 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Distributed Hierarchical Spatio-Temporal Edge-Enhanced Graph Neural Network for City-Scale Dynamic Logistics Routing
Dec 20, 2025City-scale logistics routing has become increasingly challenging as metropolitan road networks grow to tens of millions of edges and traffic conditions evolve rapidly under high-volume mobility demands. Conventional centralized routing algorithms and monolithic graph neural network (GNN) models suffer from limited scalability, high latency, and poor real-time adaptability, which restricts their effectiveness in large urban logistics systems. To address these challenges, this paper proposes a Distributed Hierarchical Spatio-Temporal Edge-Enhanced Graph Neural Network (HSTE-GNN) for dynamic routing over ultra-large road networks. The framework partitions the city-scale graph into regional subgraphs processed in parallel across distributed computing nodes, enabling efficient learning of localized traffic dynamics. Within each region, an edge-enhanced spatio-temporal module jointly models node states, dynamic edge attributes, and short-term temporal dependencies. A hierarchical coordination layer further aggregates cross-region representations through an asynchronous parameter-server mechanism, ensuring global routing coherence under high-frequency traffic updates. This distributed hierarchical design balances local responsiveness with global consistency, significantly improving scalability and inference efficiency. Experiments on real-world large-scale traffic datasets from Beijing and New York demonstrate that HSTE-GNN outperforms strong spatio-temporal baselines such as ST-GRAPH, achieving 34.9% lower routing delay, 14.7% lower MAPE, and 11.8% lower RMSE, while improving global route consistency by 7.3%. These results confirm that the proposed framework provides a scalable, adaptive, and efficient solution for next-generation intelligent transportation systems and large-scale logistics platforms.
Fault Diagnosis and Quantification for Photovoltaic Arrays based on Differentiable Physical Models
Dec 18, 2025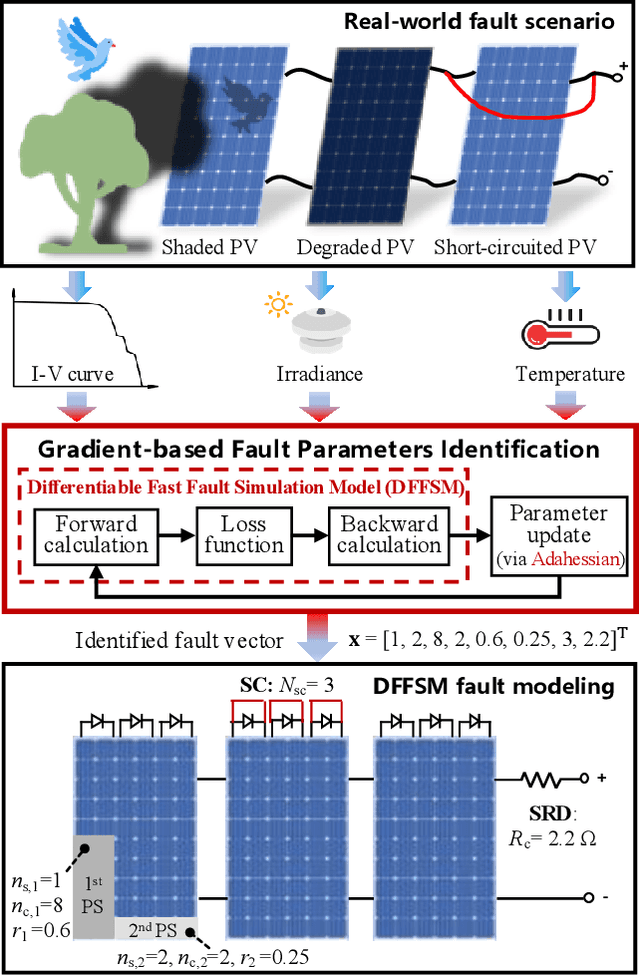
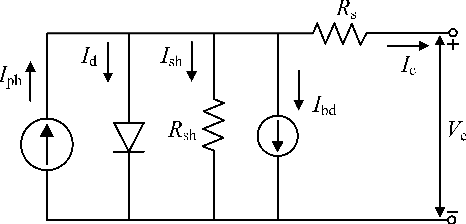
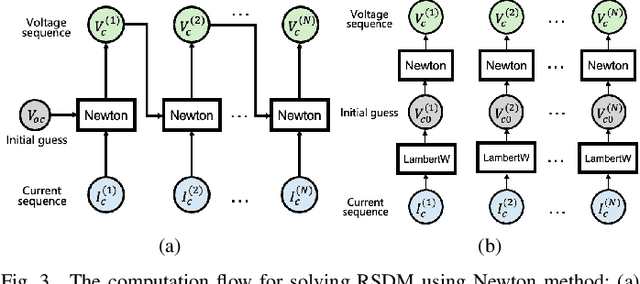
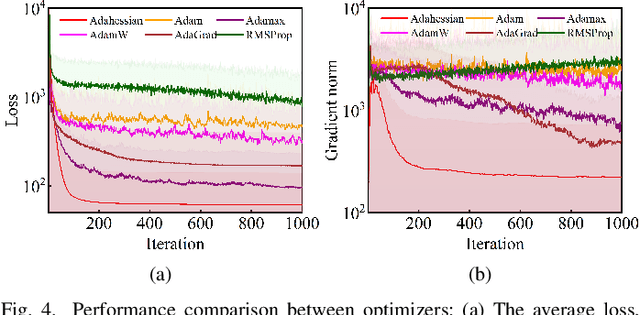
Accurate fault diagnosis and quantification are essential for the reliable operation and intelligent maintenance of photovoltaic (PV) arrays. However, existing fault quantification methods often suffer from limited efficiency and interpretability. To address these challenges, this paper proposes a novel fault quantification approach for PV strings based on a differentiable fast fault simulation model (DFFSM). The proposed DFFSM accurately models I-V characteristics under multiple faults and provides analytical gradients with respect to fault parameters. Leveraging this property, a gradient-based fault parameters identification (GFPI) method using the Adahessian optimizer is developed to efficiently quantify partial shading, short-circuit, and series-resistance degradation. Experimental results on both simulated and measured I-V curves demonstrate that the proposed GFPI achieves high quantification accuracy across different faults, with the I-V reconstruction error below 3%, confirming the feasibility and effectiveness of the application of differentiable physical simulators for PV system fault diagnosis.
Fusing Cross-modal and Uni-modal Representations: A Kronecker Product Approach
Jun 10, 2025Cross-modal embeddings, such as CLIP, BLIP and their variants, have achieved promising results in aligning representations across modalities. However, these embeddings could underperform compared to state-of-the-art single-modality embeddings on modality-specific tasks. On the other hand, single-modality embeddings excel in their domains but lack cross-modal alignment capabilities. In this work, we focus on the problem of unifying cross-modality and single-modality embeddings to achieve the performance of modality-expert embedding within individual modalities while preserving cross-modal alignment. To this end, we propose RP-KrossFuse, a method that leverages a random projection-based Kronecker product to integrate cross-modal embeddings with single-modality embeddings. RP-KrossFuse aims to fuse the sample-pairwise similarity scores of the fused embeddings and operates efficiently in a specified kernel space and supports scalable implementations via random Fourier features for shift-invariant kernels such as the Gaussian kernel. We demonstrate the effectiveness of RP-KrossFuse through several numerical experiments, combining CLIP embeddings with uni-modal image and text embeddings. Our numerical results indicate that RP-KrossFuse achieves competitive modality-specific performance while retaining cross-modal alignment, bridging the gap between cross-modal and single-modality embeddings.
GeoMaNO: Geometric Mamba Neural Operator for Partial Differential Equations
May 17, 2025The neural operator (NO) framework has emerged as a powerful tool for solving partial differential equations (PDEs). Recent NOs are dominated by the Transformer architecture, which offers NOs the capability to capture long-range dependencies in PDE dynamics. However, existing Transformer-based NOs suffer from quadratic complexity, lack geometric rigor, and thus suffer from sub-optimal performance on regular grids. As a remedy, we propose the Geometric Mamba Neural Operator (GeoMaNO) framework, which empowers NOs with Mamba's modeling capability, linear complexity, plus geometric rigor. We evaluate GeoMaNO's performance on multiple standard and popularly employed PDE benchmarks, spanning from Darcy flow problems to Navier-Stokes problems. GeoMaNO improves existing baselines in solution operator approximation by as much as 58.9%.
CATCH-FORM-ACTer: Compliance-Aware Tactile Control and Hybrid Deformation Regulation-Based Action Transformer for Viscoelastic Object Manipulation
Apr 11, 2025



Automating contact-rich manipulation of viscoelastic objects with rigid robots faces challenges including dynamic parameter mismatches, unstable contact oscillations, and spatiotemporal force-deformation coupling. In our prior work, a Compliance-Aware Tactile Control and Hybrid Deformation Regulation (CATCH-FORM-3D) strategy fulfills robust and effective manipulations of 3D viscoelastic objects, which combines a contact force-driven admittance outer loop and a PDE-stabilized inner loop, achieving sub-millimeter surface deformation accuracy. However, this strategy requires fine-tuning of object-specific parameters and task-specific calibrations, to bridge this gap, a CATCH-FORM-ACTer is proposed, by enhancing CATCH-FORM-3D with a framework of Action Chunking with Transformer (ACT). An intuitive teleoperation system performs Learning from Demonstration (LfD) to build up a long-horizon sensing, decision-making and execution sequences. Unlike conventional ACT methods focused solely on trajectory planning, our approach dynamically adjusts stiffness, damping, and diffusion parameters in real time during multi-phase manipulations, effectively imitating human-like force-deformation modulation. Experiments on single arm/bimanual robots in three tasks show better force fields patterns and thus 10%-20% higher success rates versus conventional methods, enabling precise, safe interactions for industrial, medical or household scenarios.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
SeizeIT2: Wearable Dataset Of Patients With Focal Epilepsy
Feb 03, 2025



The increasing technological advancements towards miniaturized physiological measuring devices have enabled continuous monitoring of epileptic patients outside of specialized environments. The large amounts of data that can be recorded with such devices holds significant potential for developing automated seizure detection frameworks. In this work, we present SeizeIT2, the first open dataset of wearable data recorded in patients with focal epilepsy. The dataset comprises more than 11,000 hours of multimodal data, including behind-the-ear electroencephalography, electrocardiography, electromyography and movement (accelerometer and gyroscope) data. The dataset contains 886 focal seizures recorded from 125 patients across five different European Epileptic Monitoring Centers. We present a suggestive training/validation split to propel the development of AI methodologies for seizure detection, as well as two benchmark approaches and evaluation metrics. The dataset can be accessed on OpenNeuro and is stored in Brain Imaging Data Structure (BIDS) format.
A Super-pixel-based Approach to the Stable Interpretation of Neural Networks
Dec 19, 2024



Saliency maps are widely used in the computer vision community for interpreting neural network classifiers. However, due to the randomness of training samples and optimization algorithms, the resulting saliency maps suffer from a significant level of stochasticity, making it difficult for domain experts to capture the intrinsic factors that influence the neural network's decision. In this work, we propose a novel pixel partitioning strategy to boost the stability and generalizability of gradient-based saliency maps. Through both theoretical analysis and numerical experiments, we demonstrate that the grouping of pixels reduces the variance of the saliency map and improves the generalization behavior of the interpretation method. Furthermore, we propose a sensible grouping strategy based on super-pixels which cluster pixels into groups that align well with the semantic meaning of the images. We perform several numerical experiments on CIFAR-10 and ImageNet. Our empirical results suggest that the super-pixel-based interpretation maps consistently improve the stability and quality over the pixel-based saliency maps.
2DMamba: Efficient State Space Model for Image Representation with Applications on Giga-Pixel Whole Slide Image Classification
Dec 01, 2024Efficiently modeling large 2D contexts is essential for various fields including Giga-Pixel Whole Slide Imaging (WSI) and remote sensing. Transformer-based models offer high parallelism but face challenges due to their quadratic complexity for handling long sequences. Recently, Mamba introduced a selective State Space Model (SSM) with linear complexity and high parallelism, enabling effective and efficient modeling of wide context in 1D sequences. However, extending Mamba to vision tasks, which inherently involve 2D structures, results in spatial discrepancies due to the limitations of 1D sequence processing. On the other hand, current 2D SSMs inherently model 2D structures but they suffer from prohibitively slow computation due to the lack of efficient parallel algorithms. In this work, we propose 2DMamba, a novel 2D selective SSM framework that incorporates the 2D spatial structure of images into Mamba, with a highly optimized hardware-aware operator, adopting both spatial continuity and computational efficiency. We validate the versatility of our approach on both WSIs and natural images. Extensive experiments on 10 public datasets for WSI classification and survival analysis show that 2DMamba~improves up to $2.48\%$ in AUC, $3.11\%$ in F1 score, $2.47\%$ in accuracy and $5.52\%$ in C-index. Additionally, integrating our method with VMamba for natural imaging yields $0.5$ to $0.7$ improvements in mIoU on the ADE20k semantic segmentation dataset, and $0.2\%$ accuracy improvement on ImageNet-1K classification dataset. Our code is available at https://github.com/AtlasAnalyticsLab/2DMamba.
Game On: Towards Language Models as RL Experimenters
Sep 05, 2024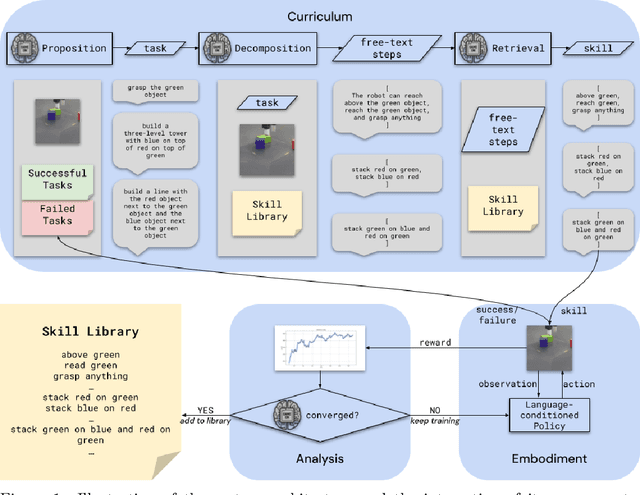

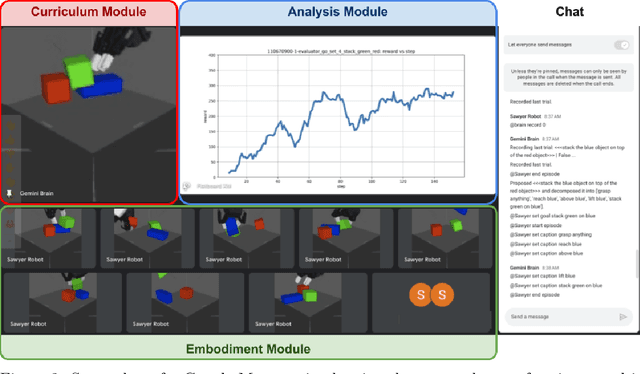
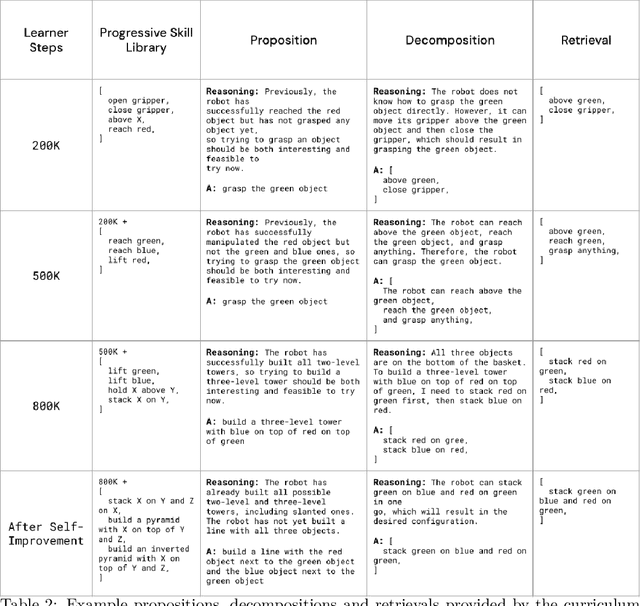
We propose an agent architecture that automates parts of the common reinforcement learning experiment workflow, to enable automated mastery of control domains for embodied agents. To do so, it leverages a VLM to perform some of the capabilities normally required of a human experimenter, including the monitoring and analysis of experiment progress, the proposition of new tasks based on past successes and failures of the agent, decomposing tasks into a sequence of subtasks (skills), and retrieval of the skill to execute - enabling our system to build automated curricula for learning. We believe this is one of the first proposals for a system that leverages a VLM throughout the full experiment cycle of reinforcement learning. We provide a first prototype of this system, and examine the feasibility of current models and techniques for the desired level of automation. For this, we use a standard Gemini model, without additional fine-tuning, to provide a curriculum of skills to a language-conditioned Actor-Critic algorithm, in order to steer data collection so as to aid learning new skills. Data collected in this way is shown to be useful for learning and iteratively improving control policies in a robotics domain. Additional examination of the ability of the system to build a growing library of skills, and to judge the progress of the training of those skills, also shows promising results, suggesting that the proposed architecture provides a potential recipe for fully automated mastery of tasks and domains for embodied agents.