 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMD: Controllable Multiview Diffusion for 3D Editing and Progressive Generation
May 11, 2025Recently, 3D generation methods have shown their powerful ability to automate 3D model creation. However, most 3D generation methods only rely on an input image or a text prompt to generate a 3D model, which lacks the control of each component of the generated 3D model. Any modifications of the input image lead to an entire regeneration of the 3D models. In this paper, we introduce a new method called CMD that generates a 3D model from an input image while enabling flexible local editing of each component of the 3D model. In CMD, we formulate the 3D generation as a conditional multiview diffusion model, which takes the existing or known parts as conditions and generates the edited or added components. This conditional multiview diffusion model not only allows the generation of 3D models part by part but also enables local editing of 3D models according to the local revision of the input image without changing other 3D parts. Extensive experiments are conducted to demonstrate that CMD decomposes a complex 3D generation task into multiple components, improving the generation quality. Meanwhile, CMD enables efficient and flexible local editing of a 3D model by just editing one rendered image.
A Resource-Efficient Training Framework for Remote Sensing Text--Image Retrieval
Jan 18, 2025



Remote sensing text--image retrieval (RSTIR) aims to retrieve the matched remote sensing (RS) images from the database according to the descriptive text. Recently, the rapid development of large visual-language pre-training models provides new insights for RSTIR. Nevertheless, as the complexity of models grows in RSTIR, the previous studies suffer from suboptimal resource efficiency during transfer learning. To address this issue, we propose a computation and memory-efficient retrieval (CMER) framework for RSTIR. To reduce the training memory consumption, we propose the Focus-Adapter module, which adopts a side branch structure. Its focus layer suppresses the interference of background pixels for small targets. Simultaneously, to enhance data efficacy, we regard the RS scene category as the metadata and design a concise augmentation technique. The scene label augmentation leverages the prior knowledge from land cover categories and shrinks the search space. We propose the negative sample recycling strategy to make the negative sample pool decoupled from the mini-batch size. It improves the generalization performance without introducing additional encoders. We have conducted quantitative and qualitative experiments on public datasets and expanded the benchmark with some advanced approaches, which demonstrates the competitiveness of the proposed CMER. Compared with the recent advanced methods, the overall retrieval performance of CMER is 2%--5% higher on RSITMD. Moreover, our proposed method reduces memory consumption by 49% and has a 1.4x data throughput during training. The code of the CMER and the dataset will be released at https://github.com/ZhangWeihang99/CMER.
Learning to Evaluate Performance of Multi-modal Semantic Localization
Sep 19, 2022
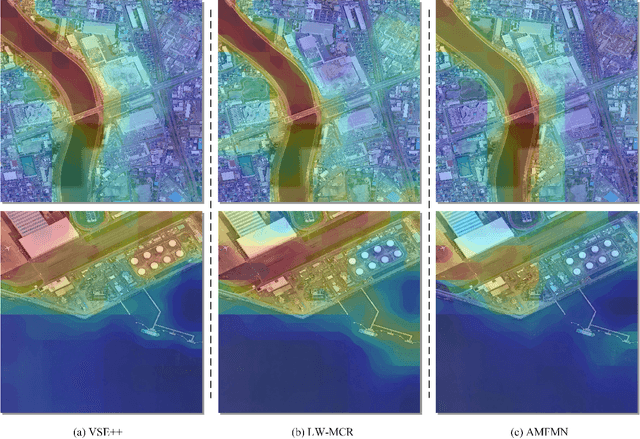
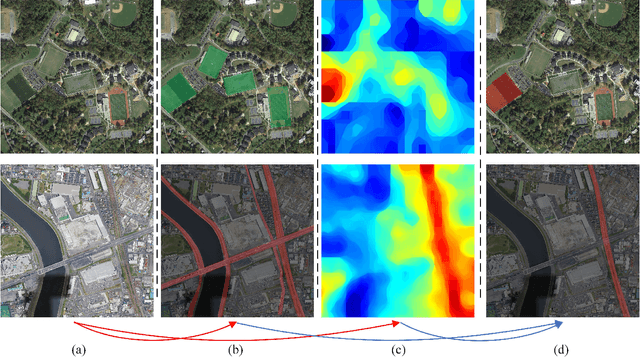
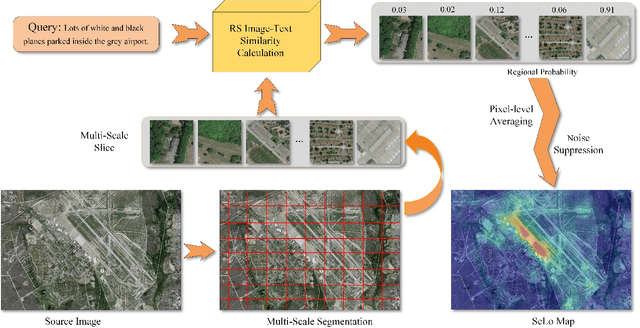
Semantic localization (SeLo) refers to the task of obtaining the most relevant locations in large-scale remote sensing (RS) images using semantic information such as text. As an emerging task based on cross-modal retrieval, SeLo achieves semantic-level retrieval with only caption-level annotation, which demonstrates its great potential in unifying downstream tasks. Although SeLo has been carried out successively, but there is currently no work has systematically explores and analyzes this urgent direction. In this paper, we thoroughly study this field and provide a complete benchmark in terms of metrics and testdata to advance the SeLo task. Firstly, based on the characteristics of this task, we propose multiple discriminative evaluation metrics to quantify the performance of the SeLo task. The devised significant area proportion, attention shift distance, and discrete attention distance are utilized to evaluate the generated SeLo map from pixel-level and region-level. Next, to provide standard evaluation data for the SeLo task, we contribute a diverse, multi-semantic, multi-objective Semantic Localization Testset (AIR-SLT). AIR-SLT consists of 22 large-scale RS images and 59 test cases with different semantics, which aims to provide a comprehensive evaluations for retrieval models. Finally, we analyze the SeLo performance of RS cross-modal retrieval models in detail, explore the impact of different variables on this task, and provide a complete benchmark for the SeLo task. We have also established a new paradigm for RS referring expression comprehension, and demonstrated the great advantage of SeLo in semantics through combining it with tasks such as detection and road extraction. The proposed evaluation metrics, semantic localization testsets, and corresponding scripts have been open to access at github.com/xiaoyuan1996/SemanticLocalizationMetrics .