 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
Robotic Table Tennis: A Case Study into a High Speed Learning System
Sep 06, 2023



We present a deep-dive into a real-world robotic learning system that, in previous work, was shown to be capable of hundreds of table tennis rallies with a human and has the ability to precisely return the ball to desired targets. This system puts together a highly optimized perception subsystem, a high-speed low-latency robot controller, a simulation paradigm that can prevent damage in the real world and also train policies for zero-shot transfer, and automated real world environment resets that enable autonomous training and evaluation on physical robots. We complement a complete system description, including numerous design decisions that are typically not widely disseminated, with a collection of studies that clarify the importance of mitigating various sources of latency, accounting for training and deployment distribution shifts, robustness of the perception system, sensitivity to policy hyper-parameters, and choice of action space. A video demonstrating the components of the system and details of experimental results can be found at https://youtu.be/uFcnWjB42I0.
Learning High Speed Precision Table Tennis on a Physical Robot
Oct 07, 2022
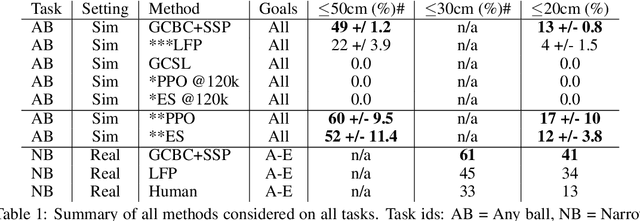
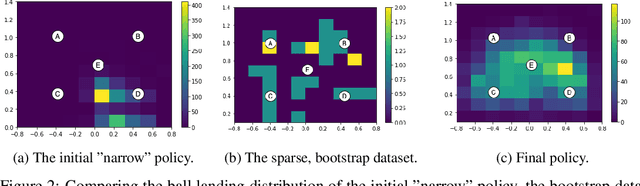
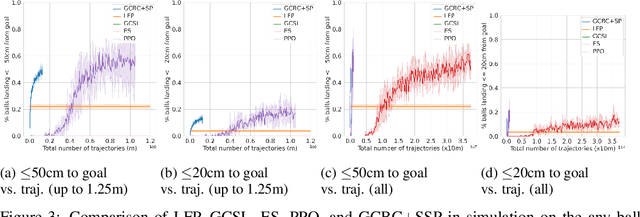
Learning goal conditioned control in the real world is a challenging open problem in robotics. Reinforcement learning systems have the potential to learn autonomously via trial-and-error, but in practice the costs of manual reward design, ensuring safe exploration, and hyperparameter tuning are often enough to preclude real world deployment. Imitation learning approaches, on the other hand, offer a simple way to learn control in the real world, but typically require costly curated demonstration data and lack a mechanism for continuous improvement. Recently, iterative imitation techniques have been shown to learn goal directed control from undirected demonstration data, and improve continuously via self-supervised goal reaching, but results thus far have been limited to simulated environments. In this work, we present evidence that iterative imitation learning can scale to goal-directed behavior on a real robot in a dynamic setting: high speed, precision table tennis (e.g. "land the ball on this particular target"). We find that this approach offers a straightforward way to do continuous on-robot learning, without complexities such as reward design or sim-to-real transfer. It is also scalable -- sample efficient enough to train on a physical robot in just a few hours. In real world evaluations, we find that the resulting policy can perform on par or better than amateur humans (with players sampled randomly from a robotics lab) at the task of returning the ball to specific targets on the table. Finally, we analyze the effect of an initial undirected bootstrap dataset size on performance, finding that a modest amount of unstructured demonstration data provided up-front drastically speeds up the convergence of a general purpose goal-reaching policy. See https://sites.google.com/view/goals-eye for videos.
i-Sim2Real: Reinforcement Learning of Robotic Policies in Tight Human-Robot Interaction Loops
Jul 14, 2022
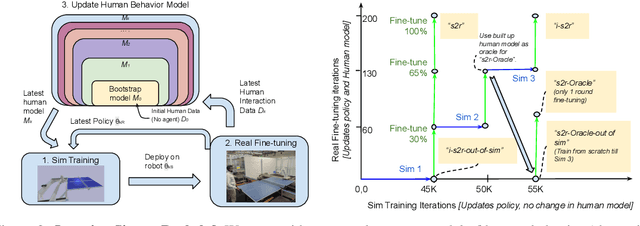
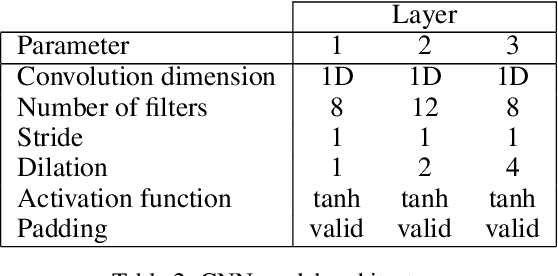
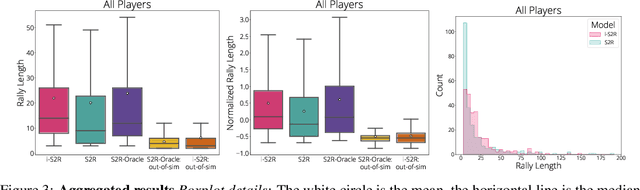
Sim-to-real transfer is a powerful paradigm for robotic reinforcement learning. The ability to train policies in simulation enables safe exploration and large-scale data collection quickly at low cost. However, prior works in sim-to-real transfer of robotic policies typically do not involve any human-robot interaction because accurately simulating human behavior is an open problem. In this work, our goal is to leverage the power of simulation to train robotic policies that are proficient at interacting with humans upon deployment. But there is a chicken and egg problem -- how do we gather examples of a human interacting with a physical robot so as to model human behavior in simulation without already having a robot that is able to interact with a human? Our proposed method, Iterative-Sim-to-Real (i-S2R), attempts to address this. i-S2R bootstraps from a simple model of human behavior and alternates between training in simulation and deploying in the real world. In each iteration, both the human behavior model and the policy are refined. We evaluate our method on a real world robotic table tennis setting, where the objective for the robot is to play cooperatively with a human player for as long as possible. Table tennis is a high-speed, dynamic task that requires the two players to react quickly to each other's moves, making a challenging test bed for research on human-robot interaction. We present results on an industrial robotic arm that is able to cooperatively play table tennis with human players, achieving rallies of 22 successive hits on average and 150 at best. Further, for 80% of players, rally lengths are 70% to 175% longer compared to the sim-to-real (S2R) baseline. For videos of our system in action, please see https://sites.google.com/view/is2r.