 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Fusion Balancing Through Game-Theoretic Regularization
Nov 11, 2024



Multimodal learning can complete the picture of information extraction by uncovering key dependencies between data sources. However, current systems fail to fully leverage multiple modalities for optimal performance. This has been attributed to modality competition, where modalities strive for training resources, leaving some underoptimized. We show that current balancing methods struggle to train multimodal models that surpass even simple baselines, such as ensembles. This raises the question: how can we ensure that all modalities in multimodal training are sufficiently trained, and that learning from new modalities consistently improves performance? This paper proposes the Multimodal Competition Regularizer (MCR), a new loss component inspired by mutual information (MI) decomposition designed to prevent the adverse effects of competition in multimodal training. Our key contributions are: 1) Introducing game-theoretic principles in multimodal learning, where each modality acts as a player competing to maximize its influence on the final outcome, enabling automatic balancing of the MI terms. 2) Refining lower and upper bounds for each MI term to enhance the extraction of task-relevant unique and shared information across modalities. 3) Suggesting latent space permutations for conditional MI estimation, significantly improving computational efficiency. MCR outperforms all previously suggested training strategies and is the first to consistently improve multimodal learning beyond the ensemble baseline, clearly demonstrating that combining modalities leads to significant performance gains on both synthetic and large real-world datasets.
Conditional Gumbel-Softmax for constrained feature selection with application to node selection in wireless sensor networks
Jun 03, 2024



In this paper, we introduce Conditional Gumbel-Softmax as a method to perform end-to-end learning of the optimal feature subset for a given task and deep neural network (DNN) model, while adhering to certain pairwise constraints between the features. We do this by conditioning the selection of each feature in the subset on another feature. We demonstrate how this approach can be used to select the task-optimal nodes composing a wireless sensor network (WSN) while ensuring that none of the nodes that require communication between one another have too large of a distance between them, limiting the required power spent on this communication. We validate this approach on an emulated Wireless Electroencephalography (EEG) Sensor Network (WESN) solving a motor execution task. We analyze how the performance of the WESN varies as the constraints are made more stringent and how well the Conditional Gumbel-Softmax performs in comparison with a heuristic, greedy selection method. While the application focus of this paper is on wearable brain-computer interfaces, the proposed methodology is generic and can readily be applied to node deployment in wireless sensor networks and constrained feature selection in other applications as well.
A distributed neural network architecture for dynamic sensor selection with application to bandwidth-constrained body-sensor networks
Aug 16, 2023



We propose a dynamic sensor selection approach for deep neural networks (DNNs), which is able to derive an optimal sensor subset selection for each specific input sample instead of a fixed selection for the entire dataset. This dynamic selection is jointly learned with the task model in an end-to-end way, using the Gumbel-Softmax trick to allow the discrete decisions to be learned through standard backpropagation. We then show how we can use this dynamic selection to increase the lifetime of a wireless sensor network (WSN) by imposing constraints on how often each node is allowed to transmit. We further improve performance by including a dynamic spatial filter that makes the task-DNN more robust against the fact that it now needs to be able to handle a multitude of possible node subsets. Finally, we explain how the selection of the optimal channels can be distributed across the different nodes in a WSN. We validate this method on a use case in the context of body-sensor networks, where we use real electroencephalography (EEG) sensor data to emulate an EEG sensor network. We analyze the resulting trade-offs between transmission load and task accuracy.
Bandwidth-efficient distributed neural network architectures with application to body sensor networks
Oct 14, 2022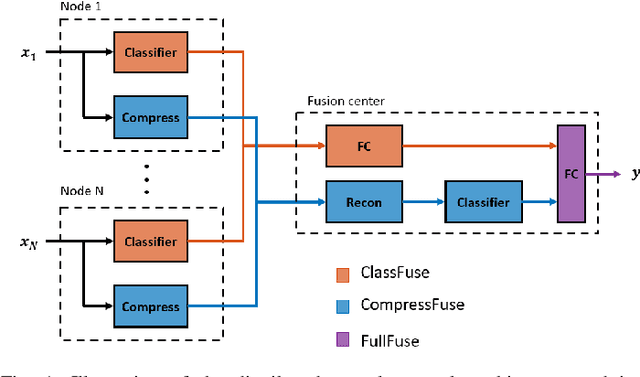
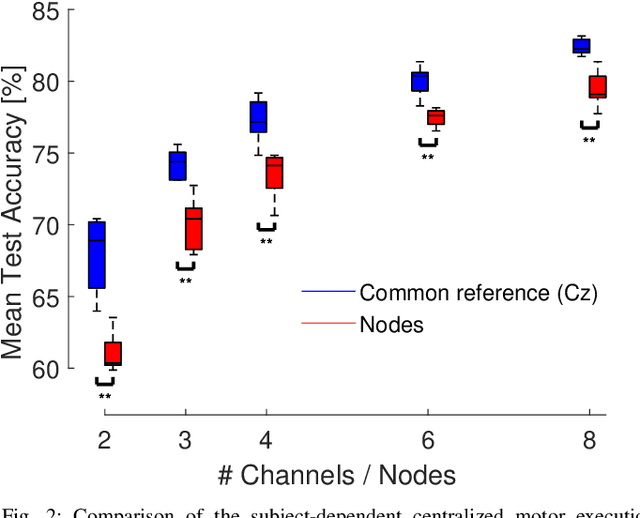
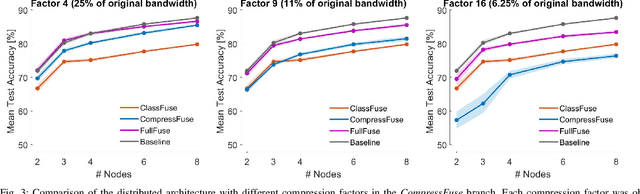
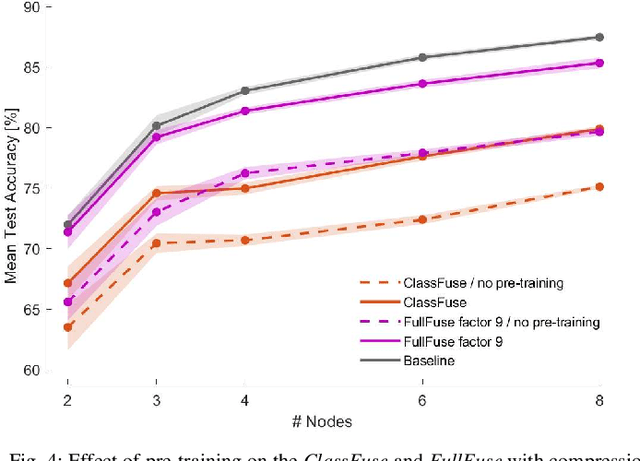
In this paper, we describe a conceptual design methodology to design distributed neural network architectures that can perform efficient inference within sensor networks with communication bandwidth constraints. The different sensor channels are distributed across multiple sensor devices, which have to exchange data over bandwidth-limited communication channels to solve, e.g., a classification task. Our design methodology starts from a user-defined centralized neural network and transforms it into a distributed architecture in which the channels are distributed over different nodes. The distributed network consists of two parallel branches of which the outputs are fused at the fusion center. The first branch collects classification results from local, node-specific classifiers while the second branch compresses each node's signal and then reconstructs the multi-channel time series for classification at the fusion center. We further improve bandwidth gains by dynamically activating the compression path when the local classifications do not suffice. We validate this method on a motor execution task in an emulated EEG sensor network and analyze the resulting bandwidth-accuracy trade-offs. Our experiments show that the proposed framework enables up to a factor 20 in bandwidth reduction with minimal loss (up to 2%) in classification accuracy compared to the centralized baseline on the demonstrated motor execution task. The proposed method offers a way to smoothly transform a centralized architecture to a distributed, bandwidth-efficient network amenable for low-power sensor networks. While the application focus of this paper is on wearable brain-computer interfaces, the proposed methodology can be applied in other sensor network-like applications as well.
End-to-end learnable EEG channel selection with deep neural networks
Feb 19, 2021



Many electroencephalography (EEG) applications rely on channel selection methods to remove the least informative channels, e.g., to reduce the amount of electrodes to be mounted, to decrease the computational load, or to reduce overfitting effects and improve performance. Wrapper-based channel selection methods aim to match the channel selection step to the target model, yet they require to re-train the model multiple times on different candidate channel subsets, which often leads to an unacceptably high computational cost, especially when said model is a (deep) neural network. To alleviate this, we propose a framework to embed the EEG channel selection in the neural network itself to jointly learn the network weights and optimal channels in an end-to-end manner by traditional backpropagation algorithms. We deal with the discrete nature of this new optimization problem by employing continuous relaxations of the discrete channel selection parameters based on the Gumbel-softmax trick. We also propose a regularization method that discourages selecting channels more than once. This generic approach is evaluated on two different EEG tasks: motor imagery brain-computer interfaces and auditory attention decoding. The results demonstrate that our framework is generally applicable, while being competitive with state-of-the art EEG channel selection methods, tailored to these tasks.