 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePurification Before Fusion: Toward Mask-Free Speech Enhancement for Robust Audio-Visual Speech Recognition
Jan 18, 2026Audio-visual speech recognition (AVSR) typically improves recognition accuracy in noisy environments by integrating noise-immune visual cues with audio signals. Nevertheless, high-noise audio inputs are prone to introducing adverse interference into the feature fusion process. To mitigate this, recent AVSR methods often adopt mask-based strategies to filter audio noise during feature interaction and fusion, yet such methods risk discarding semantically relevant information alongside noise. In this work, we propose an end-to-end noise-robust AVSR framework coupled with speech enhancement, eliminating the need for explicit noise mask generation. This framework leverages a Conformer-based bottleneck fusion module to implicitly refine noisy audio features with video assistance. By reducing modality redundancy and enhancing inter-modal interactions, our method preserves speech semantic integrity to achieve robust recognition performance. Experimental evaluations on the public LRS3 benchmark suggest that our method outperforms prior advanced mask-based baselines under noisy conditions.
First Place Solution to the ECCV 2024 ROAD++ Challenge @ ROAD++ Atomic Activity Recognition 2024
Oct 30, 2024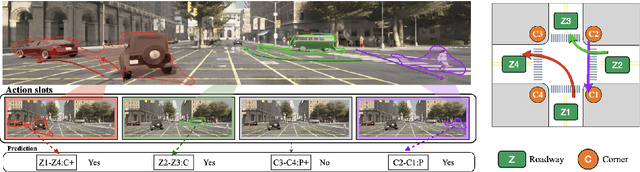



This report presents our team's technical solution for participating in Track 3 of the 2024 ECCV ROAD++ Challenge. The task of Track 3 is atomic activity recognition, which aims to identify 64 types of atomic activities in road scenes based on video content. Our approach primarily addresses the challenges of small objects, discriminating between single object and a group of objects, as well as model overfitting in this task. Firstly, we construct a multi-branch activity recognition framework that not only separates different object categories but also the tasks of single object and object group recognition, thereby enhancing recognition accuracy. Subsequently, we develop various model ensembling strategies, including integrations of multiple frame sampling sequences, different frame sampling sequence lengths, multiple training epochs, and different backbone networks. Furthermore, we propose an atomic activity recognition data augmentation method, which greatly expands the sample space by flipping video frames and road topology, effectively mitigating model overfitting. Our methods rank first in the test set of Track 3 for the ROAD++ Challenge 2024, and achieve 69% mAP.
Landmark-Guided Cross-Speaker Lip Reading with Mutual Information Regularization
Mar 24, 2024



Lip reading, the process of interpreting silent speech from visual lip movements, has gained rising attention for its wide range of realistic applications. Deep learning approaches greatly improve current lip reading systems. However, lip reading in cross-speaker scenarios where the speaker identity changes, poses a challenging problem due to inter-speaker variability. A well-trained lip reading system may perform poorly when handling a brand new speaker. To learn a speaker-robust lip reading model, a key insight is to reduce visual variations across speakers, avoiding the model overfitting to specific speakers. In this work, in view of both input visual clues and latent representations based on a hybrid CTC/attention architecture, we propose to exploit the lip landmark-guided fine-grained visual clues instead of frequently-used mouth-cropped images as input features, diminishing speaker-specific appearance characteristics. Furthermore, a max-min mutual information regularization approach is proposed to capture speaker-insensitive latent representations. Experimental evaluations on public lip reading datasets demonstrate the effectiveness of the proposed approach under the intra-speaker and inter-speaker conditions.
* To appear in LREC-COLING 2024
Real-Aug: Realistic Scene Synthesis for LiDAR Augmentation in 3D Object Detection
May 22, 2023Data and model are the undoubtable two supporting pillars for LiDAR object detection. However, data-centric works have fallen far behind compared with the ever-growing list of fancy new models. In this work, we systematically study the synthesis-based LiDAR data augmentation approach (so-called GT-Aug) which offers maxium controllability over generated data samples. We pinpoint the main shortcoming of existing works is introducing unrealistic LiDAR scan patterns during GT-Aug. In light of this finding, we propose Real-Aug, a synthesis-based augmentation method which prioritizes on generating realistic LiDAR scans. Our method consists a reality-conforming scene composition module which handles the details of the composition and a real-synthesis mixing up training strategy which gradually adapts the data distribution from synthetic data to the real one. To verify the effectiveness of our methods, we conduct extensive ablation studies and validate the proposed Real-Aug on a wide combination of detectors and datasets. We achieve a state-of-the-art 0.744 NDS and 0.702 mAP on nuScenes test set. The code shall be released soon.