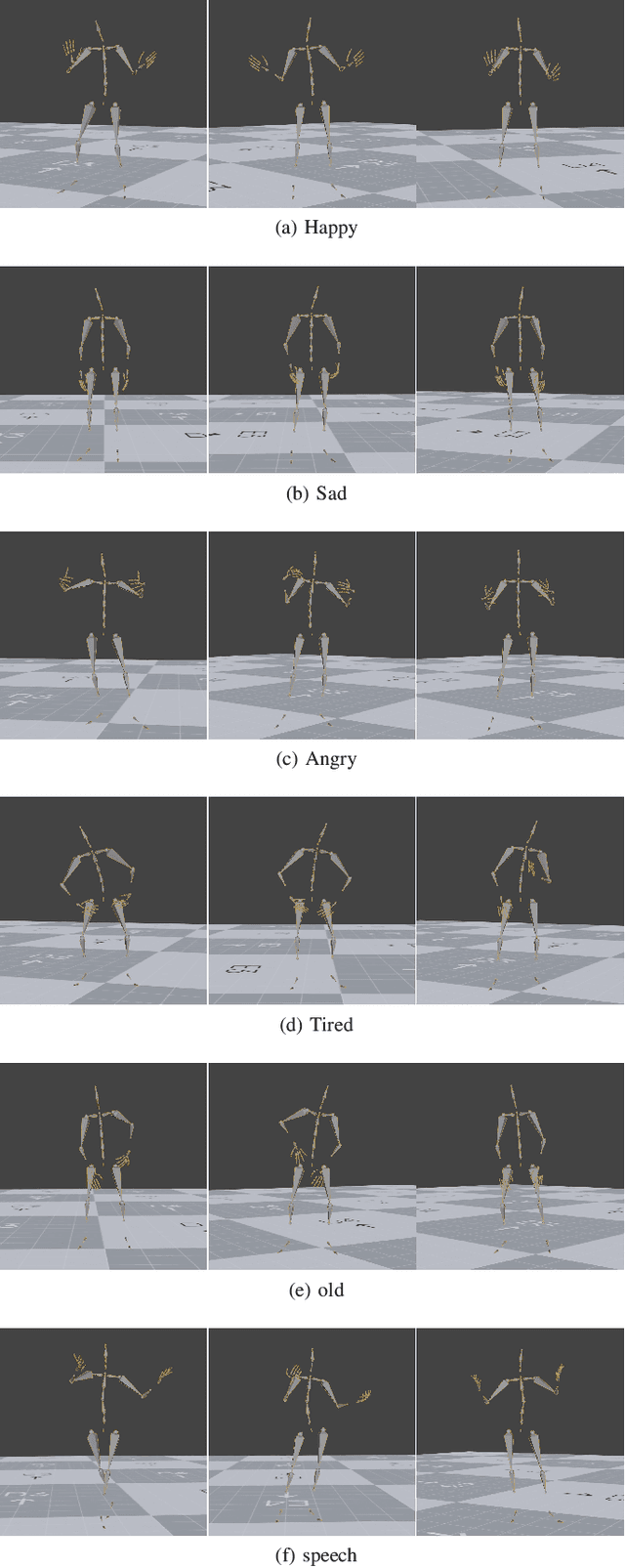
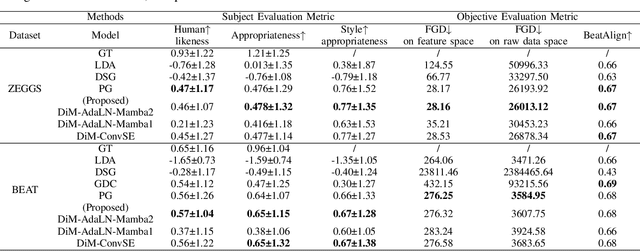
Speech-driven gesture generation is an emerging domain within virtual human creation, where current methods predominantly utilize Transformer-based architectures that necessitate extensive memory and are characterized by slow inference speeds. In response to these limitations, we propose \textit{DiM-Gestures}, a novel end-to-end generative model crafted to create highly personalized 3D full-body gestures solely from raw speech audio, employing Mamba-based architectures. This model integrates a Mamba-based fuzzy feature extractor with a non-autoregressive Adaptive Layer Normalization (AdaLN) Mamba-2 diffusion architecture. The extractor, leveraging a Mamba framework and a WavLM pre-trained model, autonomously derives implicit, continuous fuzzy features, which are then unified into a singular latent feature. This feature is processed by the AdaLN Mamba-2, which implements a uniform conditional mechanism across all tokens to robustly model the interplay between the fuzzy features and the resultant gesture sequence. This innovative approach guarantees high fidelity in gesture-speech synchronization while maintaining the naturalness of the gestures. Employing a diffusion model for training and inference, our framework has undergone extensive subjective and objective evaluations on the ZEGGS and BEAT datasets. These assessments substantiate our model's enhanced performance relative to contemporary state-of-the-art methods, demonstrating competitive outcomes with the DiTs architecture (Persona-Gestors) while optimizing memory usage and accelerating inference speed.