 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-Occ: Satellite-Assisted 3D Occupancy Prediction in Real World
Mar 20, 2025

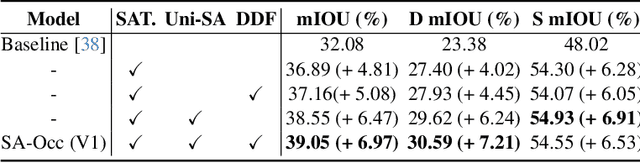
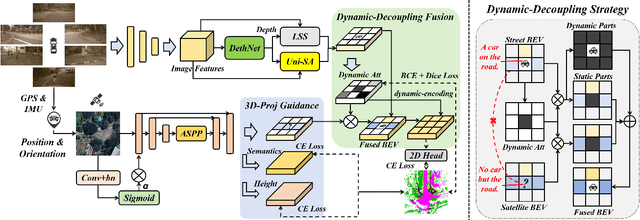
Existing vision-based 3D occupancy prediction methods are inherently limited in accuracy due to their exclusive reliance on street-view imagery, neglecting the potential benefits of incorporating satellite views. We propose SA-Occ, the first Satellite-Assisted 3D occupancy prediction model, which leverages GPS & IMU to integrate historical yet readily available satellite imagery into real-time applications, effectively mitigating limitations of ego-vehicle perceptions, involving occlusions and degraded performance in distant regions. To address the core challenges of cross-view perception, we propose: 1) Dynamic-Decoupling Fusion, which resolves inconsistencies in dynamic regions caused by the temporal asynchrony between satellite and street views; 2) 3D-Proj Guidance, a module that enhances 3D feature extraction from inherently 2D satellite imagery; and 3) Uniform Sampling Alignment, which aligns the sampling density between street and satellite views. Evaluated on Occ3D-nuScenes, SA-Occ achieves state-of-the-art performance, especially among single-frame methods, with a 39.05% mIoU (a 6.97% improvement), while incurring only 6.93 ms of additional latency per frame. Our code and newly curated dataset are available at https://github.com/chenchen235/SA-Occ.
Can Large Language Models Unveil the Mysteries? An Exploration of Their Ability to Unlock Information in Complex Scenarios
Feb 27, 2025Combining multiple perceptual inputs and performing combinatorial reasoning in complex scenarios is a sophisticated cognitive function in humans. With advancements in multi-modal large language models, recent benchmarks tend to evaluate visual understanding across multiple images. However, they often overlook the necessity of combinatorial reasoning across multiple perceptual information. To explore the ability of advanced models to integrate multiple perceptual inputs for combinatorial reasoning in complex scenarios, we introduce two benchmarks: Clue-Visual Question Answering (CVQA), with three task types to assess visual comprehension and synthesis, and Clue of Password-Visual Question Answering (CPVQA), with two task types focused on accurate interpretation and application of visual data. For our benchmarks, we present three plug-and-play approaches: utilizing model input for reasoning, enhancing reasoning through minimum margin decoding with randomness generation, and retrieving semantically relevant visual information for effective data integration. The combined results reveal current models' poor performance on combinatorial reasoning benchmarks, even the state-of-the-art (SOTA) closed-source model achieves only 33.04% accuracy on CVQA, and drops to 7.38% on CPVQA. Notably, our approach improves the performance of models on combinatorial reasoning, with a 22.17% boost on CVQA and 9.40% on CPVQA over the SOTA closed-source model, demonstrating its effectiveness in enhancing combinatorial reasoning with multiple perceptual inputs in complex scenarios. The code will be publicly available.