 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRingMo-Agent: A Unified Remote Sensing Foundation Model for Multi-Platform and Multi-Modal Reasoning
Jul 28, 2025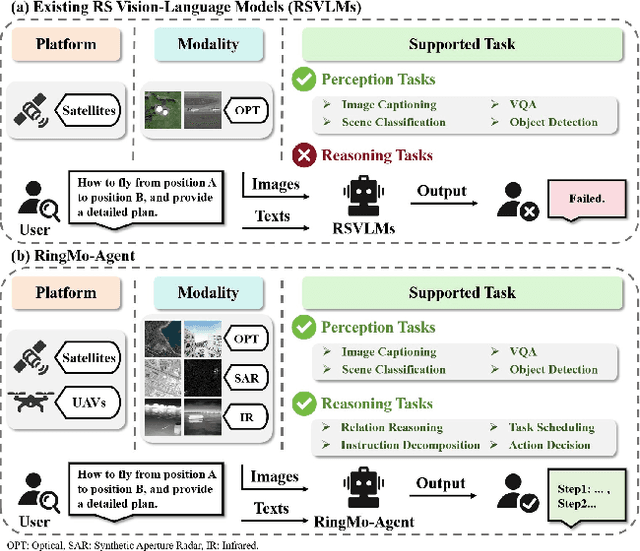
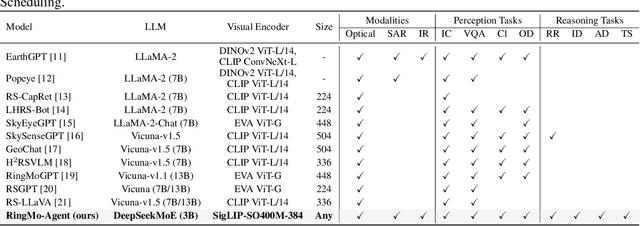

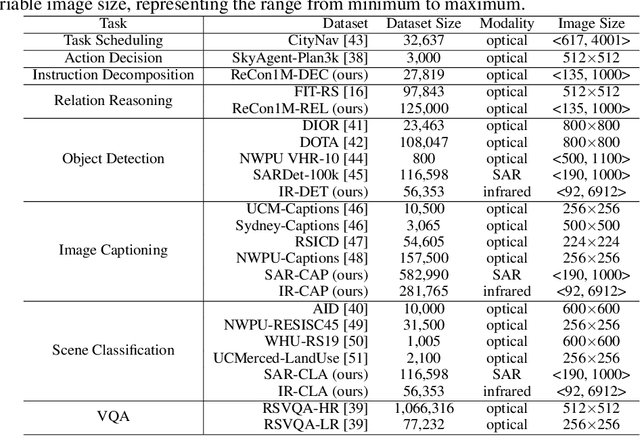
Remote sensing (RS) images from multiple modalities and platforms exhibit diverse details due to differences in sensor characteristics and imaging perspectives. Existing vision-language research in RS largely relies on relatively homogeneous data sources. Moreover, they still remain limited to conventional visual perception tasks such as classification or captioning. As a result, these methods fail to serve as a unified and standalone framework capable of effectively handling RS imagery from diverse sources in real-world applications. To address these issues, we propose RingMo-Agent, a model designed to handle multi-modal and multi-platform data that performs perception and reasoning tasks based on user textual instructions. Compared with existing models, RingMo-Agent 1) is supported by a large-scale vision-language dataset named RS-VL3M, comprising over 3 million image-text pairs, spanning optical, SAR, and infrared (IR) modalities collected from both satellite and UAV platforms, covering perception and challenging reasoning tasks; 2) learns modality adaptive representations by incorporating separated embedding layers to construct isolated features for heterogeneous modalities and reduce cross-modal interference; 3) unifies task modeling by introducing task-specific tokens and employing a token-based high-dimensional hidden state decoding mechanism designed for long-horizon spatial tasks. Extensive experiments on various RS vision-language tasks demonstrate that RingMo-Agent not only proves effective in both visual understanding and sophisticated analytical tasks, but also exhibits strong generalizability across different platforms and sensing modalities.
ViRefSAM: Visual Reference-Guided Segment Anything Model for Remote Sensing Segmentation
Jul 03, 2025The Segment Anything Model (SAM), with its prompt-driven paradigm, exhibits strong generalization in generic segmentation tasks. However, applying SAM to remote sensing (RS) images still faces two major challenges. First, manually constructing precise prompts for each image (e.g., points or boxes) is labor-intensive and inefficient, especially in RS scenarios with dense small objects or spatially fragmented distributions. Second, SAM lacks domain adaptability, as it is pre-trained primarily on natural images and struggles to capture RS-specific semantics and spatial characteristics, especially when segmenting novel or unseen classes. To address these issues, inspired by few-shot learning, we propose ViRefSAM, a novel framework that guides SAM utilizing only a few annotated reference images that contain class-specific objects. Without requiring manual prompts, ViRefSAM enables automatic segmentation of class-consistent objects across RS images. Specifically, ViRefSAM introduces two key components while keeping SAM's original architecture intact: (1) a Visual Contextual Prompt Encoder that extracts class-specific semantic clues from reference images and generates object-aware prompts via contextual interaction with target images; and (2) a Dynamic Target Alignment Adapter, integrated into SAM's image encoder, which mitigates the domain gap by injecting class-specific semantics into target image features, enabling SAM to dynamically focus on task-relevant regions. Extensive experiments on three few-shot segmentation benchmarks, including iSAID-5$^i$, LoveDA-2$^i$, and COCO-20$^i$, demonstrate that ViRefSAM enables accurate and automatic segmentation of unseen classes by leveraging only a few reference images and consistently outperforms existing few-shot segmentation methods across diverse datasets.
A Complex-valued SAR Foundation Model Based on Physically Inspired Representation Learning
Apr 16, 2025Vision foundation models in remote sensing have been extensively studied due to their superior generalization on various downstream tasks. Synthetic Aperture Radar (SAR) offers all-day, all-weather imaging capabilities, providing significant advantages for Earth observation. However, establishing a foundation model for SAR image interpretation inevitably encounters the challenges of insufficient information utilization and poor interpretability. In this paper, we propose a remote sensing foundation model based on complex-valued SAR data, which simulates the polarimetric decomposition process for pre-training, i.e., characterizing pixel scattering intensity as a weighted combination of scattering bases and scattering coefficients, thereby endowing the foundation model with physical interpretability. Specifically, we construct a series of scattering queries, each representing an independent and meaningful scattering basis, which interact with SAR features in the scattering query decoder and output the corresponding scattering coefficient. To guide the pre-training process, polarimetric decomposition loss and power self-supervision loss are constructed. The former aligns the predicted coefficients with Yamaguchi coefficients, while the latter reconstructs power from the predicted coefficients and compares it to the input image's power. The performance of our foundation model is validated on six typical downstream tasks, achieving state-of-the-art results. Notably, the foundation model can extract stable feature representations and exhibits strong generalization, even in data-scarce conditions.
RingMoE: Mixture-of-Modality-Experts Multi-Modal Foundation Models for Universal Remote Sensing Image Interpretation
Apr 04, 2025The rapid advancement of foundation models has revolutionized visual representation learning in a self-supervised manner. However, their application in remote sensing (RS) remains constrained by a fundamental gap: existing models predominantly handle single or limited modalities, overlooking the inherently multi-modal nature of RS observations. Optical, synthetic aperture radar (SAR), and multi-spectral data offer complementary insights that significantly reduce the inherent ambiguity and uncertainty in single-source analysis. To bridge this gap, we introduce RingMoE, a unified multi-modal RS foundation model with 14.7 billion parameters, pre-trained on 400 million multi-modal RS images from nine satellites. RingMoE incorporates three key innovations: (1) A hierarchical Mixture-of-Experts (MoE) architecture comprising modal-specialized, collaborative, and shared experts, effectively modeling intra-modal knowledge while capturing cross-modal dependencies to mitigate conflicts between modal representations; (2) Physics-informed self-supervised learning, explicitly embedding sensor-specific radiometric characteristics into the pre-training objectives; (3) Dynamic expert pruning, enabling adaptive model compression from 14.7B to 1B parameters while maintaining performance, facilitating efficient deployment in Earth observation applications. Evaluated across 23 benchmarks spanning six key RS tasks (i.e., classification, detection, segmentation, tracking, change detection, and depth estimation), RingMoE outperforms existing foundation models and sets new SOTAs, demonstrating remarkable adaptability from single-modal to multi-modal scenarios. Beyond theoretical progress, it has been deployed and trialed in multiple sectors, including emergency response, land management, marine sciences, and urban planning.
SA-Occ: Satellite-Assisted 3D Occupancy Prediction in Real World
Mar 20, 2025

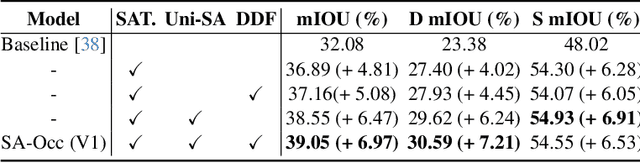
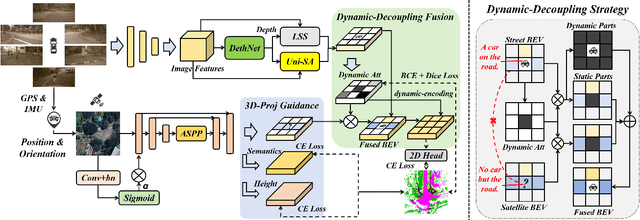
Existing vision-based 3D occupancy prediction methods are inherently limited in accuracy due to their exclusive reliance on street-view imagery, neglecting the potential benefits of incorporating satellite views. We propose SA-Occ, the first Satellite-Assisted 3D occupancy prediction model, which leverages GPS & IMU to integrate historical yet readily available satellite imagery into real-time applications, effectively mitigating limitations of ego-vehicle perceptions, involving occlusions and degraded performance in distant regions. To address the core challenges of cross-view perception, we propose: 1) Dynamic-Decoupling Fusion, which resolves inconsistencies in dynamic regions caused by the temporal asynchrony between satellite and street views; 2) 3D-Proj Guidance, a module that enhances 3D feature extraction from inherently 2D satellite imagery; and 3) Uniform Sampling Alignment, which aligns the sampling density between street and satellite views. Evaluated on Occ3D-nuScenes, SA-Occ achieves state-of-the-art performance, especially among single-frame methods, with a 39.05% mIoU (a 6.97% improvement), while incurring only 6.93 ms of additional latency per frame. Our code and newly curated dataset are available at https://github.com/chenchen235/SA-Occ.
SemStereo: Semantic-Constrained Stereo Matching Network for Remote Sensing
Dec 17, 2024



Semantic segmentation and 3D reconstruction are two fundamental tasks in remote sensing, typically treated as separate or loosely coupled tasks. Despite attempts to integrate them into a unified network, the constraints between the two heterogeneous tasks are not explicitly modeled, since the pioneering studies either utilize a loosely coupled parallel structure or engage in only implicit interactions, failing to capture the inherent connections. In this work, we explore the connections between the two tasks and propose a new network that imposes semantic constraints on the stereo matching task, both implicitly and explicitly. Implicitly, we transform the traditional parallel structure to a new cascade structure termed Semantic-Guided Cascade structure, where the deep features enriched with semantic information are utilized for the computation of initial disparity maps, enhancing semantic guidance. Explicitly, we propose a Semantic Selective Refinement (SSR) module and a Left-Right Semantic Consistency (LRSC) module. The SSR refines the initial disparity map under the guidance of the semantic map. The LRSC ensures semantic consistency between two views via reducing the semantic divergence after transforming the semantic map from one view to the other using the disparity map. Experiments on the US3D and WHU datasets demonstrate that our method achieves state-of-the-art performance for both semantic segmentation and stereo matching.
RS-vHeat: Heat Conduction Guided Efficient Remote Sensing Foundation Model
Nov 27, 2024Remote sensing foundation models largely break away from the traditional paradigm of designing task-specific models, offering greater scalability across multiple tasks. However, they face challenges such as low computational efficiency and limited interpretability, especially when dealing with high-resolution remote sensing images. To overcome these, we draw inspiration from heat conduction, a physical process modeling local heat diffusion. Building on this idea, we are the first to explore the potential of using the parallel computing model of heat conduction to simulate the local region correlations in high-resolution remote sensing images, and introduce RS-vHeat, an efficient multi-modal remote sensing foundation model. Specifically, RS-vHeat 1) applies the Heat Conduction Operator (HCO) with a complexity of $O(N^{1.5})$ and a global receptive field, reducing computational overhead while capturing remote sensing object structure information to guide heat diffusion; 2) learns the frequency distribution representations of various scenes through a self-supervised strategy based on frequency domain hierarchical masking and multi-domain reconstruction; 3) significantly improves efficiency and performance over state-of-the-art techniques across 4 tasks and 10 datasets. Compared to attention-based remote sensing foundation models, we reduces memory consumption by 84%, decreases FLOPs by 24% and improves throughput by 2.7 times.
NavAgent: Multi-scale Urban Street View Fusion For UAV Embodied Vision-and-Language Navigation
Nov 13, 2024Vision-and-Language Navigation (VLN), as a widely discussed research direction in embodied intelligence, aims to enable embodied agents to navigate in complicated visual environments through natural language commands. Most existing VLN methods focus on indoor ground robot scenarios. However, when applied to UAV VLN in outdoor urban scenes, it faces two significant challenges. First, urban scenes contain numerous objects, which makes it challenging to match fine-grained landmarks in images with complex textual descriptions of these landmarks. Second, overall environmental information encompasses multiple modal dimensions, and the diversity of representations significantly increases the complexity of the encoding process. To address these challenges, we propose NavAgent, the first urban UAV embodied navigation model driven by a large Vision-Language Model. NavAgent undertakes navigation tasks by synthesizing multi-scale environmental information, including topological maps (global), panoramas (medium), and fine-grained landmarks (local). Specifically, we utilize GLIP to build a visual recognizer for landmark capable of identifying and linguisticizing fine-grained landmarks. Subsequently, we develop dynamically growing scene topology map that integrate environmental information and employ Graph Convolutional Networks to encode global environmental data. In addition, to train the visual recognizer for landmark, we develop NavAgent-Landmark2K, the first fine-grained landmark dataset for real urban street scenes. In experiments conducted on the Touchdown and Map2seq datasets, NavAgent outperforms strong baseline models. The code and dataset will be released to the community to facilitate the exploration and development of outdoor VLN.
AgMTR: Agent Mining Transformer for Few-shot Segmentation in Remote Sensing
Sep 26, 2024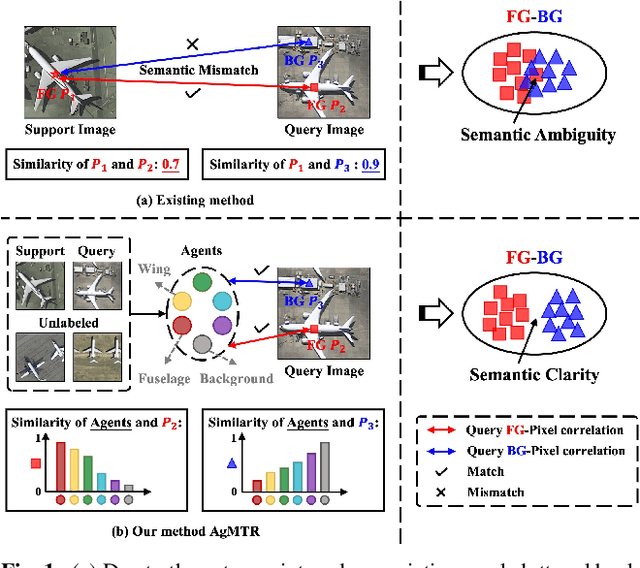
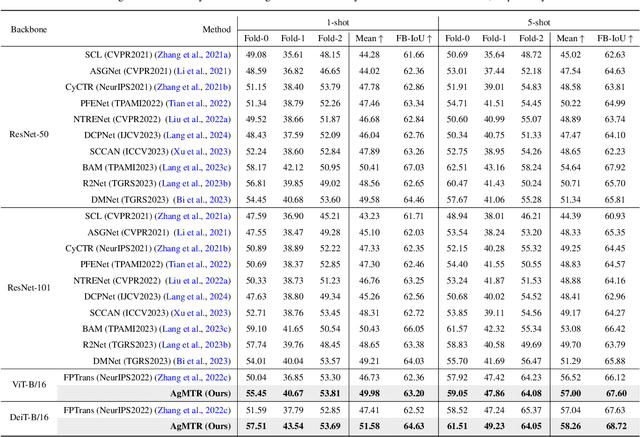
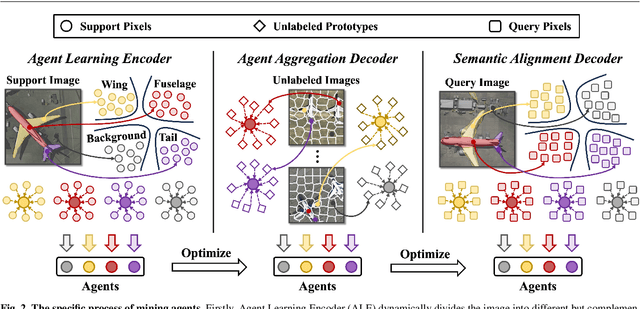
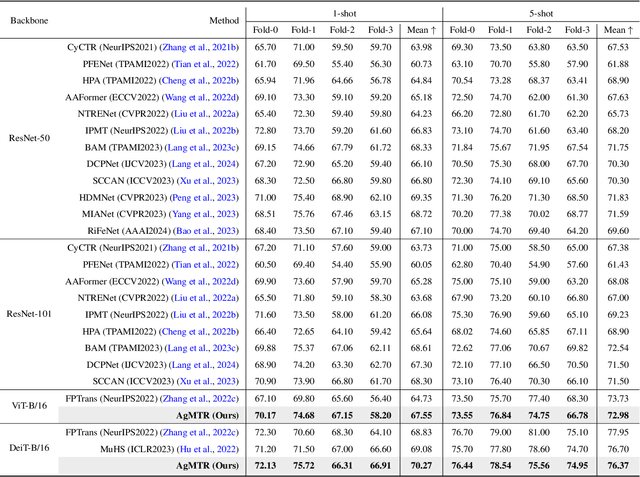
Few-shot Segmentation (FSS) aims to segment the interested objects in the query image with just a handful of labeled samples (i.e., support images). Previous schemes would leverage the similarity between support-query pixel pairs to construct the pixel-level semantic correlation. However, in remote sensing scenarios with extreme intra-class variations and cluttered backgrounds, such pixel-level correlations may produce tremendous mismatches, resulting in semantic ambiguity between the query foreground (FG) and background (BG) pixels. To tackle this problem, we propose a novel Agent Mining Transformer (AgMTR), which adaptively mines a set of local-aware agents to construct agent-level semantic correlation. Compared with pixel-level semantics, the given agents are equipped with local-contextual information and possess a broader receptive field. At this point, different query pixels can selectively aggregate the fine-grained local semantics of different agents, thereby enhancing the semantic clarity between query FG and BG pixels. Concretely, the Agent Learning Encoder (ALE) is first proposed to erect the optimal transport plan that arranges different agents to aggregate support semantics under different local regions. Then, for further optimizing the agents, the Agent Aggregation Decoder (AAD) and the Semantic Alignment Decoder (SAD) are constructed to break through the limited support set for mining valuable class-specific semantics from unlabeled data sources and the query image itself, respectively. Extensive experiments on the remote sensing benchmark iSAID indicate that the proposed method achieves state-of-the-art performance. Surprisingly, our method remains quite competitive when extended to more common natural scenarios, i.e., PASCAL-5i and COCO-20i.
Prompt-and-Transfer: Dynamic Class-aware Enhancement for Few-shot Segmentation
Sep 16, 2024For more efficient generalization to unseen domains (classes), most Few-shot Segmentation (FSS) would directly exploit pre-trained encoders and only fine-tune the decoder, especially in the current era of large models. However, such fixed feature encoders tend to be class-agnostic, inevitably activating objects that are irrelevant to the target class. In contrast, humans can effortlessly focus on specific objects in the line of sight. This paper mimics the visual perception pattern of human beings and proposes a novel and powerful prompt-driven scheme, called ``Prompt and Transfer" (PAT), which constructs a dynamic class-aware prompting paradigm to tune the encoder for focusing on the interested object (target class) in the current task. Three key points are elaborated to enhance the prompting: 1) Cross-modal linguistic information is introduced to initialize prompts for each task. 2) Semantic Prompt Transfer (SPT) that precisely transfers the class-specific semantics within the images to prompts. 3) Part Mask Generator (PMG) that works in conjunction with SPT to adaptively generate different but complementary part prompts for different individuals. Surprisingly, PAT achieves competitive performance on 4 different tasks including standard FSS, Cross-domain FSS (e.g., CV, medical, and remote sensing domains), Weak-label FSS, and Zero-shot Segmentation, setting new state-of-the-arts on 11 benchmarks.