 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive End-to-End Metric Learning for Zero-Shot Cross-Domain Slot Filling
Oct 23, 2023Recently slot filling has witnessed great development thanks to deep learning and the availability of large-scale annotated data. However, it poses a critical challenge to handle a novel domain whose samples are never seen during training. The recognition performance might be greatly degraded due to severe domain shifts. Most prior works deal with this problem in a two-pass pipeline manner based on metric learning. In practice, these dominant pipeline models may be limited in computational efficiency and generalization capacity because of non-parallel inference and context-free discrete label embeddings. To this end, we re-examine the typical metric-based methods, and propose a new adaptive end-to-end metric learning scheme for the challenging zero-shot slot filling. Considering simplicity, efficiency and generalizability, we present a cascade-style joint learning framework coupled with context-aware soft label representations and slot-level contrastive representation learning to mitigate the data and label shift problems effectively. Extensive experiments on public benchmarks demonstrate the superiority of the proposed approach over a series of competitive baselines.
Hyperbolic Self-supervised Contrastive Learning Based Network Anomaly Detection
Sep 12, 2022
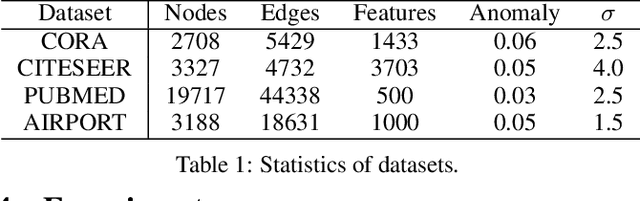
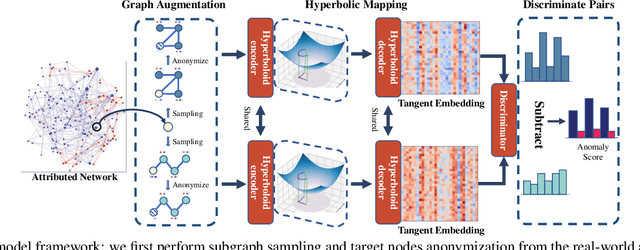

Anomaly detection on the attributed network has recently received increasing attention in many research fields, such as cybernetic anomaly detection and financial fraud detection. With the wide application of deep learning on graph representations, existing approaches choose to apply euclidean graph encoders as their backbone, which may lose important hierarchical information, especially in complex networks. To tackle this problem, we propose an efficient anomaly detection framework using hyperbolic self-supervised contrastive learning. Specifically, we first conduct the data augmentation by performing subgraph sampling. Then we utilize the hierarchical information in hyperbolic space through exponential mapping and logarithmic mapping and obtain the anomaly score by subtracting scores of the positive pairs from the negative pairs via a discriminating process. Finally, extensive experiments on four real-world datasets demonstrate that our approach performs superior over representative baseline approaches.