 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeizeIT2: Wearable Dataset Of Patients With Focal Epilepsy
Feb 03, 2025



The increasing technological advancements towards miniaturized physiological measuring devices have enabled continuous monitoring of epileptic patients outside of specialized environments. The large amounts of data that can be recorded with such devices holds significant potential for developing automated seizure detection frameworks. In this work, we present SeizeIT2, the first open dataset of wearable data recorded in patients with focal epilepsy. The dataset comprises more than 11,000 hours of multimodal data, including behind-the-ear electroencephalography, electrocardiography, electromyography and movement (accelerometer and gyroscope) data. The dataset contains 886 focal seizures recorded from 125 patients across five different European Epileptic Monitoring Centers. We present a suggestive training/validation split to propel the development of AI methodologies for seizure detection, as well as two benchmark approaches and evaluation metrics. The dataset can be accessed on OpenNeuro and is stored in Brain Imaging Data Structure (BIDS) format.
Multimodal Fusion Balancing Through Game-Theoretic Regularization
Nov 11, 2024



Multimodal learning can complete the picture of information extraction by uncovering key dependencies between data sources. However, current systems fail to fully leverage multiple modalities for optimal performance. This has been attributed to modality competition, where modalities strive for training resources, leaving some underoptimized. We show that current balancing methods struggle to train multimodal models that surpass even simple baselines, such as ensembles. This raises the question: how can we ensure that all modalities in multimodal training are sufficiently trained, and that learning from new modalities consistently improves performance? This paper proposes the Multimodal Competition Regularizer (MCR), a new loss component inspired by mutual information (MI) decomposition designed to prevent the adverse effects of competition in multimodal training. Our key contributions are: 1) Introducing game-theoretic principles in multimodal learning, where each modality acts as a player competing to maximize its influence on the final outcome, enabling automatic balancing of the MI terms. 2) Refining lower and upper bounds for each MI term to enhance the extraction of task-relevant unique and shared information across modalities. 3) Suggesting latent space permutations for conditional MI estimation, significantly improving computational efficiency. MCR outperforms all previously suggested training strategies and is the first to consistently improve multimodal learning beyond the ensemble baseline, clearly demonstrating that combining modalities leads to significant performance gains on both synthetic and large real-world datasets.
Improving Multimodal Learning with Multi-Loss Gradient Modulation
May 13, 2024



Learning from multiple modalities, such as audio and video, offers opportunities for leveraging complementary information, enhancing robustness, and improving contextual understanding and performance. However, combining such modalities presents challenges, especially when modalities differ in data structure, predictive contribution, and the complexity of their learning processes. It has been observed that one modality can potentially dominate the learning process, hindering the effective utilization of information from other modalities and leading to sub-optimal model performance. To address this issue the vast majority of previous works suggest to assess the unimodal contributions and dynamically adjust the training to equalize them. We improve upon previous work by introducing a multi-loss objective and further refining the balancing process, allowing it to dynamically adjust the learning pace of each modality in both directions, acceleration and deceleration, with the ability to phase out balancing effects upon convergence. We achieve superior results across three audio-video datasets: on CREMA-D, models with ResNet backbone encoders surpass the previous best by 1.9% to 12.4%, and Conformer backbone models deliver improvements ranging from 2.8% to 14.1% across different fusion methods. On AVE, improvements range from 2.7% to 7.7%, while on UCF101, gains reach up to 6.1%.
Multimodal wearable EEG, EMG and accelerometry measurements improve the accuracy of tonic-clonic seizure detection in-hospital
Mar 19, 2024



Objective: Most current wearable tonic-clonic seizure (TCS) detection systems are based on extra-cerebral signals, such as electromyography (EMG) or accelerometry (ACC). Although many of these devices show good sensitivity in seizure detection, their false positive rates (FPR) are still relatively high. Wearable EEG may improve performance; however, studies investigating this remain scarce. This paper aims 1) to investigate the possibility of detecting TCSs with a behind-the-ear, two-channel wearable EEG, and 2) to evaluate the added value of wearable EEG to other non-EEG modalities in multimodal TCS detection. Method: We included 27 participants with a total of 44 TCSs from the European multicenter study SeizeIT2. The multimodal wearable detection system Sensor Dot (Byteflies) was used to measure two-channel, behind-the-ear EEG, EMG, electrocardiography (ECG), ACC and gyroscope (GYR). First, we evaluated automatic unimodal detection of TCSs, using performance metrics such as sensitivity, precision, FPR and F1-score. Secondly, we fused the different modalities and again assessed performance. Algorithm-labeled segments were then provided to a neurologist and a wearable data expert, who reviewed and annotated the true positive TCSs, and discarded false positives (FPs). Results: Wearable EEG outperformed the other modalities in unimodal TCS detection by achieving a sensitivity of 100.0% and a FPR of 10.3/24h (compared to 97.7% sensitivity and 30.9/24h FPR for EMG; 95.5% sensitivity and 13.9 FPR for ACC). The combination of wearable EEG and EMG achieved overall the most clinically useful performance in offline TCS detection with a sensitivity of 97.7%, a FPR of 0.4/24 h, a precision of 43.0%, and a F1-score of 59.7%. Subsequent visual review of the automated detections resulted in maximal sensitivity and zero FPs.
CoRe-Sleep: A Multimodal Fusion Framework for Time Series Robust to Imperfect Modalities
Mar 27, 2023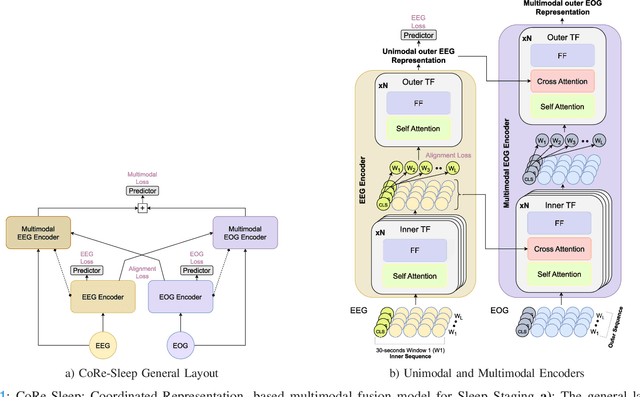
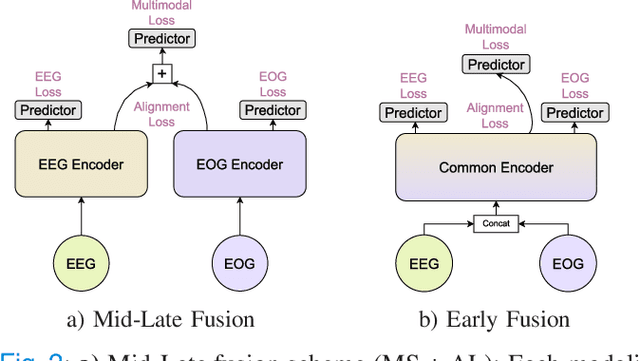
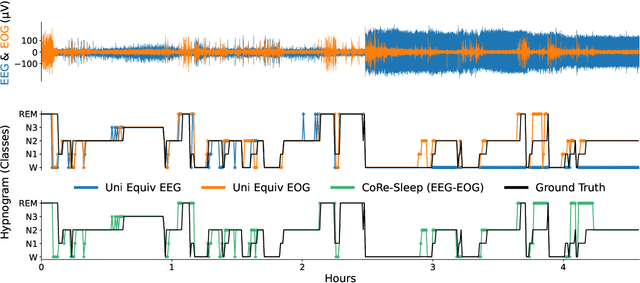
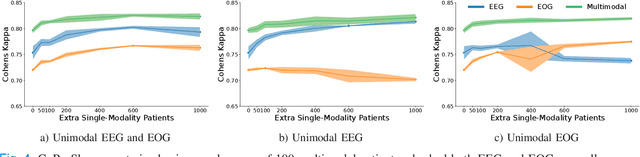
Sleep abnormalities can have severe health consequences. Automated sleep staging, i.e. labelling the sequence of sleep stages from the patient's physiological recordings, could simplify the diagnostic process. Previous work on automated sleep staging has achieved great results, mainly relying on the EEG signal. However, often multiple sources of information are available beyond EEG. This can be particularly beneficial when the EEG recordings are noisy or even missing completely. In this paper, we propose CoRe-Sleep, a Coordinated Representation multimodal fusion network that is particularly focused on improving the robustness of signal analysis on imperfect data. We demonstrate how appropriately handling multimodal information can be the key to achieving such robustness. CoRe-Sleep tolerates noisy or missing modalities segments, allowing training on incomplete data. Additionally, it shows state-of-the-art performance when testing on both multimodal and unimodal data using a single model on SHHS-1, the largest publicly available study that includes sleep stage labels. The results indicate that training the model on multimodal data does positively influence performance when tested on unimodal data. This work aims at bridging the gap between automated analysis tools and their clinical utility.
Early soft and flexible fusion of EEG and fMRI via tensor decompositions
May 12, 2020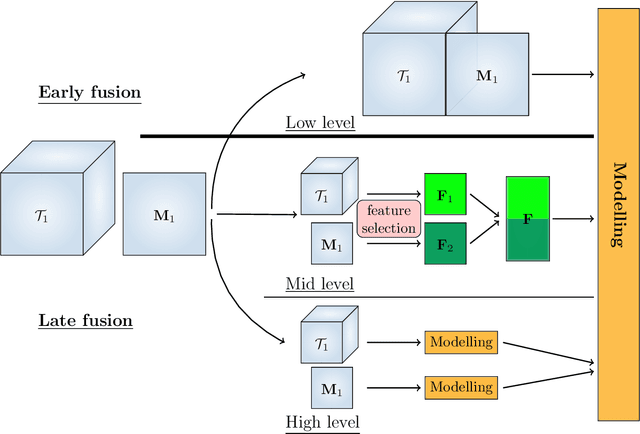

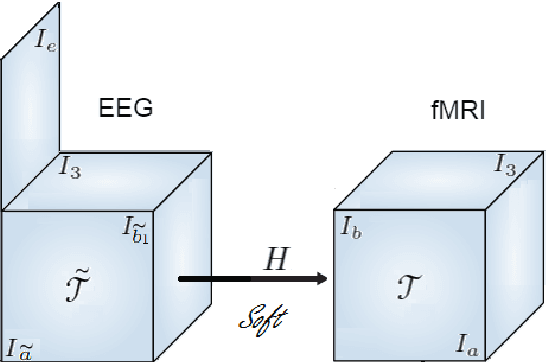
Data fusion refers to the joint analysis of multiple datasets which provide complementary views of the same task. In this preprint, the problem of jointly analyzing electroencephalography (EEG) and functional Magnetic Resonance Imaging (fMRI) data is considered. Jointly analyzing EEG and fMRI measurements is highly beneficial for studying brain function because these modalities have complementary spatiotemporal resolution: EEG offers good temporal resolution while fMRI is better in its spatial resolution. The fusion methods reported so far ignore the underlying multi-way nature of the data in at least one of the modalities and/or rely on very strong assumptions about the relation of the two datasets. In this preprint, these two points are addressed by adopting for the first time tensor models in the two modalities while also exploring double coupled tensor decompositions and by following soft and flexible coupling approaches to implement the multi-modal analysis. To cope with the Event Related Potential (ERP) variability in EEG, the PARAFAC2 model is adopted. The results obtained are compared against those of parallel Independent Component Analysis (ICA) and hard coupling alternatives in both simulated and real data. Our results confirm the superiority of tensorial methods over methods based on ICA. In scenarios that do not meet the assumptions underlying hard coupling, the advantage of soft and flexible coupled decompositions is clearly demonstrated.
Assisted Dictionary Learning for fMRI Data Analysis
Oct 11, 2016
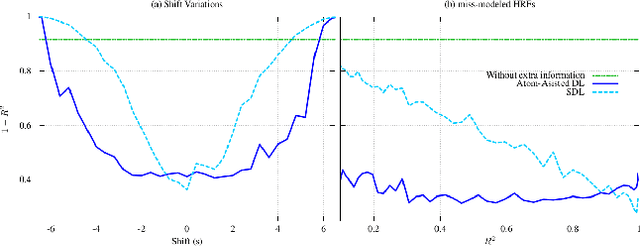
Extracting information from functional magnetic resonance (fMRI) images has been a major area of research for more than two decades. The goal of this work is to present a new method for the analysis of fMRI data sets, that is capable to incorporate a priori available information, via an efficient optimization framework. Tests on synthetic data sets demonstrate significant performance gains over existing methods of this kind.
Higher-Order Block Term Decomposition for Spatially Folded fMRI Data
Jul 15, 2016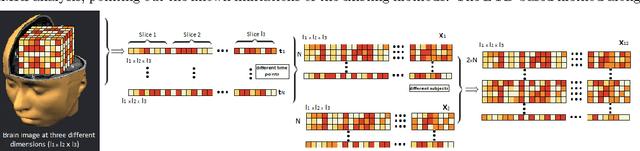
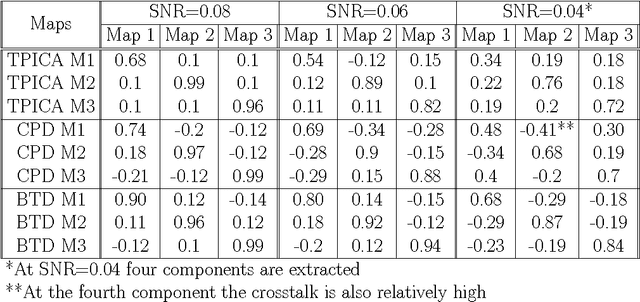
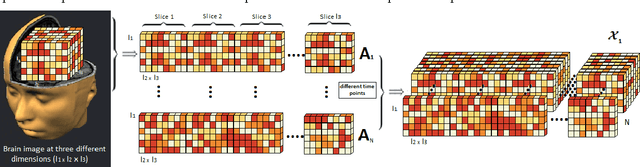
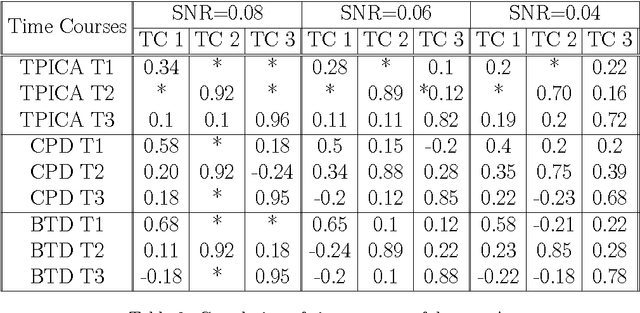
The growing use of neuroimaging technologies generates a massive amount of biomedical data that exhibit high dimensionality. Tensor-based analysis of brain imaging data has been proved quite effective in exploiting their multiway nature. The advantages of tensorial methods over matrix-based approaches have also been demonstrated in the characterization of functional magnetic resonance imaging (fMRI) data, where the spatial (voxel) dimensions are commonly grouped (unfolded) as a single way/mode of the 3-rd order array, the other two ways corresponding to time and subjects. However, such methods are known to be ineffective in more demanding scenarios, such as the ones with strong noise and/or significant overlapping of activated regions. This paper aims at investigating the possible gains from a better exploitation of the spatial dimension, through a higher- (4 or 5) order tensor modeling of the fMRI signal. In this context, and in order to increase the degrees of freedom of the modeling process, a higher-order Block Term Decomposition (BTD) is applied, for the first time in fMRI analysis. Its effectiveness is demonstrated via extensive simulation results.