 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViRefSAM: Visual Reference-Guided Segment Anything Model for Remote Sensing Segmentation
Jul 03, 2025The Segment Anything Model (SAM), with its prompt-driven paradigm, exhibits strong generalization in generic segmentation tasks. However, applying SAM to remote sensing (RS) images still faces two major challenges. First, manually constructing precise prompts for each image (e.g., points or boxes) is labor-intensive and inefficient, especially in RS scenarios with dense small objects or spatially fragmented distributions. Second, SAM lacks domain adaptability, as it is pre-trained primarily on natural images and struggles to capture RS-specific semantics and spatial characteristics, especially when segmenting novel or unseen classes. To address these issues, inspired by few-shot learning, we propose ViRefSAM, a novel framework that guides SAM utilizing only a few annotated reference images that contain class-specific objects. Without requiring manual prompts, ViRefSAM enables automatic segmentation of class-consistent objects across RS images. Specifically, ViRefSAM introduces two key components while keeping SAM's original architecture intact: (1) a Visual Contextual Prompt Encoder that extracts class-specific semantic clues from reference images and generates object-aware prompts via contextual interaction with target images; and (2) a Dynamic Target Alignment Adapter, integrated into SAM's image encoder, which mitigates the domain gap by injecting class-specific semantics into target image features, enabling SAM to dynamically focus on task-relevant regions. Extensive experiments on three few-shot segmentation benchmarks, including iSAID-5$^i$, LoveDA-2$^i$, and COCO-20$^i$, demonstrate that ViRefSAM enables accurate and automatic segmentation of unseen classes by leveraging only a few reference images and consistently outperforms existing few-shot segmentation methods across diverse datasets.
AgMTR: Agent Mining Transformer for Few-shot Segmentation in Remote Sensing
Sep 26, 2024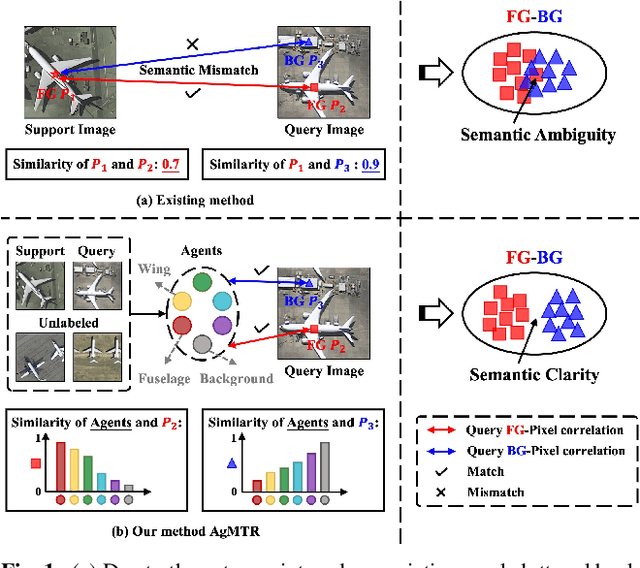
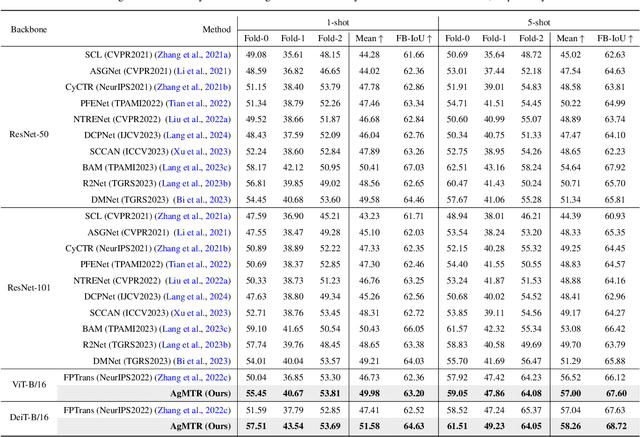
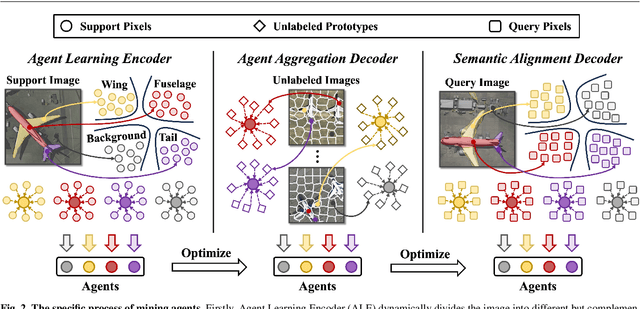
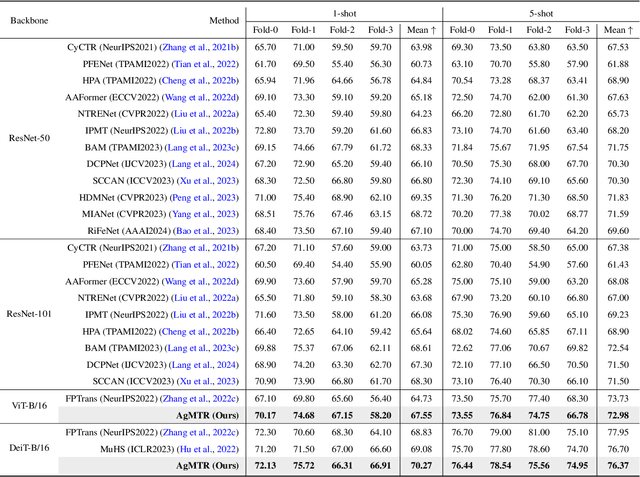
Few-shot Segmentation (FSS) aims to segment the interested objects in the query image with just a handful of labeled samples (i.e., support images). Previous schemes would leverage the similarity between support-query pixel pairs to construct the pixel-level semantic correlation. However, in remote sensing scenarios with extreme intra-class variations and cluttered backgrounds, such pixel-level correlations may produce tremendous mismatches, resulting in semantic ambiguity between the query foreground (FG) and background (BG) pixels. To tackle this problem, we propose a novel Agent Mining Transformer (AgMTR), which adaptively mines a set of local-aware agents to construct agent-level semantic correlation. Compared with pixel-level semantics, the given agents are equipped with local-contextual information and possess a broader receptive field. At this point, different query pixels can selectively aggregate the fine-grained local semantics of different agents, thereby enhancing the semantic clarity between query FG and BG pixels. Concretely, the Agent Learning Encoder (ALE) is first proposed to erect the optimal transport plan that arranges different agents to aggregate support semantics under different local regions. Then, for further optimizing the agents, the Agent Aggregation Decoder (AAD) and the Semantic Alignment Decoder (SAD) are constructed to break through the limited support set for mining valuable class-specific semantics from unlabeled data sources and the query image itself, respectively. Extensive experiments on the remote sensing benchmark iSAID indicate that the proposed method achieves state-of-the-art performance. Surprisingly, our method remains quite competitive when extended to more common natural scenarios, i.e., PASCAL-5i and COCO-20i.
Prompt-and-Transfer: Dynamic Class-aware Enhancement for Few-shot Segmentation
Sep 16, 2024For more efficient generalization to unseen domains (classes), most Few-shot Segmentation (FSS) would directly exploit pre-trained encoders and only fine-tune the decoder, especially in the current era of large models. However, such fixed feature encoders tend to be class-agnostic, inevitably activating objects that are irrelevant to the target class. In contrast, humans can effortlessly focus on specific objects in the line of sight. This paper mimics the visual perception pattern of human beings and proposes a novel and powerful prompt-driven scheme, called ``Prompt and Transfer" (PAT), which constructs a dynamic class-aware prompting paradigm to tune the encoder for focusing on the interested object (target class) in the current task. Three key points are elaborated to enhance the prompting: 1) Cross-modal linguistic information is introduced to initialize prompts for each task. 2) Semantic Prompt Transfer (SPT) that precisely transfers the class-specific semantics within the images to prompts. 3) Part Mask Generator (PMG) that works in conjunction with SPT to adaptively generate different but complementary part prompts for different individuals. Surprisingly, PAT achieves competitive performance on 4 different tasks including standard FSS, Cross-domain FSS (e.g., CV, medical, and remote sensing domains), Weak-label FSS, and Zero-shot Segmentation, setting new state-of-the-arts on 11 benchmarks.
Not Just Learning from Others but Relying on Yourself: A New Perspective on Few-Shot Segmentation in Remote Sensing
Oct 19, 2023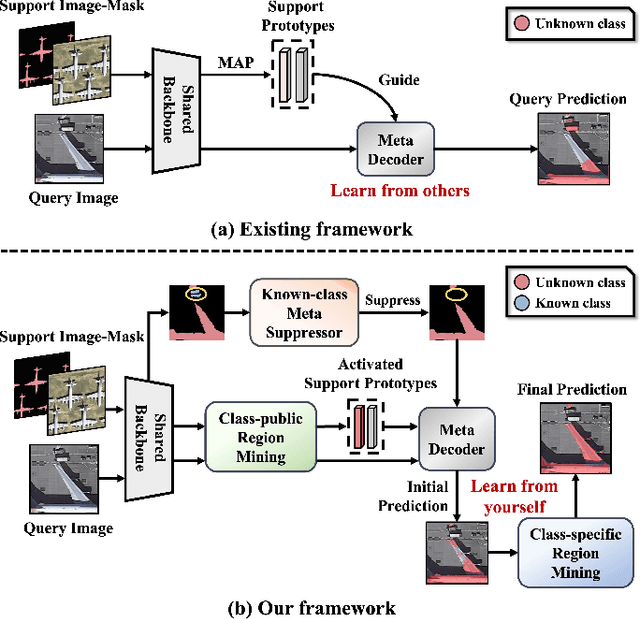


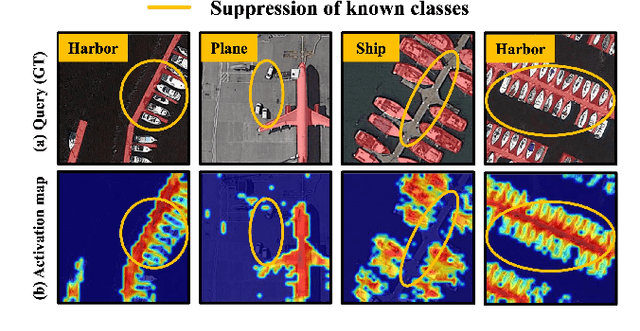
Few-shot segmentation (FSS) is proposed to segment unknown class targets with just a few annotated samples. Most current FSS methods follow the paradigm of mining the semantics from the support images to guide the query image segmentation. However, such a pattern of `learning from others' struggles to handle the extreme intra-class variation, preventing FSS from being directly generalized to remote sensing scenes. To bridge the gap of intra-class variance, we develop a Dual-Mining network named DMNet for cross-image mining and self-mining, meaning that it no longer focuses solely on support images but pays more attention to the query image itself. Specifically, we propose a Class-public Region Mining (CPRM) module to effectively suppress irrelevant feature pollution by capturing the common semantics between the support-query image pair. The Class-specific Region Mining (CSRM) module is then proposed to continuously mine the class-specific semantics of the query image itself in a `filtering' and `purifying' manner. In addition, to prevent the co-existence of multiple classes in remote sensing scenes from exacerbating the collapse of FSS generalization, we also propose a new Known-class Meta Suppressor (KMS) module to suppress the activation of known-class objects in the sample. Extensive experiments on the iSAID and LoveDA remote sensing datasets have demonstrated that our method sets the state-of-the-art with a minimum number of model parameters. Significantly, our model with the backbone of Resnet-50 achieves the mIoU of 49.58% and 51.34% on iSAID under 1-shot and 5-shot settings, outperforming the state-of-the-art method by 1.8% and 1.12%, respectively. The code is publicly available at https://github.com/HanboBizl/DMNet.
RingMo-lite: A Remote Sensing Multi-task Lightweight Network with CNN-Transformer Hybrid Framework
Sep 16, 2023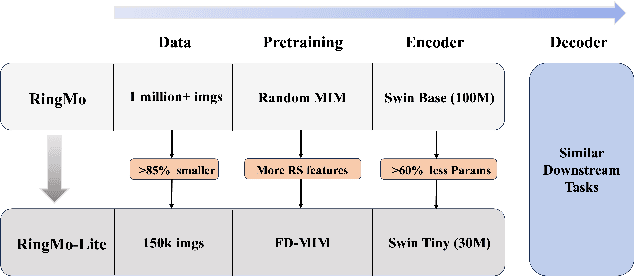
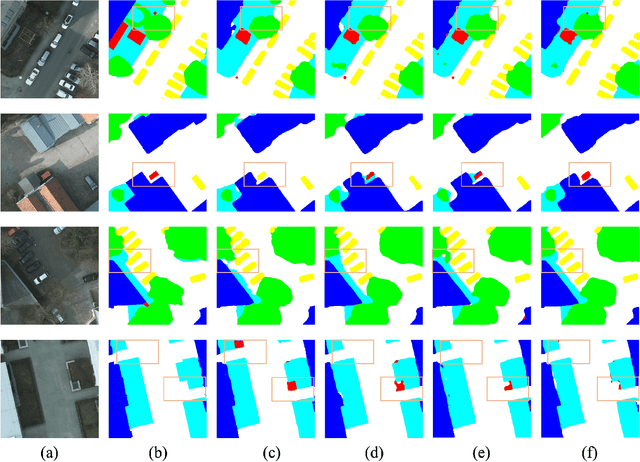
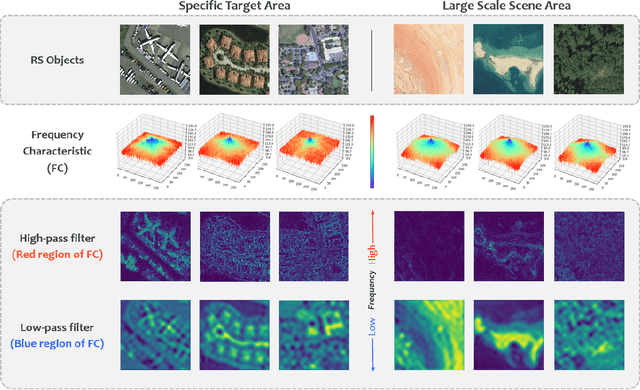
In recent years, remote sensing (RS) vision foundation models such as RingMo have emerged and achieved excellent performance in various downstream tasks. However, the high demand for computing resources limits the application of these models on edge devices. It is necessary to design a more lightweight foundation model to support on-orbit RS image interpretation. Existing methods face challenges in achieving lightweight solutions while retaining generalization in RS image interpretation. This is due to the complex high and low-frequency spectral components in RS images, which make traditional single CNN or Vision Transformer methods unsuitable for the task. Therefore, this paper proposes RingMo-lite, an RS multi-task lightweight network with a CNN-Transformer hybrid framework, which effectively exploits the frequency-domain properties of RS to optimize the interpretation process. It is combined by the Transformer module as a low-pass filter to extract global features of RS images through a dual-branch structure, and the CNN module as a stacked high-pass filter to extract fine-grained details effectively. Furthermore, in the pretraining stage, the designed frequency-domain masked image modeling (FD-MIM) combines each image patch's high-frequency and low-frequency characteristics, effectively capturing the latent feature representation in RS data. As shown in Fig. 1, compared with RingMo, the proposed RingMo-lite reduces the parameters over 60% in various RS image interpretation tasks, the average accuracy drops by less than 2% in most of the scenes and achieves SOTA performance compared to models of the similar size. In addition, our work will be integrated into the MindSpore computing platform in the near future.
Learning to Evaluate Performance of Multi-modal Semantic Localization
Sep 19, 2022
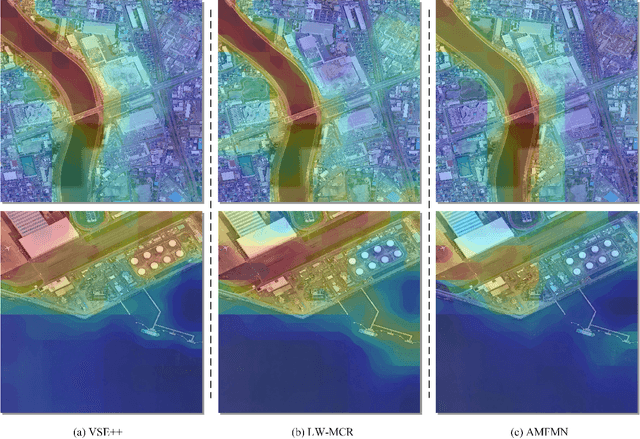
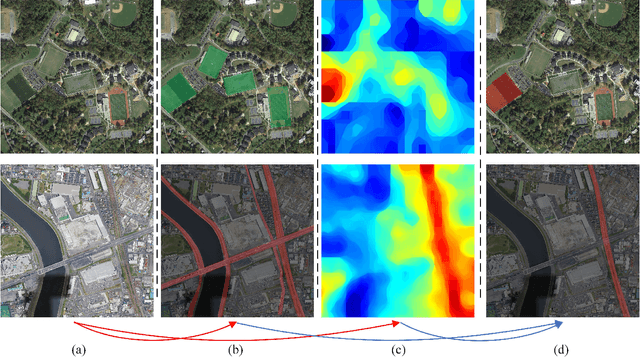
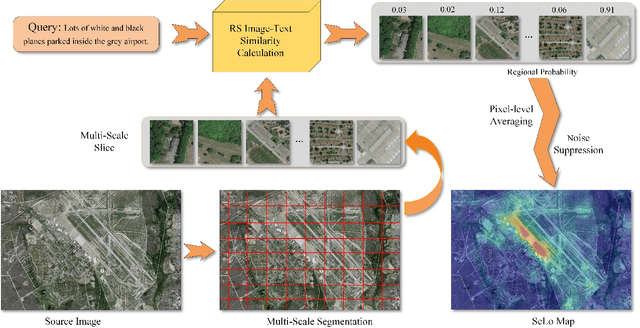
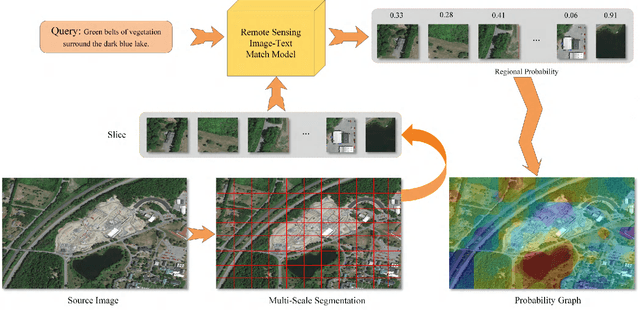
Semantic localization (SeLo) refers to the task of obtaining the most relevant locations in large-scale remote sensing (RS) images using semantic information such as text. As an emerging task based on cross-modal retrieval, SeLo achieves semantic-level retrieval with only caption-level annotation, which demonstrates its great potential in unifying downstream tasks. Although SeLo has been carried out successively, but there is currently no work has systematically explores and analyzes this urgent direction. In this paper, we thoroughly study this field and provide a complete benchmark in terms of metrics and testdata to advance the SeLo task. Firstly, based on the characteristics of this task, we propose multiple discriminative evaluation metrics to quantify the performance of the SeLo task. The devised significant area proportion, attention shift distance, and discrete attention distance are utilized to evaluate the generated SeLo map from pixel-level and region-level. Next, to provide standard evaluation data for the SeLo task, we contribute a diverse, multi-semantic, multi-objective Semantic Localization Testset (AIR-SLT). AIR-SLT consists of 22 large-scale RS images and 59 test cases with different semantics, which aims to provide a comprehensive evaluations for retrieval models. Finally, we analyze the SeLo performance of RS cross-modal retrieval models in detail, explore the impact of different variables on this task, and provide a complete benchmark for the SeLo task. We have also established a new paradigm for RS referring expression comprehension, and demonstrated the great advantage of SeLo in semantics through combining it with tasks such as detection and road extraction. The proposed evaluation metrics, semantic localization testsets, and corresponding scripts have been open to access at github.com/xiaoyuan1996/SemanticLocalizationMetrics .
Exploring a Fine-Grained Multiscale Method for Cross-Modal Remote Sensing Image Retrieval
Apr 21, 2022
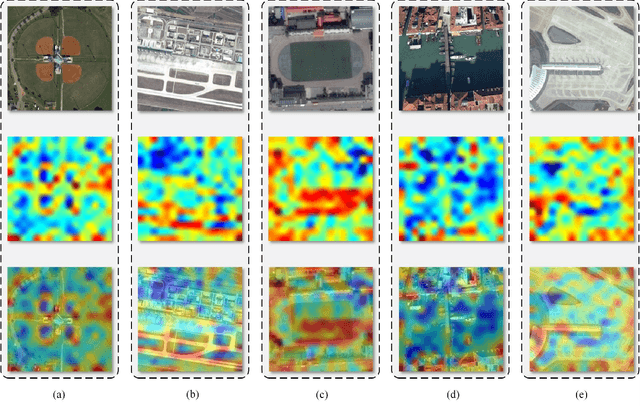
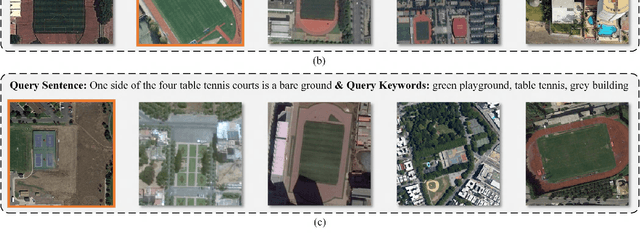
Remote sensing (RS) cross-modal text-image retrieval has attracted extensive attention for its advantages of flexible input and efficient query. However, traditional methods ignore the characteristics of multi-scale and redundant targets in RS image, leading to the degradation of retrieval accuracy. To cope with the problem of multi-scale scarcity and target redundancy in RS multimodal retrieval task, we come up with a novel asymmetric multimodal feature matching network (AMFMN). Our model adapts to multi-scale feature inputs, favors multi-source retrieval methods, and can dynamically filter redundant features. AMFMN employs the multi-scale visual self-attention (MVSA) module to extract the salient features of RS image and utilizes visual features to guide the text representation. Furthermore, to alleviate the positive samples ambiguity caused by the strong intraclass similarity in RS image, we propose a triplet loss function with dynamic variable margin based on prior similarity of sample pairs. Finally, unlike the traditional RS image-text dataset with coarse text and higher intraclass similarity, we construct a fine-grained and more challenging Remote sensing Image-Text Match dataset (RSITMD), which supports RS image retrieval through keywords and sentence separately and jointly. Experiments on four RS text-image datasets demonstrate that the proposed model can achieve state-of-the-art performance in cross-modal RS text-image retrieval task.
Remote Sensing Cross-Modal Text-Image Retrieval Based on Global and Local Information
Apr 21, 2022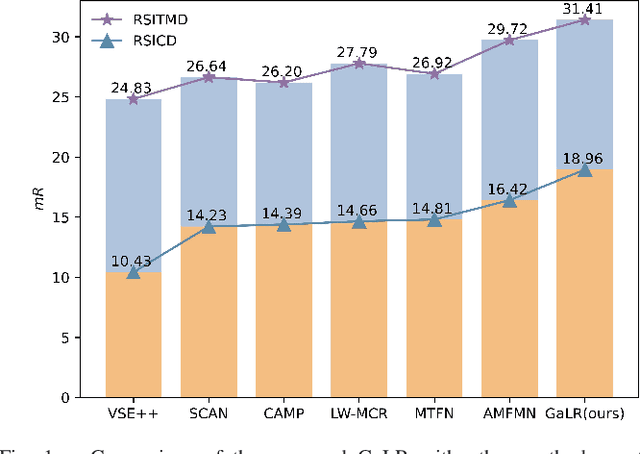
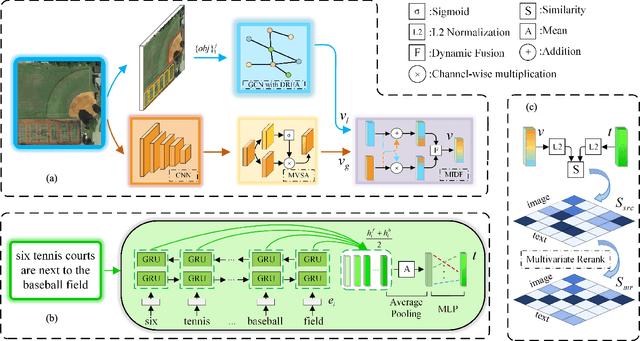
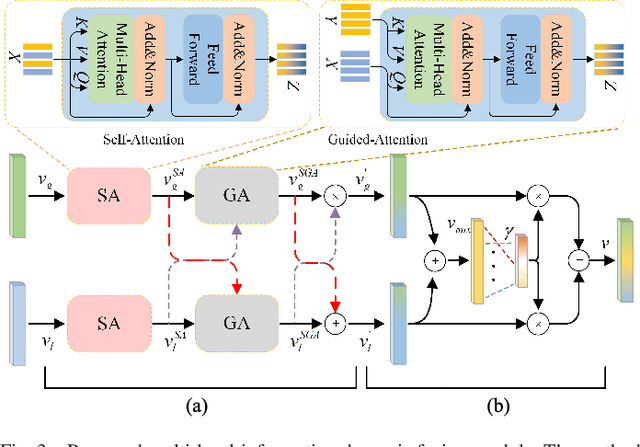
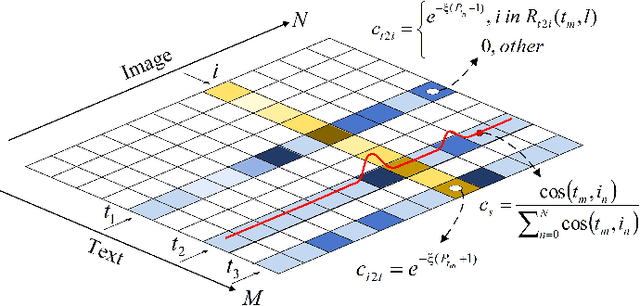
Cross-modal remote sensing text-image retrieval (RSCTIR) has recently become an urgent research hotspot due to its ability of enabling fast and flexible information extraction on remote sensing (RS) images. However, current RSCTIR methods mainly focus on global features of RS images, which leads to the neglect of local features that reflect target relationships and saliency. In this article, we first propose a novel RSCTIR framework based on global and local information (GaLR), and design a multi-level information dynamic fusion (MIDF) module to efficaciously integrate features of different levels. MIDF leverages local information to correct global information, utilizes global information to supplement local information, and uses the dynamic addition of the two to generate prominent visual representation. To alleviate the pressure of the redundant targets on the graph convolution network (GCN) and to improve the model s attention on salient instances during modeling local features, the de-noised representation matrix and the enhanced adjacency matrix (DREA) are devised to assist GCN in producing superior local representations. DREA not only filters out redundant features with high similarity, but also obtains more powerful local features by enhancing the features of prominent objects. Finally, to make full use of the information in the similarity matrix during inference, we come up with a plug-and-play multivariate rerank (MR) algorithm. The algorithm utilizes the k nearest neighbors of the retrieval results to perform a reverse search, and improves the performance by combining multiple components of bidirectional retrieval. Extensive experiments on public datasets strongly demonstrate the state-of-the-art performance of GaLR methods on the RSCTIR task. The code of GaLR method, MR algorithm, and corresponding files have been made available at https://github.com/xiaoyuan1996/GaLR .
Oriented Objects as pairs of Middle Lines
Dec 24, 2019
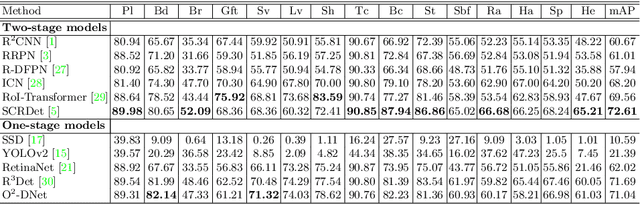
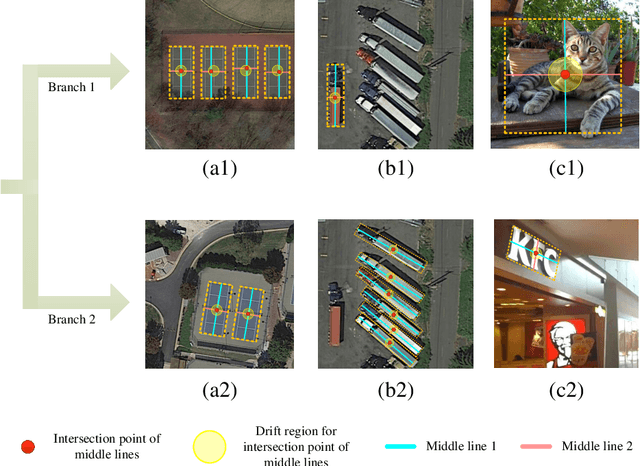
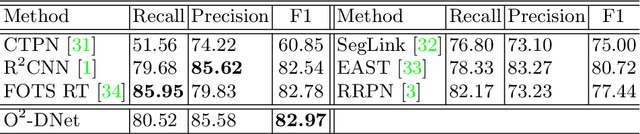
The detection of oriented objects is frequently appeared in the field of natural scene text detection as well as object detection in aerial images. Traditional detectors for oriented objects are common to rotate anchors on the basis of the RCNN frameworks, which will multiple the number of anchors with a variety of angles, coupled with rotating NMS algorithm, the computational complexities of these models are greatly increased. In this paper, we propose a novel model named Oriented Objects Detection Network O^2-DNet to detect oriented objects by predicting a pair of middle lines inside each target. O^2-DNet is an one-stage, anchor-free and NMS-free model. The target line segments of our model are defined as two corresponding middle lines of original rotating bounding box annotations which can be transformed directly instead of additional manual tagging. Experiments show that our O^2-DNet achieves excellent performance on ICDAR 2015 and DOTA datasets. It is noteworthy that the objects in COCO can be regard as a special form of oriented objects with an angle of 90 degrees. O^2-DNet can still achieve competitive results in these general natural object detection datasets.
A novel transfer learning method based on common space mapping and weighted domain matching
Aug 16, 2016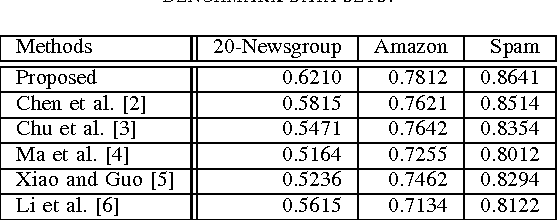
In this paper, we propose a novel learning framework for the problem of domain transfer learning. We map the data of two domains to one single common space, and learn a classifier in this common space. Then we adapt the common classifier to the two domains by adding two adaptive functions to it respectively. In the common space, the target domain data points are weighted and matched to the target domain in term of distributions. The weighting terms of source domain data points and the target domain classification responses are also regularized by the local reconstruction coefficients. The novel transfer learning framework is evaluated over some benchmark cross-domain data sets, and it outperforms the existing state-of-the-art transfer learning methods.