 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effects of Adversarial Perturbations on Distribution Robustness
Jan 23, 2026Adversarial robustness refers to a model's ability to resist perturbation of inputs, while distribution robustness evaluates the performance of the model under data shifts. Although both aim to ensure reliable performance, prior work has revealed a tradeoff in distribution and adversarial robustness. Specifically, adversarial training might increase reliance on spurious features, which can harm distribution robustness, especially the performance on some underrepresented subgroups. We present a theoretical analysis of adversarial and distribution robustness that provides a tractable surrogate for per-step adversarial training by studying models trained on perturbed data. In addition to the tradeoff, our work further identified a nuanced phenomenon that $\ell_\infty$ perturbations on data with moderate bias can yield an increase in distribution robustness. Moreover, the gain in distribution robustness remains on highly skewed data when simplicity bias induces reliance on the core feature, characterized as greater feature separability. Our theoretical analysis extends the understanding of the tradeoff by highlighting the interplay of the tradeoff and the feature separability. Despite the tradeoff that persists in many cases, overlooking the role of feature separability may lead to misleading conclusions about robustness.
MASSW: A New Dataset and Benchmark Tasks for AI-Assisted Scientific Workflows
Jun 10, 2024



Scientific innovation relies on detailed workflows, which include critical steps such as analyzing literature, generating ideas, validating these ideas, interpreting results, and inspiring follow-up research. However, scientific publications that document these workflows are extensive and unstructured. This makes it difficult for both human researchers and AI systems to effectively navigate and explore the space of scientific innovation. To address this issue, we introduce MASSW, a comprehensive text dataset on Multi-Aspect Summarization of Scientific Workflows. MASSW includes more than 152,000 peer-reviewed publications from 17 leading computer science conferences spanning the past 50 years. Using Large Language Models (LLMs), we automatically extract five core aspects from these publications -- context, key idea, method, outcome, and projected impact -- which correspond to five key steps in the research workflow. These structured summaries facilitate a variety of downstream tasks and analyses. The quality of the LLM-extracted summaries is validated by comparing them with human annotations. We demonstrate the utility of MASSW through multiple novel machine-learning tasks that can be benchmarked using this new dataset, which make various types of predictions and recommendations along the scientific workflow. MASSW holds significant potential for researchers to create and benchmark new AI methods for optimizing scientific workflows and fostering scientific innovation in the field. Our dataset is openly available at \url{https://github.com/xingjian-zhang/massw}.
Self-Supervised Motion Magnification by Backpropagating Through Optical Flow
Nov 28, 2023This paper presents a simple, self-supervised method for magnifying subtle motions in video: given an input video and a magnification factor, we manipulate the video such that its new optical flow is scaled by the desired amount. To train our model, we propose a loss function that estimates the optical flow of the generated video and penalizes how far if deviates from the given magnification factor. Thus, training involves differentiating through a pretrained optical flow network. Since our model is self-supervised, we can further improve its performance through test-time adaptation, by finetuning it on the input video. It can also be easily extended to magnify the motions of only user-selected objects. Our approach avoids the need for synthetic magnification datasets that have been used to train prior learning-based approaches. Instead, it leverages the existing capabilities of off-the-shelf motion estimators. We demonstrate the effectiveness of our method through evaluations of both visual quality and quantitative metrics on a range of real-world and synthetic videos, and we show our method works for both supervised and unsupervised optical flow methods.
A Prompt Log Analysis of Text-to-Image Generation Systems
Mar 16, 2023

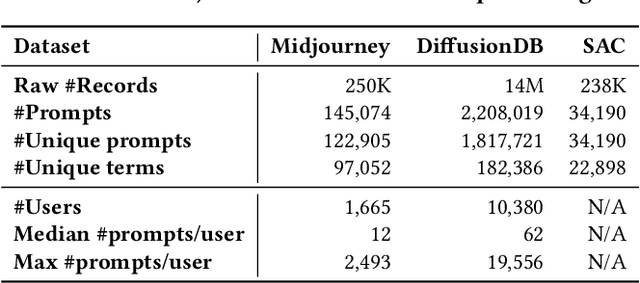

Recent developments in large language models (LLM) and generative AI have unleashed the astonishing capabilities of text-to-image generation systems to synthesize high-quality images that are faithful to a given reference text, known as a "prompt". These systems have immediately received lots of attention from researchers, creators, and common users. Despite the plenty of efforts to improve the generative models, there is limited work on understanding the information needs of the users of these systems at scale. We conduct the first comprehensive analysis of large-scale prompt logs collected from multiple text-to-image generation systems. Our work is analogous to analyzing the query logs of Web search engines, a line of work that has made critical contributions to the glory of the Web search industry and research. Compared with Web search queries, text-to-image prompts are significantly longer, often organized into special structures that consist of the subject, form, and intent of the generation tasks and present unique categories of information needs. Users make more edits within creation sessions, which present remarkable exploratory patterns. There is also a considerable gap between the user-input prompts and the captions of the images included in the open training data of the generative models. Our findings provide concrete implications on how to improve text-to-image generation systems for creation purposes.
Face Animation with Multiple Source Images
Dec 01, 2022Face animation has received a lot of attention from researchers in recent years due to its wide range of promising applications. Many face animation models based on optical flow or deep neural networks have achieved great success. However, these models are likely to fail in animated scenarios with significant view changes, resulting in unrealistic or distorted faces. One of the possible reasons is that such models lack prior knowledge of human faces and are not proficient to imagine facial regions they have never seen before. In this paper, we propose a flexible and generic approach to improve the performance of face animation without additional training. We use multiple source images as input as compensation for the lack of prior knowledge of faces. The effectiveness of our method is experimentally demonstrated, where the proposed method successfully supplements the baseline method.
Learning to Evaluate Performance of Multi-modal Semantic Localization
Sep 19, 2022
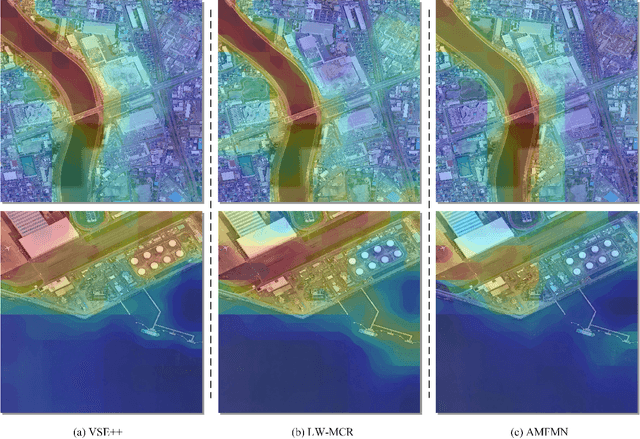
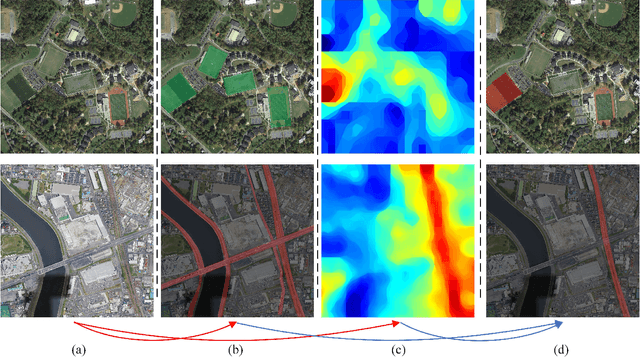
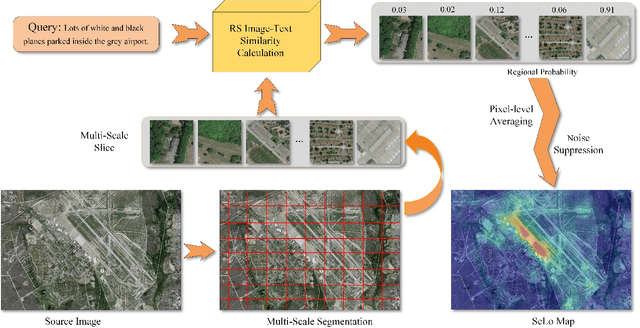
Semantic localization (SeLo) refers to the task of obtaining the most relevant locations in large-scale remote sensing (RS) images using semantic information such as text. As an emerging task based on cross-modal retrieval, SeLo achieves semantic-level retrieval with only caption-level annotation, which demonstrates its great potential in unifying downstream tasks. Although SeLo has been carried out successively, but there is currently no work has systematically explores and analyzes this urgent direction. In this paper, we thoroughly study this field and provide a complete benchmark in terms of metrics and testdata to advance the SeLo task. Firstly, based on the characteristics of this task, we propose multiple discriminative evaluation metrics to quantify the performance of the SeLo task. The devised significant area proportion, attention shift distance, and discrete attention distance are utilized to evaluate the generated SeLo map from pixel-level and region-level. Next, to provide standard evaluation data for the SeLo task, we contribute a diverse, multi-semantic, multi-objective Semantic Localization Testset (AIR-SLT). AIR-SLT consists of 22 large-scale RS images and 59 test cases with different semantics, which aims to provide a comprehensive evaluations for retrieval models. Finally, we analyze the SeLo performance of RS cross-modal retrieval models in detail, explore the impact of different variables on this task, and provide a complete benchmark for the SeLo task. We have also established a new paradigm for RS referring expression comprehension, and demonstrated the great advantage of SeLo in semantics through combining it with tasks such as detection and road extraction. The proposed evaluation metrics, semantic localization testsets, and corresponding scripts have been open to access at github.com/xiaoyuan1996/SemanticLocalizationMetrics .