 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Resource-Efficient Training Framework for Remote Sensing Text--Image Retrieval
Jan 18, 2025



Remote sensing text--image retrieval (RSTIR) aims to retrieve the matched remote sensing (RS) images from the database according to the descriptive text. Recently, the rapid development of large visual-language pre-training models provides new insights for RSTIR. Nevertheless, as the complexity of models grows in RSTIR, the previous studies suffer from suboptimal resource efficiency during transfer learning. To address this issue, we propose a computation and memory-efficient retrieval (CMER) framework for RSTIR. To reduce the training memory consumption, we propose the Focus-Adapter module, which adopts a side branch structure. Its focus layer suppresses the interference of background pixels for small targets. Simultaneously, to enhance data efficacy, we regard the RS scene category as the metadata and design a concise augmentation technique. The scene label augmentation leverages the prior knowledge from land cover categories and shrinks the search space. We propose the negative sample recycling strategy to make the negative sample pool decoupled from the mini-batch size. It improves the generalization performance without introducing additional encoders. We have conducted quantitative and qualitative experiments on public datasets and expanded the benchmark with some advanced approaches, which demonstrates the competitiveness of the proposed CMER. Compared with the recent advanced methods, the overall retrieval performance of CMER is 2%--5% higher on RSITMD. Moreover, our proposed method reduces memory consumption by 49% and has a 1.4x data throughput during training. The code of the CMER and the dataset will be released at https://github.com/ZhangWeihang99/CMER.
RingMo-lite: A Remote Sensing Multi-task Lightweight Network with CNN-Transformer Hybrid Framework
Sep 16, 2023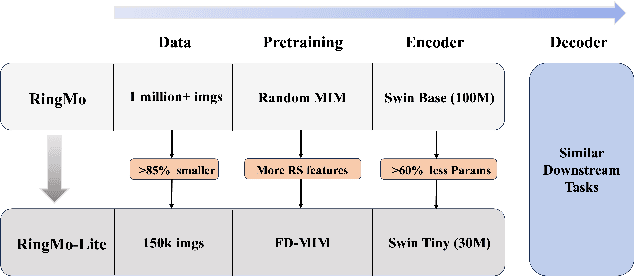
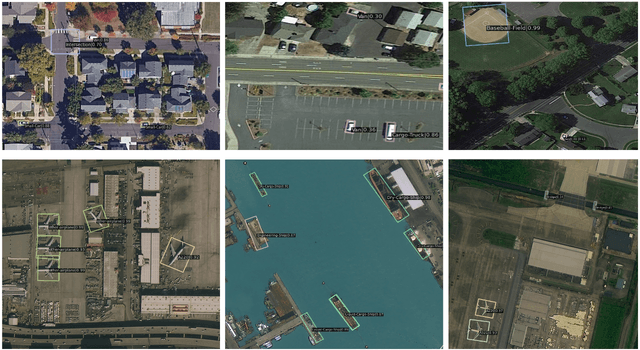
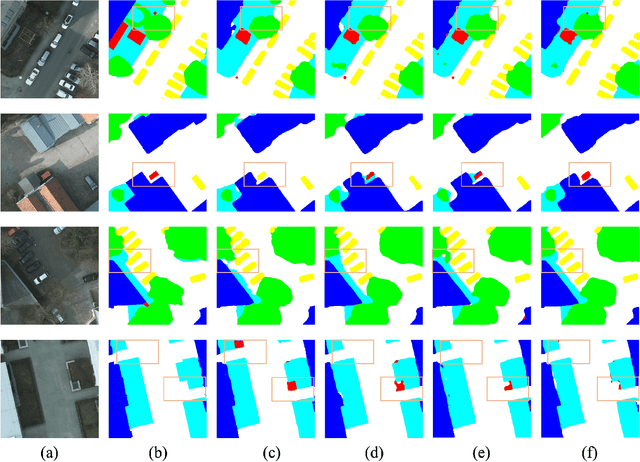
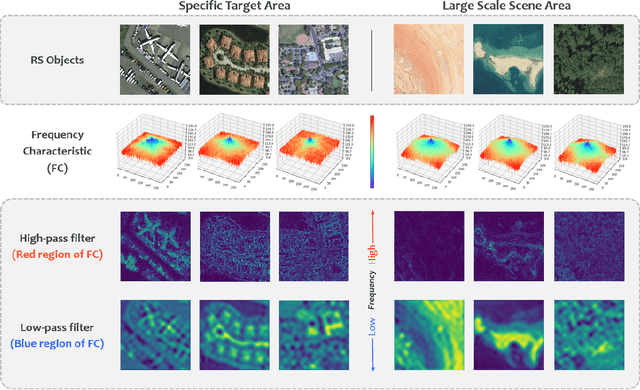
In recent years, remote sensing (RS) vision foundation models such as RingMo have emerged and achieved excellent performance in various downstream tasks. However, the high demand for computing resources limits the application of these models on edge devices. It is necessary to design a more lightweight foundation model to support on-orbit RS image interpretation. Existing methods face challenges in achieving lightweight solutions while retaining generalization in RS image interpretation. This is due to the complex high and low-frequency spectral components in RS images, which make traditional single CNN or Vision Transformer methods unsuitable for the task. Therefore, this paper proposes RingMo-lite, an RS multi-task lightweight network with a CNN-Transformer hybrid framework, which effectively exploits the frequency-domain properties of RS to optimize the interpretation process. It is combined by the Transformer module as a low-pass filter to extract global features of RS images through a dual-branch structure, and the CNN module as a stacked high-pass filter to extract fine-grained details effectively. Furthermore, in the pretraining stage, the designed frequency-domain masked image modeling (FD-MIM) combines each image patch's high-frequency and low-frequency characteristics, effectively capturing the latent feature representation in RS data. As shown in Fig. 1, compared with RingMo, the proposed RingMo-lite reduces the parameters over 60% in various RS image interpretation tasks, the average accuracy drops by less than 2% in most of the scenes and achieves SOTA performance compared to models of the similar size. In addition, our work will be integrated into the MindSpore computing platform in the near future.