 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexLink Hand: A Compact, Affordable, 16-DOF Linkage-Driven Hand with Human-Like Dexterity
Jun 16, 2026Dexterous robotic hands face a longstanding trade-off among dexterity, compactness, and affordability. Particularly, high-degree-of-freedom designs typically demand complex actuation and transmission, hindering integration into human-scale forms. To address these challenges, this work presents a compact, low-cost linkage-driven anthropomorphic hand that achieves high dexterity, structural integration, and human-hand-like functionality. The hand integrates 20 joints driven by 16 independent actuators, with all actuation, sensing, and transmission components compactly embedded within a human-hand-sized structure. The resulting prototype weighs only 320g at a total cost below USD 400. To meet these objectives, a hybrid mechanical architecture combining planar and spatial linkage mechanisms is proposed, enabling decoupled multidirectional motion, biomimetic joint synergies, and high passive load-bearing capability. The thumb further incorporates biomimetic features supporting human-like reconfiguration and opposition movements. Through the coordinated integration of these mechanisms and structural layout, the prototype achieves a highly integrated design with anthropomorphic dexterity. Experimental evaluations demonstrate that the hand achieves the maximum Kapandji score, reproduces all 33 Feix grasp types, and performs stable grasping and dexterous manipulation across a wide variety of daily objects and tools. These results validate the proposed hand as an affordable, compact, and mechanically efficient platform for dexterous manipulation, teleoperation, and robot learning in human-centered environments.
Construction of a Multiple-DOF Under-actuated Gripper with Force-Sensing via Deep Learning
Jun 13, 2025We present a novel under-actuated gripper with two 3-joint fingers, which realizes force feedback control by the deep learning technique- Long Short-Term Memory (LSTM) model, without any force sensor. First, a five-linkage mechanism stacked by double four-linkages is designed as a finger to automatically achieve the transformation between parallel and enveloping grasping modes. This enables the creation of a low-cost under-actuated gripper comprising a single actuator and two 3-phalange fingers. Second, we devise theoretical models of kinematics and power transmission based on the proposed gripper, accurately obtaining fingertip positions and contact forces. Through coupling and decoupling of five-linkage mechanisms, the proposed gripper offers the expected capabilities of grasping payload/force/stability and objects with large dimension ranges. Third, to realize the force control, an LSTM model is proposed to determine the grasping mode for synthesizing force-feedback control policies that exploit contact sensing after outlining the uncertainty of currents using a statistical method. Finally, a series of experiments are implemented to measure quantitative indicators, such as the payload, grasping force, force sensing, grasping stability and the dimension ranges of objects to be grasped. Additionally, the grasping performance of the proposed gripper is verified experimentally to guarantee the high versatility and robustness of the proposed gripper.
A Resource-Efficient Training Framework for Remote Sensing Text--Image Retrieval
Jan 18, 2025



Remote sensing text--image retrieval (RSTIR) aims to retrieve the matched remote sensing (RS) images from the database according to the descriptive text. Recently, the rapid development of large visual-language pre-training models provides new insights for RSTIR. Nevertheless, as the complexity of models grows in RSTIR, the previous studies suffer from suboptimal resource efficiency during transfer learning. To address this issue, we propose a computation and memory-efficient retrieval (CMER) framework for RSTIR. To reduce the training memory consumption, we propose the Focus-Adapter module, which adopts a side branch structure. Its focus layer suppresses the interference of background pixels for small targets. Simultaneously, to enhance data efficacy, we regard the RS scene category as the metadata and design a concise augmentation technique. The scene label augmentation leverages the prior knowledge from land cover categories and shrinks the search space. We propose the negative sample recycling strategy to make the negative sample pool decoupled from the mini-batch size. It improves the generalization performance without introducing additional encoders. We have conducted quantitative and qualitative experiments on public datasets and expanded the benchmark with some advanced approaches, which demonstrates the competitiveness of the proposed CMER. Compared with the recent advanced methods, the overall retrieval performance of CMER is 2%--5% higher on RSITMD. Moreover, our proposed method reduces memory consumption by 49% and has a 1.4x data throughput during training. The code of the CMER and the dataset will be released at https://github.com/ZhangWeihang99/CMER.
Under-actuated Robotic Gripper with Multiple Grasping Modes Inspired by Human Finger
Mar 19, 2024
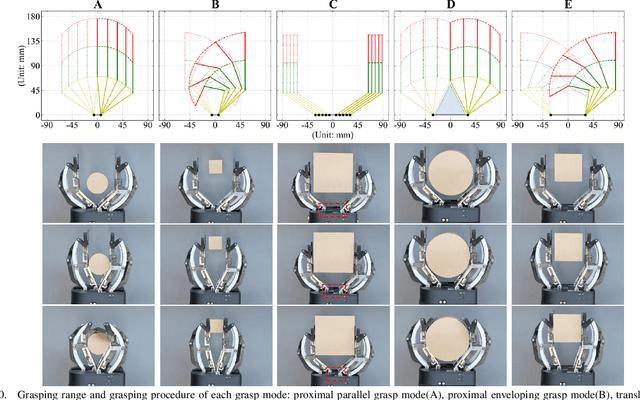


Under-actuated robot grippers as a pervasive tool of robots have become a considerable research focus. Despite their simplicity of mechanical design and control strategy, they suffer from poor versatility and weak adaptability, making widespread applications limited. To better relieve relevant research gaps, we present a novel 3-finger linkage-based gripper that realizes retractable and reconfigurable multi-mode grasps driven by a single motor. Firstly, inspired by the changes that occurred in the contact surface with a human finger moving, we artfully design a slider-slide rail mechanism as the phalanx to achieve retraction of each finger, allowing for better performance in the enveloping grasping mode. Secondly, a reconfigurable structure is constructed to broaden the grasping range of objects' dimensions for the proposed gripper. By adjusting the configuration and gesture of each finger, the gripper can achieve five grasping modes. Thirdly, the proposed gripper is just actuated by a single motor, yet it can be capable of grasping and reconfiguring simultaneously. Finally, various experiments on grasps of slender, thin, and large-volume objects are implemented to evaluate the performance of the proposed gripper in practical scenarios, which demonstrates the excellent grasping capabilities of the gripper.
CapsuleBot: A Novel Compact Hybrid Aerial-Ground Robot with Two Actuated-wheel-rotors
Sep 17, 2023


This paper presents the design, modeling, and experimental validation of CapsuleBot, a compact hybrid aerial-ground vehicle designed for long-term covert reconnaissance. CapsuleBot combines the manoeuvrability of bicopter in the air with the energy efficiency and noise reduction of ground vehicles on the ground. To accomplish this, a structure named actuated-wheel-rotor has been designed, utilizing a sole motor for both the unilateral rotor tilting in the bicopter configuration and the wheel movement in ground mode. CapsuleBot comes equipped with two of these structures, enabling it to attain hybrid aerial-ground propulsion with just four motors. Importantly, the decoupling of motion modes is achieved without the need for additional drivers, enhancing the versatility and robustness of the system. Furthermore, we have designed the full dynamics and control for aerial and ground locomotion based on the bicopter model and the two-wheeled self-balancing vehicle model. The performance of CapsuleBot has been validated through experiments. The results demonstrate that CapsuleBot produces 40.53% less noise in ground mode and consumes 99.35% less energy, highlighting its potential for long-term covert reconnaissance applications.
Empirical Analysis of AI-based Energy Management in Electric Vehicles: A Case Study on Reinforcement Learning
Dec 18, 2022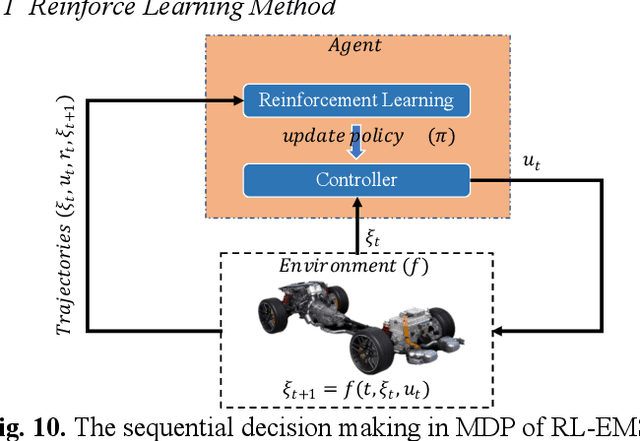
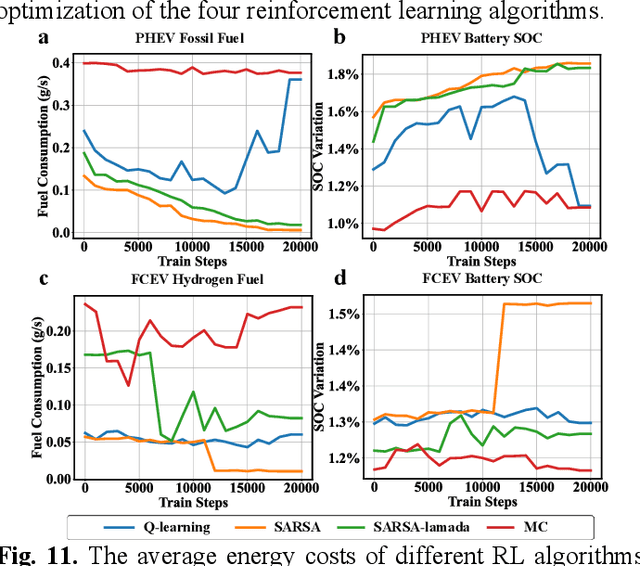
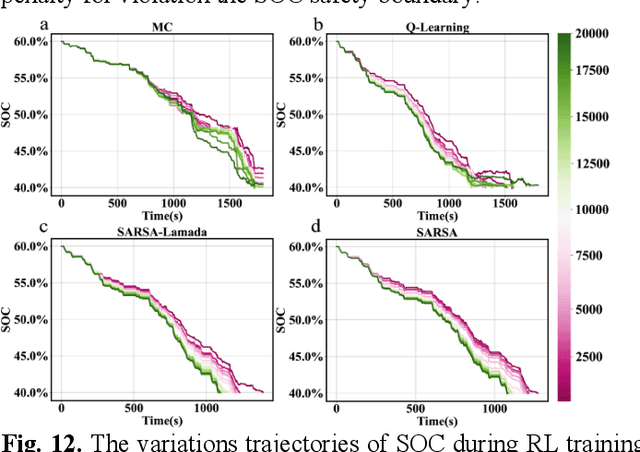
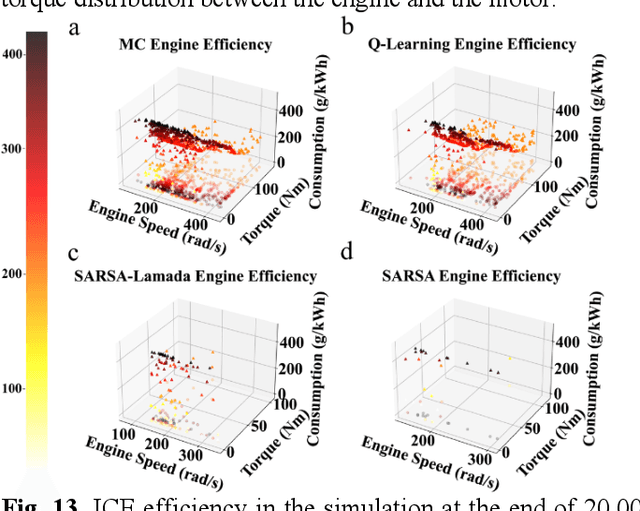
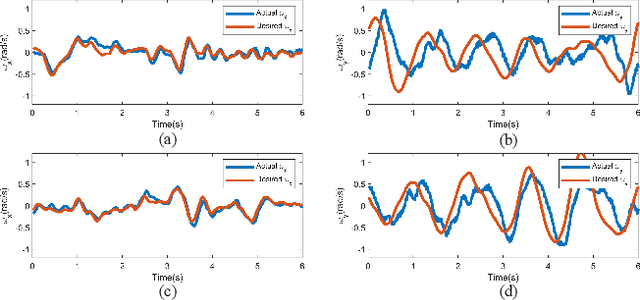
Reinforcement learning-based (RL-based) energy management strategy (EMS) is considered a promising solution for the energy management of electric vehicles with multiple power sources. It has been shown to outperform conventional methods in energy management problems regarding energy-saving and real-time performance. However, previous studies have not systematically examined the essential elements of RL-based EMS. This paper presents an empirical analysis of RL-based EMS in a Plug-in Hybrid Electric Vehicle (PHEV) and Fuel Cell Electric Vehicle (FCEV). The empirical analysis is developed in four aspects: algorithm, perception and decision granularity, hyperparameters, and reward function. The results show that the Off-policy algorithm effectively develops a more fuel-efficient solution within the complete driving cycle compared with other algorithms. Improving the perception and decision granularity does not produce a more desirable energy-saving solution but better balances battery power and fuel consumption. The equivalent energy optimization objective based on the instantaneous state of charge (SOC) variation is parameter sensitive and can help RL-EMSs to achieve more efficient energy-cost strategies.
Potential Auto-driving Threat: Universal Rain-removal Attack
Nov 18, 2022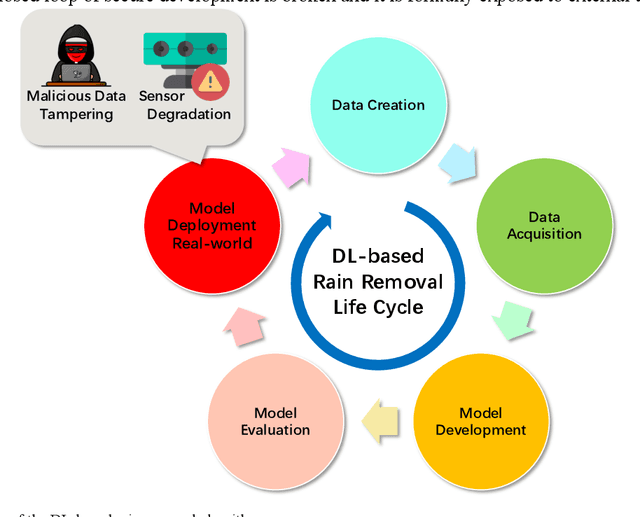
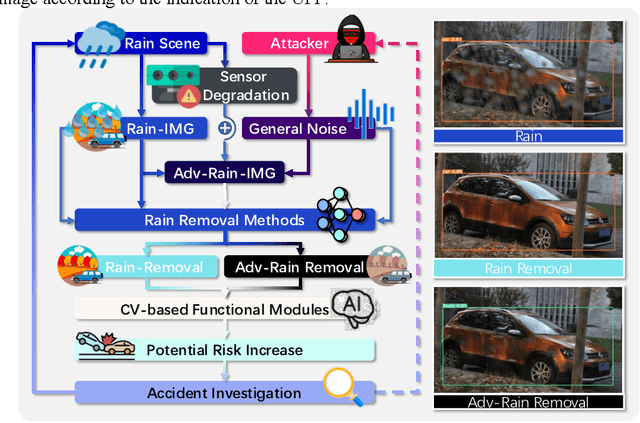
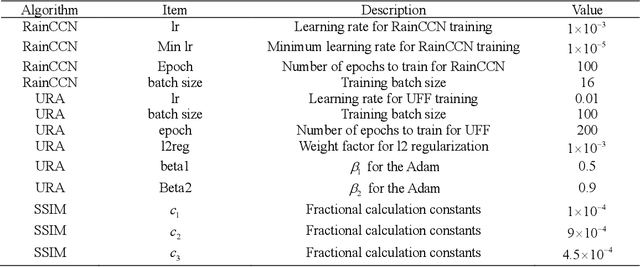
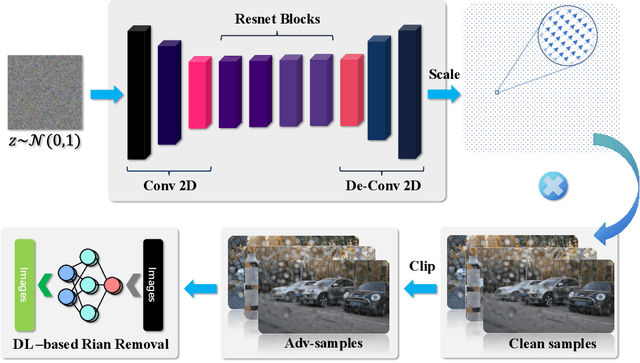
The problem of robustness in adverse weather conditions is considered a significant challenge for computer vision algorithms in the applicants of autonomous driving. Image rain removal algorithms are a general solution to this problem. They find a deep connection between raindrops/rain-streaks and images by mining the hidden features and restoring information about the rain-free environment based on the powerful representation capabilities of neural networks. However, previous research has focused on architecture innovations and has yet to consider the vulnerability issues that already exist in neural networks. This research gap hints at a potential security threat geared toward the intelligent perception of autonomous driving in the rain. In this paper, we propose a universal rain-removal attack (URA) on the vulnerability of image rain-removal algorithms by generating a non-additive spatial perturbation that significantly reduces the similarity and image quality of scene restoration. Notably, this perturbation is difficult to recognise by humans and is also the same for different target images. Thus, URA could be considered a critical tool for the vulnerability detection of image rain-removal algorithms. It also could be developed as a real-world artificial intelligence attack method. Experimental results show that URA can reduce the scene repair capability by 39.5% and the image generation quality by 26.4%, targeting the state-of-the-art (SOTA) single-image rain-removal algorithms currently available.
Double Similarity Distillation for Semantic Image Segmentation
Jul 19, 2021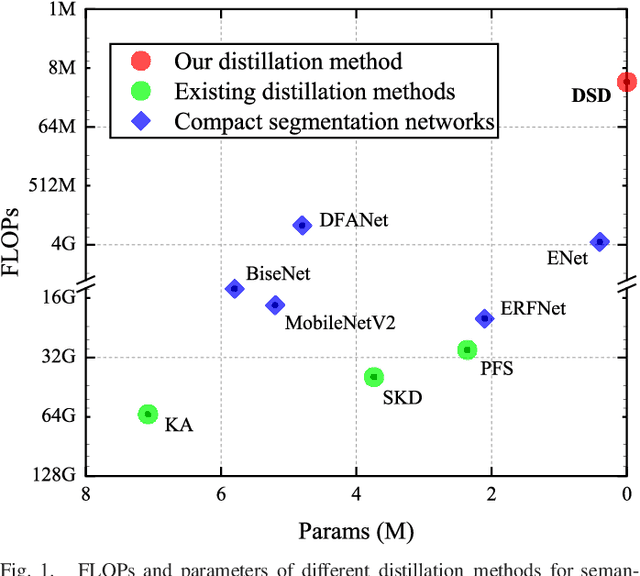

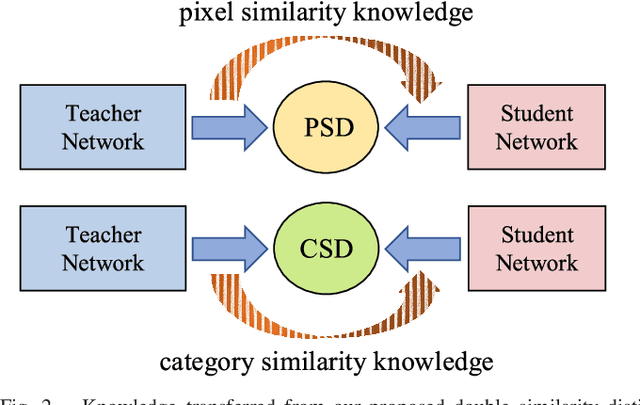
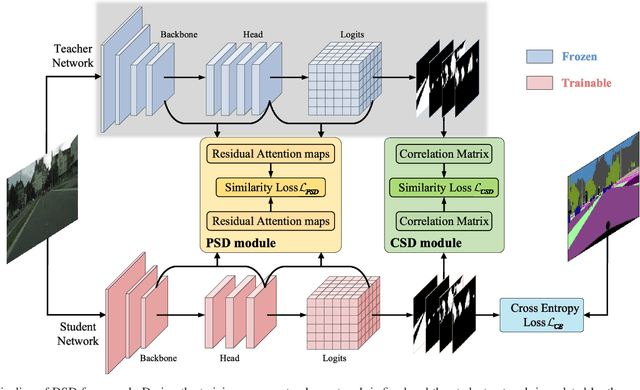
The balance between high accuracy and high speed has always been a challenging task in semantic image segmentation. Compact segmentation networks are more widely used in the case of limited resources, while their performances are constrained. In this paper, motivated by the residual learning and global aggregation, we propose a simple yet general and effective knowledge distillation framework called double similarity distillation (DSD) to improve the classification accuracy of all existing compact networks by capturing the similarity knowledge in pixel and category dimensions, respectively. Specifically, we propose a pixel-wise similarity distillation (PSD) module that utilizes residual attention maps to capture more detailed spatial dependencies across multiple layers. Compared with exiting methods, the PSD module greatly reduces the amount of calculation and is easy to expand. Furthermore, considering the differences in characteristics between semantic segmentation task and other computer vision tasks, we propose a category-wise similarity distillation (CSD) module, which can help the compact segmentation network strengthen the global category correlation by constructing the correlation matrix. Combining these two modules, DSD framework has no extra parameters and only a minimal increase in FLOPs. Extensive experiments on four challenging datasets, including Cityscapes, CamVid, ADE20K, and Pascal VOC 2012, show that DSD outperforms current state-of-the-art methods, proving its effectiveness and generality. The code and models will be publicly available.
FAIR1M: A Benchmark Dataset for Fine-grained Object Recognition in High-Resolution Remote Sensing Imagery
Mar 24, 2021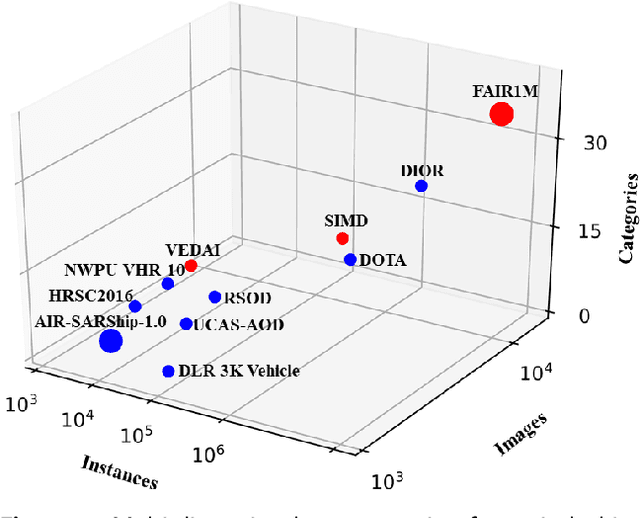
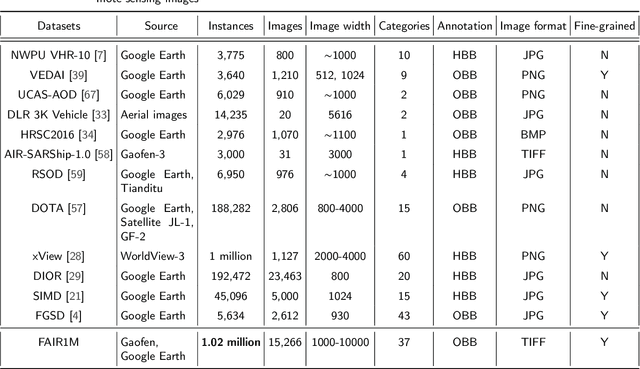
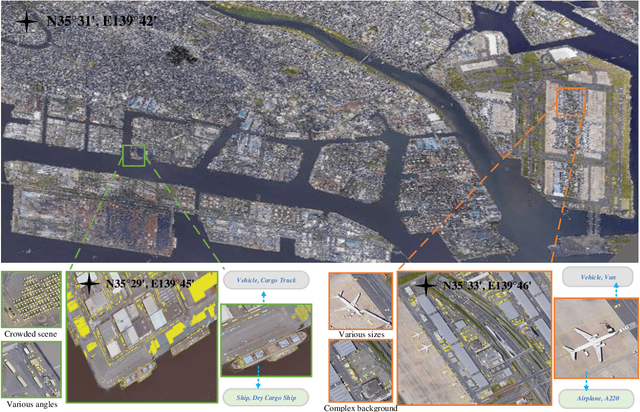
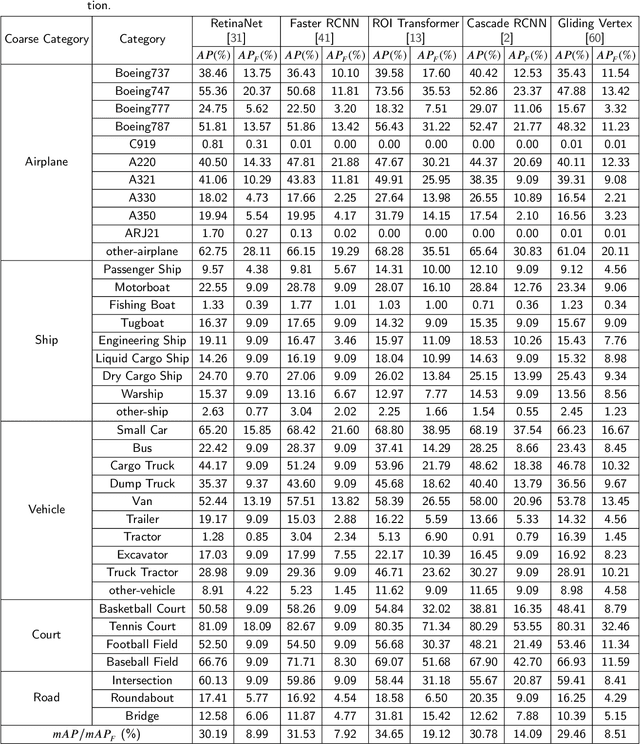
With the rapid development of deep learning, many deep learning-based approaches have made great achievements in object detection task. It is generally known that deep learning is a data-driven method. Data directly impact the performance of object detectors to some extent. Although existing datasets have included common objects in remote sensing images, they still have some limitations in terms of scale, categories, and images. Therefore, there is a strong requirement for establishing a large-scale benchmark on object detection in high-resolution remote sensing images. In this paper, we propose a novel benchmark dataset with more than 1 million instances and more than 15,000 images for Fine-grAined object recognItion in high-Resolution remote sensing imagery which is named as FAIR1M. All objects in the FAIR1M dataset are annotated with respect to 5 categories and 37 sub-categories by oriented bounding boxes. Compared with existing detection datasets dedicated to object detection, the FAIR1M dataset has 4 particular characteristics: (1) it is much larger than other existing object detection datasets both in terms of the quantity of instances and the quantity of images, (2) it provides more rich fine-grained category information for objects in remote sensing images, (3) it contains geographic information such as latitude, longitude and resolution, (4) it provides better image quality owing to a careful data cleaning procedure. To establish a baseline for fine-grained object recognition, we propose a novel evaluation method and benchmark fine-grained object detection tasks and a visual classification task using several State-Of-The-Art (SOTA) deep learning-based models on our FAIR1M dataset. Experimental results strongly indicate that the FAIR1M dataset is closer to practical application and it is considerably more challenging than existing datasets.