 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAS-Prompt: Large Language Models as Numerical Optimizers for Robot Self-Improvement
Apr 29, 2025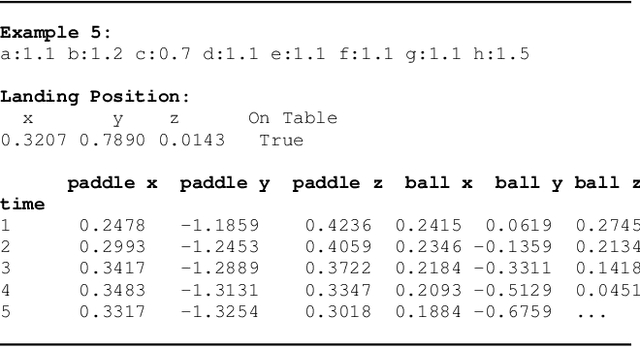

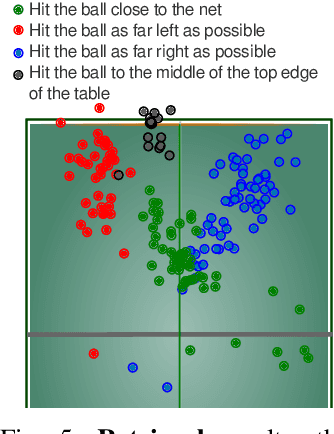

We demonstrate the ability of large language models (LLMs) to perform iterative self-improvement of robot policies. An important insight of this paper is that LLMs have a built-in ability to perform (stochastic) numerical optimization and that this property can be leveraged for explainable robot policy search. Based on this insight, we introduce the SAS Prompt (Summarize, Analyze, Synthesize) -- a single prompt that enables iterative learning and adaptation of robot behavior by combining the LLM's ability to retrieve, reason and optimize over previous robot traces in order to synthesize new, unseen behavior. Our approach can be regarded as an early example of a new family of explainable policy search methods that are entirely implemented within an LLM. We evaluate our approach both in simulation and on a real-robot table tennis task. Project website: sites.google.com/asu.edu/sas-llm/
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Achieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
Robotic Table Tennis: A Case Study into a High Speed Learning System
Sep 06, 2023



We present a deep-dive into a real-world robotic learning system that, in previous work, was shown to be capable of hundreds of table tennis rallies with a human and has the ability to precisely return the ball to desired targets. This system puts together a highly optimized perception subsystem, a high-speed low-latency robot controller, a simulation paradigm that can prevent damage in the real world and also train policies for zero-shot transfer, and automated real world environment resets that enable autonomous training and evaluation on physical robots. We complement a complete system description, including numerous design decisions that are typically not widely disseminated, with a collection of studies that clarify the importance of mitigating various sources of latency, accounting for training and deployment distribution shifts, robustness of the perception system, sensitivity to policy hyper-parameters, and choice of action space. A video demonstrating the components of the system and details of experimental results can be found at https://youtu.be/uFcnWjB42I0.
Agile Catching with Whole-Body MPC and Blackbox Policy Learning
Jun 14, 2023


We address a benchmark task in agile robotics: catching objects thrown at high-speed. This is a challenging task that involves tracking, intercepting, and cradling a thrown object with access only to visual observations of the object and the proprioceptive state of the robot, all within a fraction of a second. We present the relative merits of two fundamentally different solution strategies: (i) Model Predictive Control using accelerated constrained trajectory optimization, and (ii) Reinforcement Learning using zeroth-order optimization. We provide insights into various performance trade-offs including sample efficiency, sim-to-real transfer, robustness to distribution shifts, and whole-body multimodality via extensive on-hardware experiments. We conclude with proposals on fusing "classical" and "learning-based" techniques for agile robot control. Videos of our experiments may be found at https://sites.google.com/view/agile-catching
Learning High Speed Precision Table Tennis on a Physical Robot
Oct 07, 2022
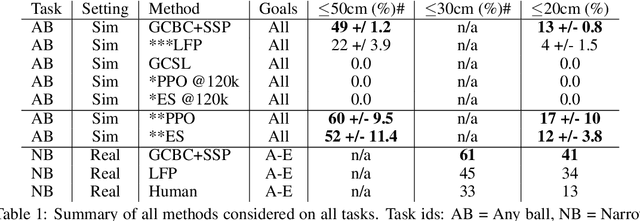
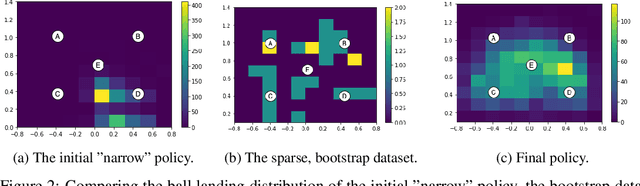
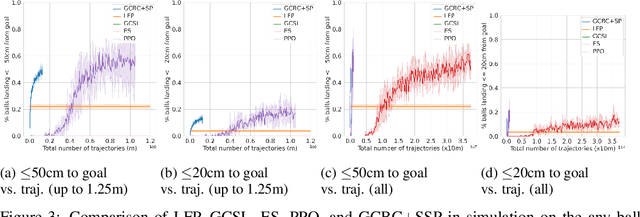
Learning goal conditioned control in the real world is a challenging open problem in robotics. Reinforcement learning systems have the potential to learn autonomously via trial-and-error, but in practice the costs of manual reward design, ensuring safe exploration, and hyperparameter tuning are often enough to preclude real world deployment. Imitation learning approaches, on the other hand, offer a simple way to learn control in the real world, but typically require costly curated demonstration data and lack a mechanism for continuous improvement. Recently, iterative imitation techniques have been shown to learn goal directed control from undirected demonstration data, and improve continuously via self-supervised goal reaching, but results thus far have been limited to simulated environments. In this work, we present evidence that iterative imitation learning can scale to goal-directed behavior on a real robot in a dynamic setting: high speed, precision table tennis (e.g. "land the ball on this particular target"). We find that this approach offers a straightforward way to do continuous on-robot learning, without complexities such as reward design or sim-to-real transfer. It is also scalable -- sample efficient enough to train on a physical robot in just a few hours. In real world evaluations, we find that the resulting policy can perform on par or better than amateur humans (with players sampled randomly from a robotics lab) at the task of returning the ball to specific targets on the table. Finally, we analyze the effect of an initial undirected bootstrap dataset size on performance, finding that a modest amount of unstructured demonstration data provided up-front drastically speeds up the convergence of a general purpose goal-reaching policy. See https://sites.google.com/view/goals-eye for videos.
i-Sim2Real: Reinforcement Learning of Robotic Policies in Tight Human-Robot Interaction Loops
Jul 14, 2022
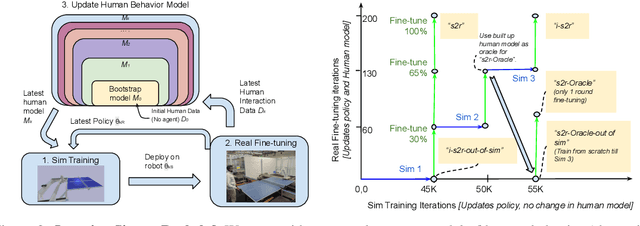
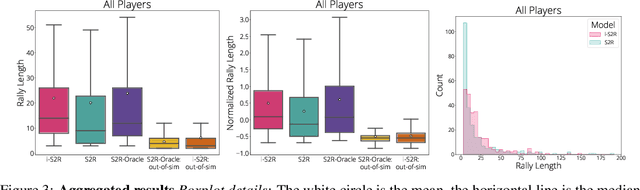
Sim-to-real transfer is a powerful paradigm for robotic reinforcement learning. The ability to train policies in simulation enables safe exploration and large-scale data collection quickly at low cost. However, prior works in sim-to-real transfer of robotic policies typically do not involve any human-robot interaction because accurately simulating human behavior is an open problem. In this work, our goal is to leverage the power of simulation to train robotic policies that are proficient at interacting with humans upon deployment. But there is a chicken and egg problem -- how do we gather examples of a human interacting with a physical robot so as to model human behavior in simulation without already having a robot that is able to interact with a human? Our proposed method, Iterative-Sim-to-Real (i-S2R), attempts to address this. i-S2R bootstraps from a simple model of human behavior and alternates between training in simulation and deploying in the real world. In each iteration, both the human behavior model and the policy are refined. We evaluate our method on a real world robotic table tennis setting, where the objective for the robot is to play cooperatively with a human player for as long as possible. Table tennis is a high-speed, dynamic task that requires the two players to react quickly to each other's moves, making a challenging test bed for research on human-robot interaction. We present results on an industrial robotic arm that is able to cooperatively play table tennis with human players, achieving rallies of 22 successive hits on average and 150 at best. Further, for 80% of players, rally lengths are 70% to 175% longer compared to the sim-to-real (S2R) baseline. For videos of our system in action, please see https://sites.google.com/view/is2r.
Off-Policy General Value Functions to Represent Dynamic Role Assignments in RoboCup 3D Soccer Simulation
Feb 18, 2014

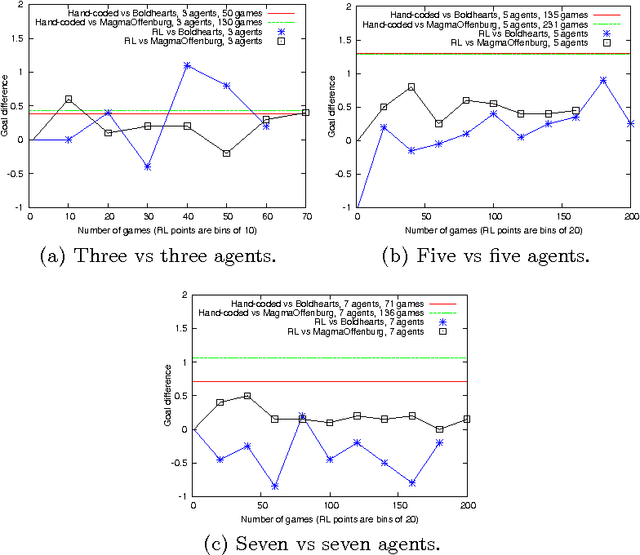

Collecting and maintaining accurate world knowledge in a dynamic, complex, adversarial, and stochastic environment such as the RoboCup 3D Soccer Simulation is a challenging task. Knowledge should be learned in real-time with time constraints. We use recently introduced Off-Policy Gradient Descent algorithms within Reinforcement Learning that illustrate learnable knowledge representations for dynamic role assignments. The results show that the agents have learned competitive policies against the top teams from the RoboCup 2012 competitions for three vs three, five vs five, and seven vs seven agents. We have explicitly used subsets of agents to identify the dynamics and the semantics for which the agents learn to maximize their performance measures, and to gather knowledge about different objectives, so that all agents participate effectively and efficiently within the group.