 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-theoretic Multimodal Representation Learning for Electrocardiogram Signals
May 26, 2026Electrocardiograms (ECGs) are widely used non-invasive measurements of cardiac activity and play a central role in clinical diagnosis. Recent multimodal approaches align ECG signals with clinical reports to incorporate diagnostic semantics, but clinical reports often fail to preserve the rich physiological structure of ECG waveforms, particularly across multiple levels of abstraction ranging from coarse diagnostic categories to fine-grained morphology. To address this limitation, we formulate ECG representation learning from an information-theoretic perspective and derive a tractable objective that jointly preserves signal structure and integrates clinical semantics. Based on this principle, we propose \textbf{MERIT} (Multimodal ECG Representation via Information Theory), a dual-branch pretraining framework combining masked ECG modeling with ECG--text contrastive alignment. Extensive experiments on PTB-XL and additional benchmarks demonstrate consistent improvements over prior methods, including gains exceeding $3%$ F1 on PTB-XL All and $5%$ F1 on SubClass classification. In zero-shot evaluation, MERIT further improves performance by up to $ +2.66\%$ AUC and $ +2.11\%$ F1 on PTB-XL SubClass, while also demonstrating robustness under multiple distribution-shift settings. Moreover, leveraging the learned ECG representations for ECG-conditioned clinical text generation with large language models improves text quality across several metrics, including ROUGE and METEOR. Together, these results demonstrate that MERIT learns more informative and clinically meaningful ECG representations, particularly for fine-grained clinical applications.
NeuroAtlas: Benchmarking Foundation Models for Clinical EEG and Brain-Computer Interfaces
May 14, 2026Foundation models (FMs) promise to extract unified representations that generalize across downstream tasks. They have emerged across fields, including electroencephalography (EEG), but it is less clear how effective they are in this particular field. Published evaluations differ in datasets, in the EEG-specific preprocessing that might influence reported results, and in the reported metrics, frequently obscuring the clinical relevance in EEG. We introduce NeuroAtlas, the largest EEG benchmark to date: 42 datasets and 260k hours covering clinical EEG (epilepsy, sleep medicine, brain age estimation) and brain-computer interfaces, and include multiple datasets per task along with bespoke clinical evaluation metrics. Besides evaluating EEG-FMs with respect to supervised baselines, we present results from generic time-series FMs. We report three findings. First, EEG-specific FMs do not consistently outperform time-series FMs, which have neither EEG-focused architectures nor been pretrained on EEG. Second, standard machine learning metrics are insufficient to assess clinical utility: thus, we thoroughly evaluate more appropriate measures such as the quality of event-level decision-making, hypnogram-derived features, and the brain-age gap in the domains of epilepsy, sleep, and brain age, respectively. Third, model rankings and performance can vary substantially within domains. We conclude that pretrained models perform largely on par, with only narrow advantages for a few, and that current models do not yet deliver on the promise of an out-of-the-box unified EEG model. NeuroAtlas exposes this gap and provides the datasets and metrics for the next generation of unified EEG FMs.
Multimodal Fusion Balancing Through Game-Theoretic Regularization
Nov 11, 2024



Multimodal learning can complete the picture of information extraction by uncovering key dependencies between data sources. However, current systems fail to fully leverage multiple modalities for optimal performance. This has been attributed to modality competition, where modalities strive for training resources, leaving some underoptimized. We show that current balancing methods struggle to train multimodal models that surpass even simple baselines, such as ensembles. This raises the question: how can we ensure that all modalities in multimodal training are sufficiently trained, and that learning from new modalities consistently improves performance? This paper proposes the Multimodal Competition Regularizer (MCR), a new loss component inspired by mutual information (MI) decomposition designed to prevent the adverse effects of competition in multimodal training. Our key contributions are: 1) Introducing game-theoretic principles in multimodal learning, where each modality acts as a player competing to maximize its influence on the final outcome, enabling automatic balancing of the MI terms. 2) Refining lower and upper bounds for each MI term to enhance the extraction of task-relevant unique and shared information across modalities. 3) Suggesting latent space permutations for conditional MI estimation, significantly improving computational efficiency. MCR outperforms all previously suggested training strategies and is the first to consistently improve multimodal learning beyond the ensemble baseline, clearly demonstrating that combining modalities leads to significant performance gains on both synthetic and large real-world datasets.
Improving Multimodal Learning with Multi-Loss Gradient Modulation
May 13, 2024



Learning from multiple modalities, such as audio and video, offers opportunities for leveraging complementary information, enhancing robustness, and improving contextual understanding and performance. However, combining such modalities presents challenges, especially when modalities differ in data structure, predictive contribution, and the complexity of their learning processes. It has been observed that one modality can potentially dominate the learning process, hindering the effective utilization of information from other modalities and leading to sub-optimal model performance. To address this issue the vast majority of previous works suggest to assess the unimodal contributions and dynamically adjust the training to equalize them. We improve upon previous work by introducing a multi-loss objective and further refining the balancing process, allowing it to dynamically adjust the learning pace of each modality in both directions, acceleration and deceleration, with the ability to phase out balancing effects upon convergence. We achieve superior results across three audio-video datasets: on CREMA-D, models with ResNet backbone encoders surpass the previous best by 1.9% to 12.4%, and Conformer backbone models deliver improvements ranging from 2.8% to 14.1% across different fusion methods. On AVE, improvements range from 2.7% to 7.7%, while on UCF101, gains reach up to 6.1%.
CoRe-Sleep: A Multimodal Fusion Framework for Time Series Robust to Imperfect Modalities
Mar 27, 2023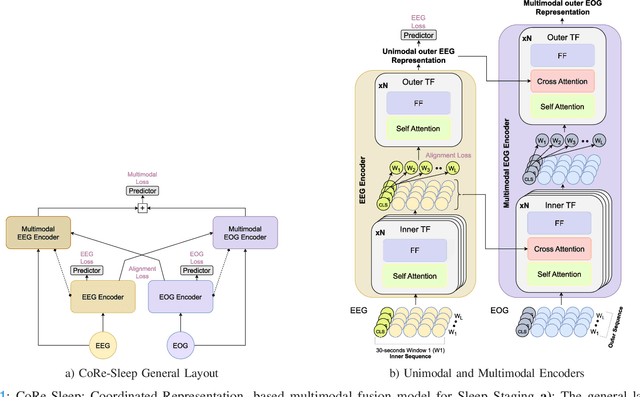
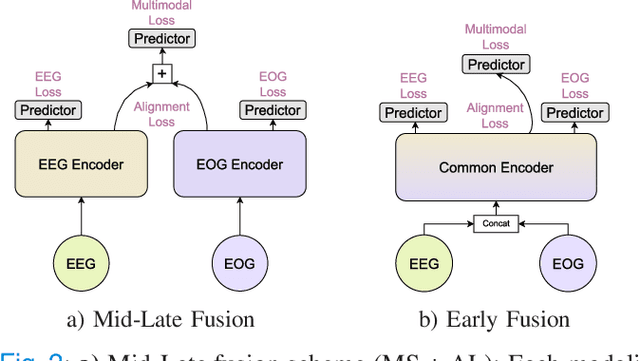
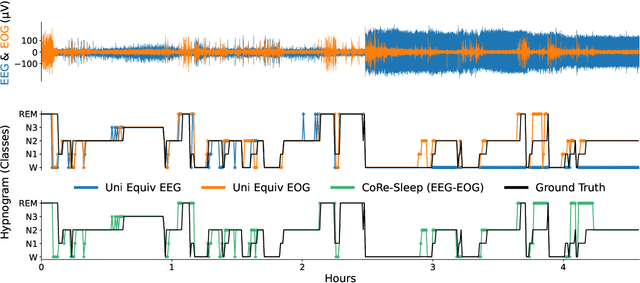
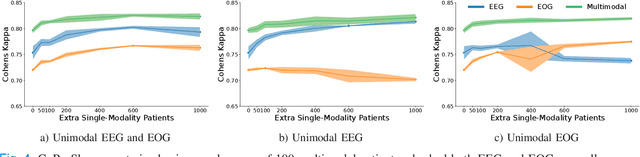
Sleep abnormalities can have severe health consequences. Automated sleep staging, i.e. labelling the sequence of sleep stages from the patient's physiological recordings, could simplify the diagnostic process. Previous work on automated sleep staging has achieved great results, mainly relying on the EEG signal. However, often multiple sources of information are available beyond EEG. This can be particularly beneficial when the EEG recordings are noisy or even missing completely. In this paper, we propose CoRe-Sleep, a Coordinated Representation multimodal fusion network that is particularly focused on improving the robustness of signal analysis on imperfect data. We demonstrate how appropriately handling multimodal information can be the key to achieving such robustness. CoRe-Sleep tolerates noisy or missing modalities segments, allowing training on incomplete data. Additionally, it shows state-of-the-art performance when testing on both multimodal and unimodal data using a single model on SHHS-1, the largest publicly available study that includes sleep stage labels. The results indicate that training the model on multimodal data does positively influence performance when tested on unimodal data. This work aims at bridging the gap between automated analysis tools and their clinical utility.