 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARC: Active and Reflection-driven Context Management for Long-Horizon Information Seeking Agents
Jan 17, 2026Large language models are increasingly deployed as research agents for deep search and long-horizon information seeking, yet their performance often degrades as interaction histories grow. This degradation, known as context rot, reflects a failure to maintain coherent and task-relevant internal states over extended reasoning horizons. Existing approaches primarily manage context through raw accumulation or passive summarization, treating it as a static artifact and allowing early errors or misplaced emphasis to persist. Motivated by this perspective, we propose ARC, which is the first framework to systematically formulate context management as an active, reflection-driven process that treats context as a dynamic internal reasoning state during execution. ARC operationalizes this view through reflection-driven monitoring and revision, allowing agents to actively reorganize their working context when misalignment or degradation is detected. Experiments on challenging long-horizon information-seeking benchmarks show that ARC consistently outperforms passive context compression methods, achieving up to an 11% absolute improvement in accuracy on BrowseComp-ZH with Qwen2.5-32B-Instruct.
DiM-Gesture: Co-Speech Gesture Generation with Adaptive Layer Normalization Mamba-2 framework
Aug 01, 2024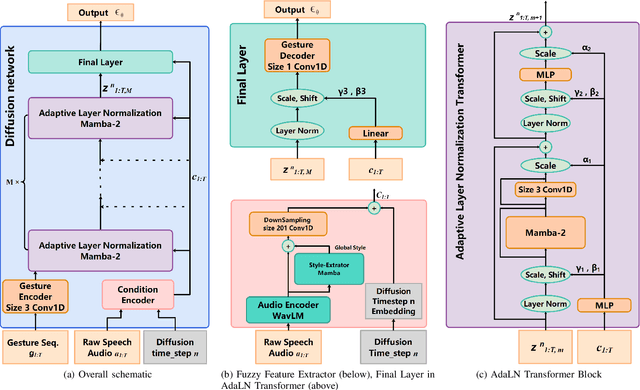
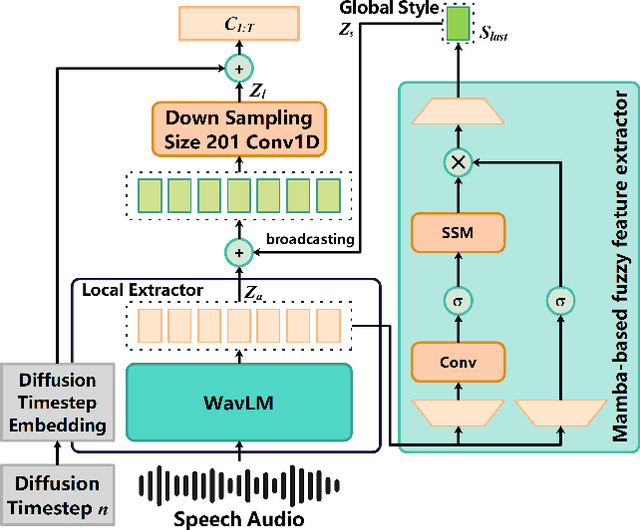
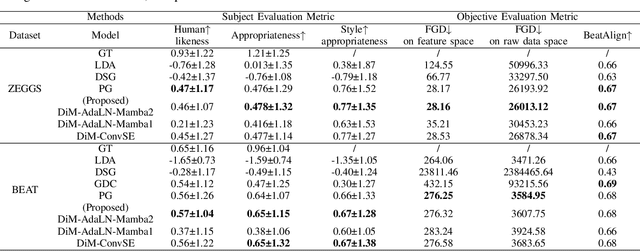
Speech-driven gesture generation is an emerging domain within virtual human creation, where current methods predominantly utilize Transformer-based architectures that necessitate extensive memory and are characterized by slow inference speeds. In response to these limitations, we propose \textit{DiM-Gestures}, a novel end-to-end generative model crafted to create highly personalized 3D full-body gestures solely from raw speech audio, employing Mamba-based architectures. This model integrates a Mamba-based fuzzy feature extractor with a non-autoregressive Adaptive Layer Normalization (AdaLN) Mamba-2 diffusion architecture. The extractor, leveraging a Mamba framework and a WavLM pre-trained model, autonomously derives implicit, continuous fuzzy features, which are then unified into a singular latent feature. This feature is processed by the AdaLN Mamba-2, which implements a uniform conditional mechanism across all tokens to robustly model the interplay between the fuzzy features and the resultant gesture sequence. This innovative approach guarantees high fidelity in gesture-speech synchronization while maintaining the naturalness of the gestures. Employing a diffusion model for training and inference, our framework has undergone extensive subjective and objective evaluations on the ZEGGS and BEAT datasets. These assessments substantiate our model's enhanced performance relative to contemporary state-of-the-art methods, demonstrating competitive outcomes with the DiTs architecture (Persona-Gestors) while optimizing memory usage and accelerating inference speed.
MMTrail: A Multimodal Trailer Video Dataset with Language and Music Descriptions
Jul 30, 2024



Massive multi-modality datasets play a significant role in facilitating the success of large video-language models. However, current video-language datasets primarily provide text descriptions for visual frames, considering audio to be weakly related information. They usually overlook exploring the potential of inherent audio-visual correlation, leading to monotonous annotation within each modality instead of comprehensive and precise descriptions. Such ignorance results in the difficulty of multiple cross-modality studies. To fulfill this gap, we present MMTrail, a large-scale multi-modality video-language dataset incorporating more than 20M trailer clips with visual captions, and 2M high-quality clips with multimodal captions. Trailers preview full-length video works and integrate context, visual frames, and background music. In particular, the trailer has two main advantages: (1) the topics are diverse, and the content characters are of various types, e.g., film, news, and gaming. (2) the corresponding background music is custom-designed, making it more coherent with the visual context. Upon these insights, we propose a systemic captioning framework, achieving various modality annotations with more than 27.1k hours of trailer videos. Here, to ensure the caption retains music perspective while preserving the authority of visual context, we leverage the advanced LLM to merge all annotations adaptively. In this fashion, our MMtrail dataset potentially paves the path for fine-grained large multimodal-language model training. In experiments, we provide evaluation metrics and benchmark results on our dataset, demonstrating the high quality of our annotation and its effectiveness for model training.
Decomposing the Neurons: Activation Sparsity via Mixture of Experts for Continual Test Time Adaptation
May 26, 2024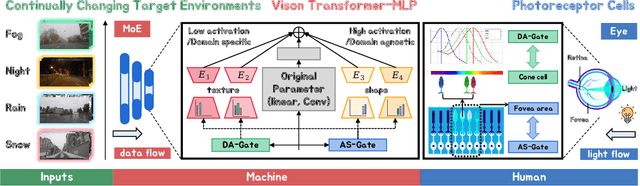
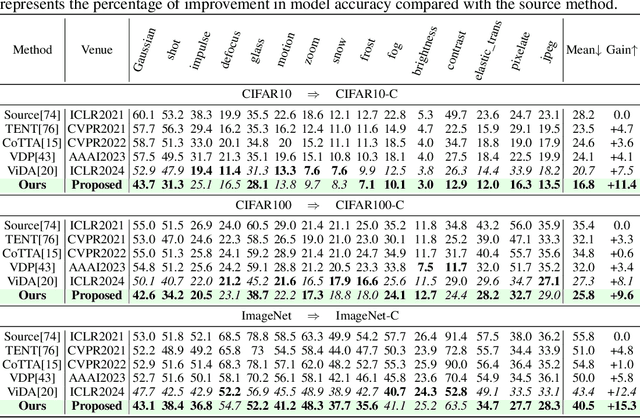

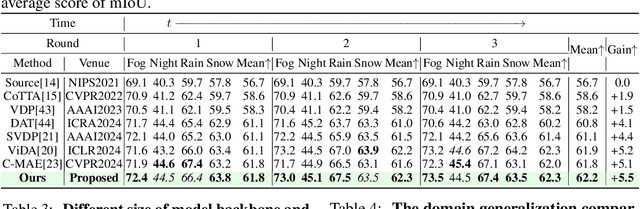
Continual Test-Time Adaptation (CTTA), which aims to adapt the pre-trained model to ever-evolving target domains, emerges as an important task for vision models. As current vision models appear to be heavily biased towards texture, continuously adapting the model from one domain distribution to another can result in serious catastrophic forgetting. Drawing inspiration from the human visual system's adeptness at processing both shape and texture according to the famous Trichromatic Theory, we explore the integration of a Mixture-of-Activation-Sparsity-Experts (MoASE) as an adapter for the CTTA task. Given the distinct reaction of neurons with low/high activation to domain-specific/agnostic features, MoASE decomposes the neural activation into high-activation and low-activation components with a non-differentiable Spatial Differentiate Dropout (SDD). Based on the decomposition, we devise a multi-gate structure comprising a Domain-Aware Gate (DAG) that utilizes domain information to adaptive combine experts that process the post-SDD sparse activations of different strengths, and the Activation Sparsity Gate (ASG) that adaptively assigned feature selection threshold of the SDD for different experts for more precise feature decomposition. Finally, we introduce a Homeostatic-Proximal (HP) loss to bypass the error accumulation problem when continuously adapting the model. Extensive experiments on four prominent benchmarks substantiate that our methodology achieves state-of-the-art performance in both classification and segmentation CTTA tasks. Our code is now available at https://github.com/RoyZry98/MoASE-Pytorch.
Leveraging LLMs for KPIs Retrieval from Hybrid Long-Document: A Comprehensive Framework and Dataset
May 24, 2023Large Language Models (LLMs) demonstrate exceptional performance in textual understanding and tabular reasoning tasks. However, their ability to comprehend and analyze hybrid text, containing textual and tabular data, remains underexplored. In this research, we specialize in harnessing the potential of LLMs to comprehend critical information from financial reports, which are hybrid long-documents. We propose an Automated Financial Information Extraction (AFIE) framework that enhances LLMs' ability to comprehend and extract information from financial reports. To evaluate AFIE, we develop a Financial Reports Numerical Extraction (FINE) dataset and conduct an extensive experimental analysis. Our framework is effectively validated on GPT-3.5 and GPT-4, yielding average accuracy increases of 53.94% and 33.77%, respectively, compared to a naive method. These results suggest that the AFIE framework offers accuracy for automated numerical extraction from complex, hybrid documents.