 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadIR: A Scalable Framework for Multi-Grained Medical Image Retrieval via Radiology Report Mining
Mar 06, 2025Developing advanced medical imaging retrieval systems is challenging due to the varying definitions of `similar images' across different medical contexts. This challenge is compounded by the lack of large-scale, high-quality medical imaging retrieval datasets and benchmarks. In this paper, we propose a novel methodology that leverages dense radiology reports to define image-wise similarity ordering at multiple granularities in a scalable and fully automatic manner. Using this approach, we construct two comprehensive medical imaging retrieval datasets: MIMIC-IR for Chest X-rays and CTRATE-IR for CT scans, providing detailed image-image ranking annotations conditioned on diverse anatomical structures. Furthermore, we develop two retrieval systems, RadIR-CXR and model-ChestCT, which demonstrate superior performance in traditional image-image and image-report retrieval tasks. These systems also enable flexible, effective image retrieval conditioned on specific anatomical structures described in text, achieving state-of-the-art results on 77 out of 78 metrics.
First Place Solution to the ECCV 2024 ROAD++ Challenge @ ROAD++ Atomic Activity Recognition 2024
Oct 30, 2024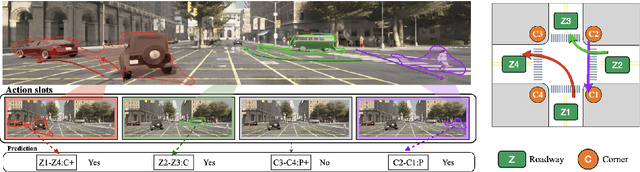



This report presents our team's technical solution for participating in Track 3 of the 2024 ECCV ROAD++ Challenge. The task of Track 3 is atomic activity recognition, which aims to identify 64 types of atomic activities in road scenes based on video content. Our approach primarily addresses the challenges of small objects, discriminating between single object and a group of objects, as well as model overfitting in this task. Firstly, we construct a multi-branch activity recognition framework that not only separates different object categories but also the tasks of single object and object group recognition, thereby enhancing recognition accuracy. Subsequently, we develop various model ensembling strategies, including integrations of multiple frame sampling sequences, different frame sampling sequence lengths, multiple training epochs, and different backbone networks. Furthermore, we propose an atomic activity recognition data augmentation method, which greatly expands the sample space by flipping video frames and road topology, effectively mitigating model overfitting. Our methods rank first in the test set of Track 3 for the ROAD++ Challenge 2024, and achieve 69% mAP.
Scale-free Network-based Differential Evolution
Jan 27, 2021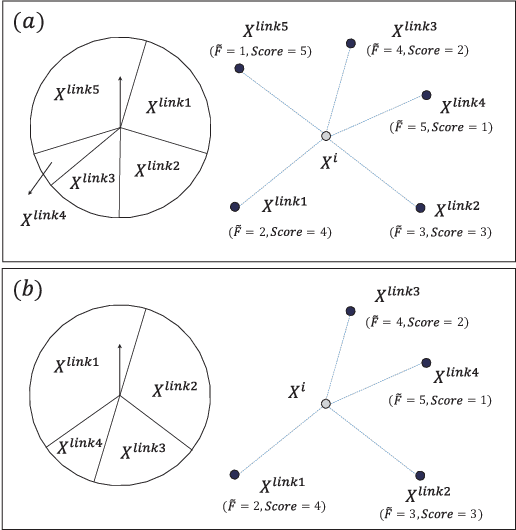
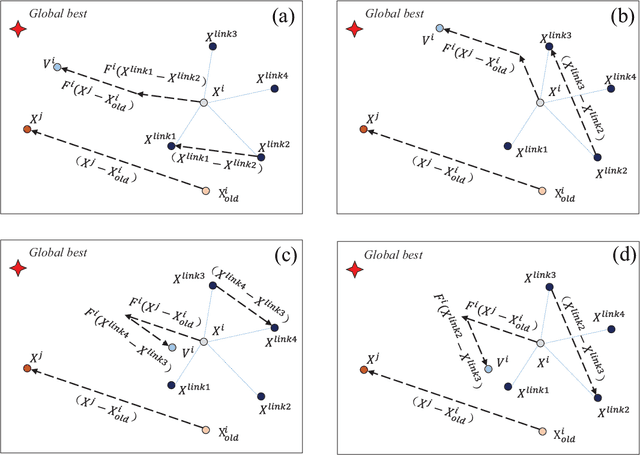
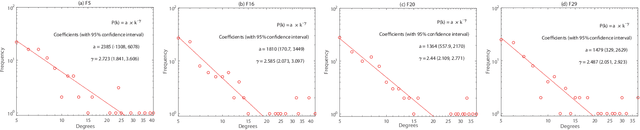
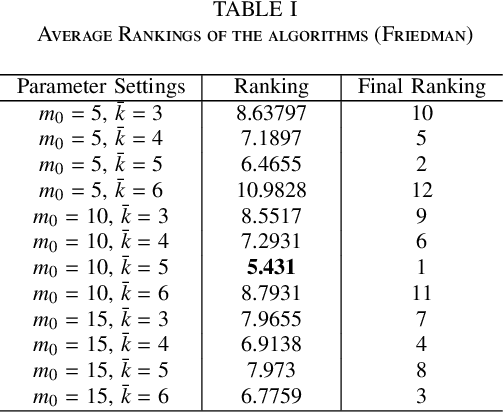
Some recent research reveals that a topological structure in meta-heuristic algorithms can effectively enhance the interaction of population, and thus improve their performance. Inspired by it, we creatively investigate the effectiveness of using a scale-free network in differential evolution methods, and propose a scale-free network-based differential evolution method. The novelties of this paper include a scale-free network-based population structure and a new mutation operator designed to fully utilize the neighborhood information provided by a scale-free structure. The elite individuals and population at the latest generation are both employed to guide a global optimization process. In this manner, the proposed algorithm owns balanced exploration and exploitation capabilities to alleviate the drawbacks of premature convergence. Experimental and statistical analyses are performed on the CEC'17 benchmark function suite and three real world problems. Results demonstrate its superior effectiveness and efficiency in comparison with its competitive peers.
Synergy between Machine/Deep Learning and Software Engineering: How Far Are We?
Aug 12, 2020


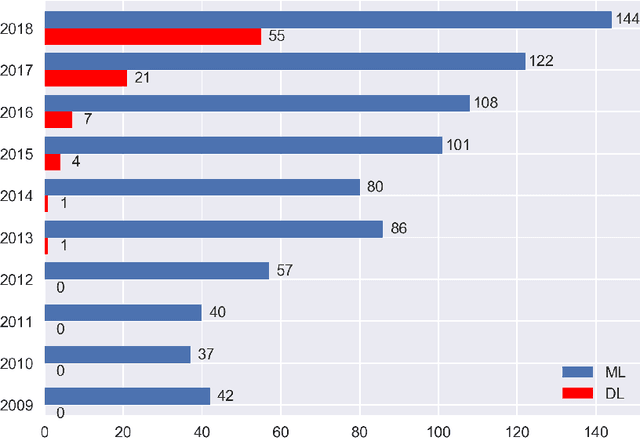
Since 2009, the deep learning revolution, which was triggered by the introduction of ImageNet, has stimulated the synergy between Machine Learning (ML)/Deep Learning (DL) and Software Engineering (SE). Meanwhile, critical reviews have emerged that suggest that ML/DL should be used cautiously. To improve the quality (especially the applicability and generalizability) of ML/DL-related SE studies, and to stimulate and enhance future collaborations between SE/AI researchers and industry practitioners, we conducted a 10-year Systematic Literature Review (SLR) on 906 ML/DL-related SE papers published between 2009 and 2018. Our trend analysis demonstrated the mutual impacts that ML/DL and SE have had on each other. At the same time, however, we also observed a paucity of replicable and reproducible ML/DL-related SE studies and identified five factors that influence their replicability and reproducibility. To improve the applicability and generalizability of research results, we analyzed what ingredients in a study would facilitate an understanding of why a ML/DL technique was selected for a specific SE problem. In addition, we identified the unique trends of impacts of DL models on SE tasks, as well as five unique challenges that needed to be met in order to better leverage DL to improve the productivity of SE tasks. Finally, we outlined a road-map that we believe can facilitate the transfer of ML/DL-based SE research results into real-world industry practices.
Comparison Network for One-Shot Conditional Object Detection
Apr 04, 2019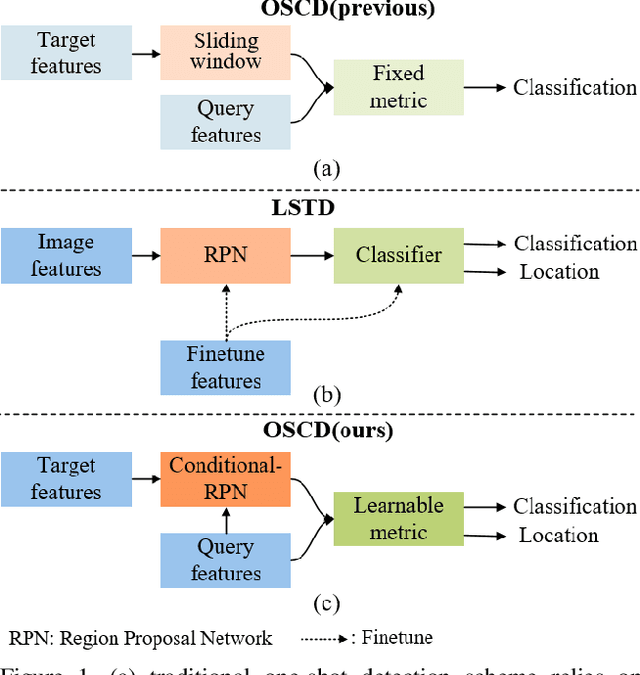
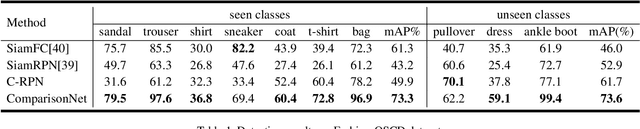

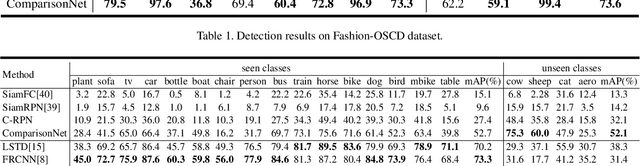
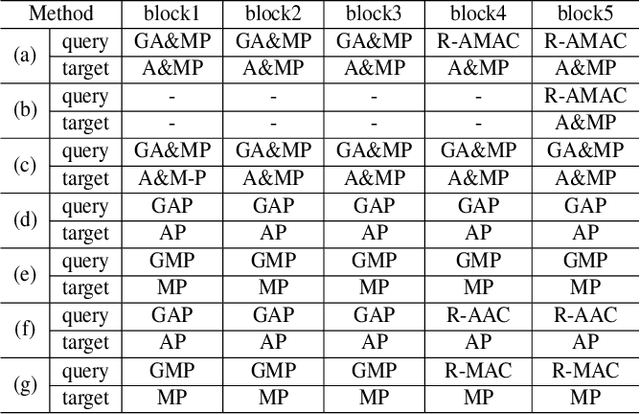
The current advances in object detection depend on large-scale datasets to get good performance. However, there may not always be sufficient samples in many scenarios, which leads to the research on few-shot detection as well as its extreme variation one-shot detection. In this paper, the one-shot detection has been formulated as a conditional probability problem. With this insight, a novel one-shot conditional object detection (OSCD) framework, referred as Comparison Network (ComparisonNet), has been proposed. Specifically, query and target image features are extracted through a Siamese network as mapped metrics of marginal probabilities. A two-stage detector for OSCD is introduced to compare the extracted query and target features with the learnable metric to approach the optimized non-linear conditional probability. Once trained, ComparisonNet can detect objects of both seen and unseen classes without further training, which also has the advantages including class-agnostic, training-free for unseen classes, and without catastrophic forgetting. Experiments show that the proposed approach achieves state-of-the-art performance on the proposed datasets of Fashion-MNIST and PASCAL VOC.
A Training-free, One-shot Detection Framework For Geospatial Objects In Remote Sensing Images
Apr 04, 2019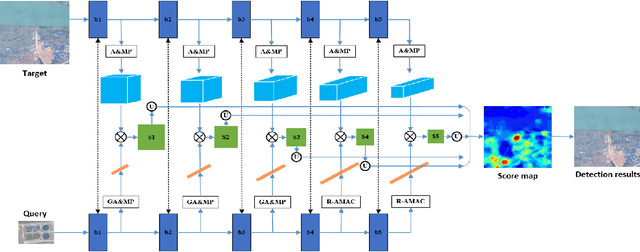
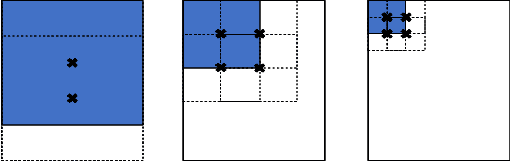
Deep learning based object detection has achieved great success. However, these supervised learning methods are data-hungry and time-consuming. This restriction makes them unsuitable for limited data and urgent tasks, especially in the applications of remote sensing. Inspired by the ability of humans to quickly learn new visual concepts from very few examples, we propose a training-free, one-shot geospatial object detection framework for remote sensing images. It consists of (1) a feature extractor with remote sensing domain knowledge, (2) a multi-level feature fusion method, (3) a novel similarity metric method, and (4) a 2-stage object detection pipeline. Experiments on sewage treatment plant and airport detections show that proposed method has achieved a certain effect. Our method can serve as a baseline for training-free, one-shot geospatial object detection.
R2CNN++: Multi-Dimensional Attention Based Rotation Invariant Detector with Robust Anchor Strategy
Nov 20, 2018
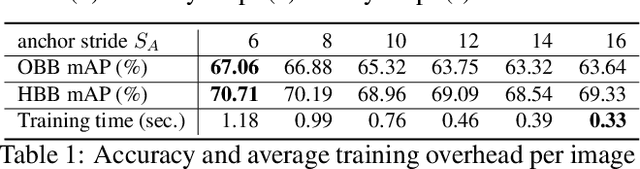
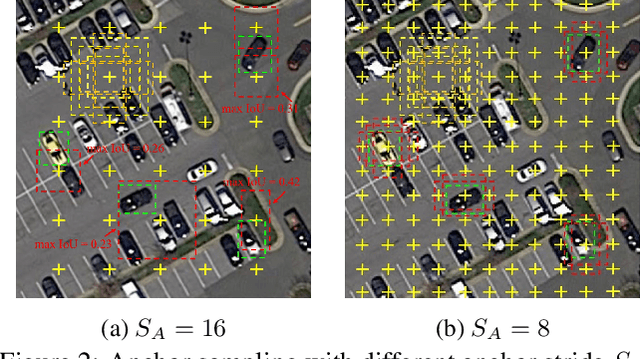
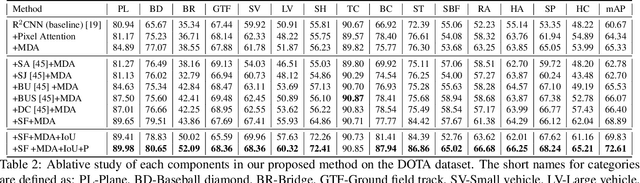
Object detection plays a vital role in natural scene and aerial scene and is full of challenges. Although many advanced algorithms have succeeded in the natural scene, the progress in the aerial scene has been slow due to the complexity of the aerial image and the large degree of freedom of remote sensing objects in scale, orientation, and density. In this paper, a novel multi-category rotation detector is proposed, which can efficiently detect small objects, arbitrary direction objects, and dense objects in complex remote sensing images. Specifically, the proposed model adopts a targeted feature fusion strategy called inception fusion network, which fully considers factors such as feature fusion, anchor sampling, and receptive field to improve the ability to handle small objects. Then we combine the pixel attention network and the channel attention network to weaken the noise information and highlight the objects feature. Finally, the rotational object detection algorithm is realized by redefining the rotating bounding box. Experiments on public datasets including DOTA, NWPU VHR-10 demonstrate that the proposed algorithm significantly outperforms state-of-the-art methods. The code and models will be available at https://github.com/DetectionTeamUCAS/R2CNN-Plus-Plus_Tensorflow.