 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Diversity Bias in Deep Generative Models: Statistical Origins and Correction of Diversity Error
Feb 16, 2026Deep generative models have achieved great success in producing high-quality samples, making them a central tool across machine learning applications. Beyond sample quality, an important yet less systematically studied question is whether trained generative models faithfully capture the diversity of the underlying data distribution. In this work, we address this question by directly comparing the diversity of samples generated by state-of-the-art models with that of test samples drawn from the target data distribution, using recently proposed reference-free entropy-based diversity scores, Vendi and RKE. Across multiple benchmark datasets, we find that test data consistently attains substantially higher Vendi and RKE diversity scores than the generated samples, suggesting a systematic downward diversity bias in modern generative models. To understand the origin of this bias, we analyze the finite-sample behavior of entropy-based diversity scores and show that their expected values increase with sample size, implying that diversity estimated from finite training sets could inherently underestimate the diversity of the true distribution. As a result, optimizing the generators to minimize divergence to empirical data distributions would induce a loss of diversity. Finally, we discuss potential diversity-aware regularization and guidance strategies based on Vendi and RKE as principled directions for mitigating this bias, and provide empirical evidence suggesting their potential to improve the results.
APOLLO: Automated LLM and Lean Collaboration for Advanced Formal Reasoning
May 09, 2025



Formal reasoning and automated theorem proving constitute a challenging subfield of machine learning, in which machines are tasked with proving mathematical theorems using formal languages like Lean. A formal verification system can check whether a formal proof is correct or not almost instantaneously, but generating a completely correct formal proof with large language models (LLMs) remains a formidable task. The usual approach in the literature is to prompt the LLM many times (up to several thousands) until one of the generated proofs passes the verification system. In this work, we present APOLLO (Automated PrOof repair via LLM and Lean cOllaboration), a modular, model-agnostic pipeline that combines the strengths of the Lean compiler with an LLM's reasoning abilities to achieve better proof-generation results at a low sampling budget. Apollo directs a fully automated process in which the LLM generates proofs for theorems, a set of agents analyze the proofs, fix the syntax errors, identify the mistakes in the proofs using Lean, isolate failing sub-lemmas, utilize automated solvers, and invoke an LLM on each remaining goal with a low top-K budget. The repaired sub-proofs are recombined and reverified, iterating up to a user-controlled maximum number of attempts. On the miniF2F benchmark, we establish a new state-of-the-art accuracy of 75.0% among 7B-parameter models while keeping the sampling budget below one thousand. Moreover, Apollo raises the state-of-the-art accuracy for Goedel-Prover-SFT to 65.6% while cutting sample complexity from 25,600 to a few hundred. General-purpose models (o3-mini, o4-mini) jump from 3-7% to over 40% accuracy. Our results demonstrate that targeted, compiler-guided repair of LLM outputs yields dramatic gains in both efficiency and correctness, suggesting a general paradigm for scalable automated theorem proving.
Dissecting CLIP: Decomposition with a Schur Complement-based Approach
Dec 24, 2024


The use of CLIP embeddings to assess the alignment of samples produced by text-to-image generative models has been extensively explored in the literature. While the widely adopted CLIPScore, derived from the cosine similarity of text and image embeddings, effectively measures the relevance of a generated image, it does not quantify the diversity of images generated by a text-to-image model. In this work, we extend the application of CLIP embeddings to quantify and interpret the intrinsic diversity of text-to-image models, which is responsible for generating diverse images from similar text prompts. To achieve this, we propose a decomposition of the CLIP-based kernel covariance matrix of image data into text-based and non-text-based components. Using the Schur complement of the joint image-text kernel covariance matrix, we perform this decomposition and define the matrix-based entropy of the decomposed component as the \textit{Schur Complement Entropy (SCE)} score, a measure of the intrinsic diversity of a text-to-image model based on data collected with varying text prompts. Additionally, we demonstrate the use of the Schur complement-based decomposition to nullify the influence of a given prompt in the CLIP embedding of an image, enabling focus or defocus of embeddings on specific objects or properties for downstream tasks. We present several numerical results that apply our Schur complement-based approach to evaluate text-to-image models and modify CLIP image embeddings. The codebase is available at https://github.com/aziksh-ospanov/CLIP-DISSECTION
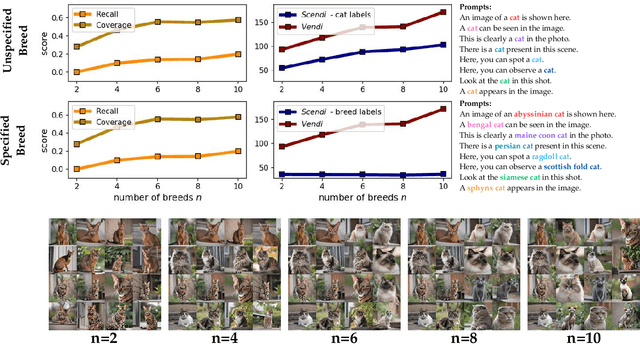
Conditional Vendi Score: An Information-Theoretic Approach to Diversity Evaluation of Prompt-based Generative Models
Nov 05, 2024



Text-conditioned generation models are commonly evaluated based on the quality of the generated data and its alignment with the input text prompt. On the other hand, several applications of prompt-based generative models require sufficient diversity in the generated data to ensure the models' capability of generating image and video samples possessing a variety of features. However, most existing diversity metrics are designed for unconditional generative models, and thus cannot distinguish the diversity arising from variations in text prompts and that contributed by the generative model itself. In this work, our goal is to quantify the prompt-induced and model-induced diversity in samples generated by prompt-based models. We propose an information-theoretic approach for internal diversity quantification, where we decompose the kernel-based entropy $H(X)$ of the generated data $X$ into the sum of the conditional entropy $H(X|T)$, given text variable $T$, and the mutual information $I(X; T)$ between the text and data variables. We introduce the \emph{Conditional-Vendi} score based on $H(X|T)$ to quantify the internal diversity of the model and the \emph{Information-Vendi} score based on $I(X; T)$ to measure the statistical relevance between the generated data and text prompts. We provide theoretical results to statistically interpret these scores and relate them to the unconditional Vendi score. We conduct several numerical experiments to show the correlation between the Conditional-Vendi score and the internal diversity of text-conditioned generative models. The codebase is available at \href{https://github.com/mjalali/conditional-vendi}{https://github.com/mjalali/conditional-vendi}.
On the Statistical Complexity of Estimating VENDI Scores from Empirical Data
Oct 29, 2024



Reference-free evaluation metrics for generative models have recently been studied in the machine learning community. As a reference-free metric, the VENDI score quantifies the diversity of generative models using matrix-based entropy from information theory. The VENDI score is usually computed through the eigendecomposition of an $n \times n$ kernel matrix for $n$ generated samples. However, due to the high computational cost of eigendecomposition for large $n$, the score is often computed on sample sizes limited to a few tens of thousands. In this paper, we explore the statistical convergence of the VENDI score and demonstrate that for kernel functions with an infinite feature map dimension, the evaluated score for a limited sample size may not converge to the matrix-based entropy statistic. We introduce an alternative statistic called the $t$-truncated VENDI statistic. We show that the existing Nystr\"om method and the FKEA approximation method for the VENDI score will both converge to the defined truncated VENDI statistic given a moderate sample size. We perform several numerical experiments to illustrate the concentration of the empirical VENDI score around the truncated VENDI statistic and discuss how this statistic correlates with the visual diversity of image data.
Towards a Scalable Reference-Free Evaluation of Generative Models
Jul 03, 2024While standard evaluation scores for generative models are mostly reference-based, a reference-dependent assessment of generative models could be generally difficult due to the unavailability of applicable reference datasets. Recently, the reference-free entropy scores, VENDI and RKE, have been proposed to evaluate the diversity of generated data. However, estimating these scores from data leads to significant computational costs for large-scale generative models. In this work, we leverage the random Fourier features framework to reduce the computational price and propose the Fourier-based Kernel Entropy Approximation (FKEA) method. We utilize FKEA's approximated eigenspectrum of the kernel matrix to efficiently estimate the mentioned entropy scores. Furthermore, we show the application of FKEA's proxy eigenvectors to reveal the method's identified modes in evaluating the diversity of produced samples. We provide a stochastic implementation of the FKEA assessment algorithm with a complexity $O(n)$ linearly growing with sample size $n$. We extensively evaluate FKEA's numerical performance in application to standard image, text, and video datasets. Our empirical results indicate the method's scalability and interpretability applied to large-scale generative models. The codebase is available at https://github.com/aziksh-ospanov/FKEA.