 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePurification Before Fusion: Toward Mask-Free Speech Enhancement for Robust Audio-Visual Speech Recognition
Jan 18, 2026Audio-visual speech recognition (AVSR) typically improves recognition accuracy in noisy environments by integrating noise-immune visual cues with audio signals. Nevertheless, high-noise audio inputs are prone to introducing adverse interference into the feature fusion process. To mitigate this, recent AVSR methods often adopt mask-based strategies to filter audio noise during feature interaction and fusion, yet such methods risk discarding semantically relevant information alongside noise. In this work, we propose an end-to-end noise-robust AVSR framework coupled with speech enhancement, eliminating the need for explicit noise mask generation. This framework leverages a Conformer-based bottleneck fusion module to implicitly refine noisy audio features with video assistance. By reducing modality redundancy and enhancing inter-modal interactions, our method preserves speech semantic integrity to achieve robust recognition performance. Experimental evaluations on the public LRS3 benchmark suggest that our method outperforms prior advanced mask-based baselines under noisy conditions.
Landmark-Guided Cross-Speaker Lip Reading with Mutual Information Regularization
Mar 24, 2024



Lip reading, the process of interpreting silent speech from visual lip movements, has gained rising attention for its wide range of realistic applications. Deep learning approaches greatly improve current lip reading systems. However, lip reading in cross-speaker scenarios where the speaker identity changes, poses a challenging problem due to inter-speaker variability. A well-trained lip reading system may perform poorly when handling a brand new speaker. To learn a speaker-robust lip reading model, a key insight is to reduce visual variations across speakers, avoiding the model overfitting to specific speakers. In this work, in view of both input visual clues and latent representations based on a hybrid CTC/attention architecture, we propose to exploit the lip landmark-guided fine-grained visual clues instead of frequently-used mouth-cropped images as input features, diminishing speaker-specific appearance characteristics. Furthermore, a max-min mutual information regularization approach is proposed to capture speaker-insensitive latent representations. Experimental evaluations on public lip reading datasets demonstrate the effectiveness of the proposed approach under the intra-speaker and inter-speaker conditions.
* To appear in LREC-COLING 2024
Adaptive End-to-End Metric Learning for Zero-Shot Cross-Domain Slot Filling
Oct 23, 2023



Recently slot filling has witnessed great development thanks to deep learning and the availability of large-scale annotated data. However, it poses a critical challenge to handle a novel domain whose samples are never seen during training. The recognition performance might be greatly degraded due to severe domain shifts. Most prior works deal with this problem in a two-pass pipeline manner based on metric learning. In practice, these dominant pipeline models may be limited in computational efficiency and generalization capacity because of non-parallel inference and context-free discrete label embeddings. To this end, we re-examine the typical metric-based methods, and propose a new adaptive end-to-end metric learning scheme for the challenging zero-shot slot filling. Considering simplicity, efficiency and generalizability, we present a cascade-style joint learning framework coupled with context-aware soft label representations and slot-level contrastive representation learning to mitigate the data and label shift problems effectively. Extensive experiments on public benchmarks demonstrate the superiority of the proposed approach over a series of competitive baselines.
Robust Self-Augmentation for Named Entity Recognition with Meta Reweighting
May 02, 2022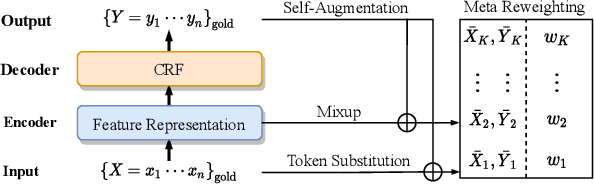
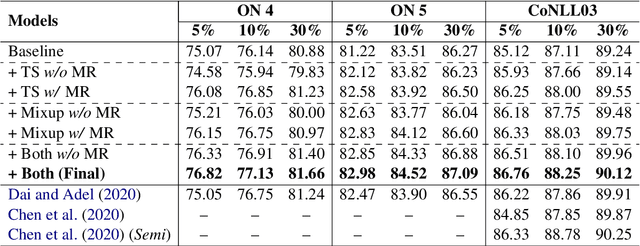
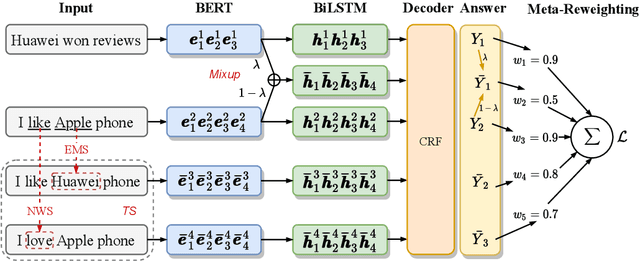
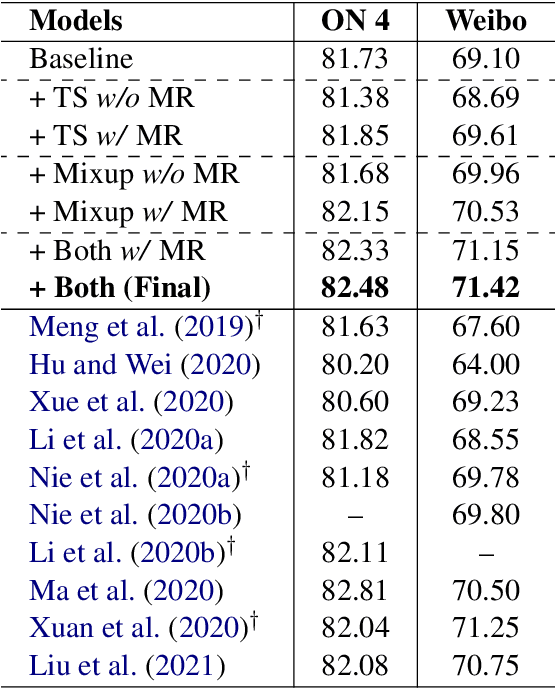
Self-augmentation has received increasing research interest recently to improve named entity recognition (NER) performance in low-resource scenarios. Token substitution and mixup are two feasible heterogeneous self-augmentation techniques for NER that can achieve effective performance with certain specialized efforts. Noticeably, self-augmentation may introduce potentially noisy augmented data. Prior research has mainly resorted to heuristic rule-based constraints to reduce the noise for specific self-augmentation methods individually. In this paper, we revisit these two typical self-augmentation methods for NER, and propose a unified meta-reweighting strategy for them to achieve a natural integration. Our method is easily extensible, imposing little effort on a specific self-augmentation method. Experiments on different Chinese and English NER benchmarks show that our token substitution and mixup method, as well as their integration, can achieve effective performance improvement. Based on the meta-reweighting mechanism, we can enhance the advantages of the self-augmentation techniques without much extra effort.