 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Governance-Oriented Low-Altitude Intelligence: A Management-Centric Multi-Modal Benchmark With Implicitly Coordinated Vision-Language Reasoning Framework
Jan 27, 2026Low-altitude vision systems are becoming a critical infrastructure for smart city governance. However, existing object-centric perception paradigms and loosely coupled vision-language pipelines are still difficult to support management-oriented anomaly understanding required in real-world urban governance. To bridge this gap, we introduce GovLA-10K, the first management-oriented multi-modal benchmark for low-altitude intelligence, along with GovLA-Reasoner, a unified vision-language reasoning framework tailored for governance-aware aerial perception. Unlike existing studies that aim to exhaustively annotate all visible objects, GovLA-10K is deliberately designed around functionally salient targets that directly correspond to practical management needs, and further provides actionable management suggestions grounded in these observations. To effectively coordinate the fine-grained visual grounding with high-level contextual language reasoning, GovLA-Reasoner introduces an efficient feature adapter that implicitly coordinates discriminative representation sharing between the visual detector and the large language model (LLM). Extensive experiments show that our method significantly improves performance while avoiding the need of fine-tuning for any task-specific individual components. We believe our work offers a new perspective and foundation for future studies on management-aware low-altitude vision-language systems.
RingMo-Agent: A Unified Remote Sensing Foundation Model for Multi-Platform and Multi-Modal Reasoning
Jul 28, 2025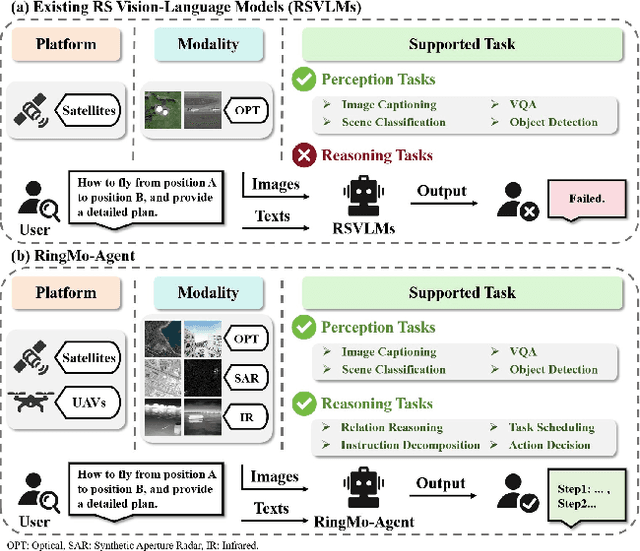
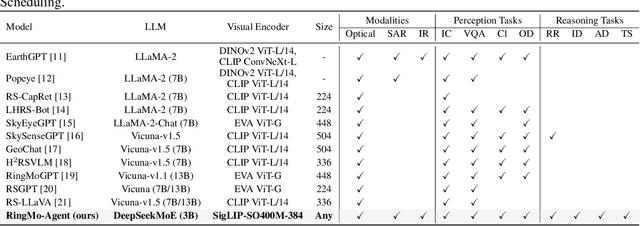

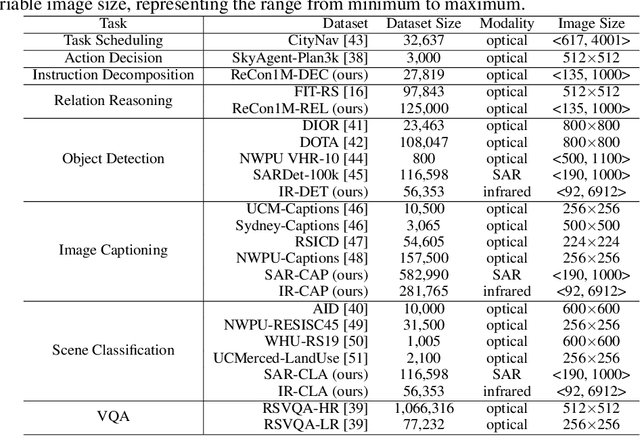
Remote sensing (RS) images from multiple modalities and platforms exhibit diverse details due to differences in sensor characteristics and imaging perspectives. Existing vision-language research in RS largely relies on relatively homogeneous data sources. Moreover, they still remain limited to conventional visual perception tasks such as classification or captioning. As a result, these methods fail to serve as a unified and standalone framework capable of effectively handling RS imagery from diverse sources in real-world applications. To address these issues, we propose RingMo-Agent, a model designed to handle multi-modal and multi-platform data that performs perception and reasoning tasks based on user textual instructions. Compared with existing models, RingMo-Agent 1) is supported by a large-scale vision-language dataset named RS-VL3M, comprising over 3 million image-text pairs, spanning optical, SAR, and infrared (IR) modalities collected from both satellite and UAV platforms, covering perception and challenging reasoning tasks; 2) learns modality adaptive representations by incorporating separated embedding layers to construct isolated features for heterogeneous modalities and reduce cross-modal interference; 3) unifies task modeling by introducing task-specific tokens and employing a token-based high-dimensional hidden state decoding mechanism designed for long-horizon spatial tasks. Extensive experiments on various RS vision-language tasks demonstrate that RingMo-Agent not only proves effective in both visual understanding and sophisticated analytical tasks, but also exhibits strong generalizability across different platforms and sensing modalities.
A Complex-valued SAR Foundation Model Based on Physically Inspired Representation Learning
Apr 16, 2025Vision foundation models in remote sensing have been extensively studied due to their superior generalization on various downstream tasks. Synthetic Aperture Radar (SAR) offers all-day, all-weather imaging capabilities, providing significant advantages for Earth observation. However, establishing a foundation model for SAR image interpretation inevitably encounters the challenges of insufficient information utilization and poor interpretability. In this paper, we propose a remote sensing foundation model based on complex-valued SAR data, which simulates the polarimetric decomposition process for pre-training, i.e., characterizing pixel scattering intensity as a weighted combination of scattering bases and scattering coefficients, thereby endowing the foundation model with physical interpretability. Specifically, we construct a series of scattering queries, each representing an independent and meaningful scattering basis, which interact with SAR features in the scattering query decoder and output the corresponding scattering coefficient. To guide the pre-training process, polarimetric decomposition loss and power self-supervision loss are constructed. The former aligns the predicted coefficients with Yamaguchi coefficients, while the latter reconstructs power from the predicted coefficients and compares it to the input image's power. The performance of our foundation model is validated on six typical downstream tasks, achieving state-of-the-art results. Notably, the foundation model can extract stable feature representations and exhibits strong generalization, even in data-scarce conditions.
RingMoE: Mixture-of-Modality-Experts Multi-Modal Foundation Models for Universal Remote Sensing Image Interpretation
Apr 04, 2025The rapid advancement of foundation models has revolutionized visual representation learning in a self-supervised manner. However, their application in remote sensing (RS) remains constrained by a fundamental gap: existing models predominantly handle single or limited modalities, overlooking the inherently multi-modal nature of RS observations. Optical, synthetic aperture radar (SAR), and multi-spectral data offer complementary insights that significantly reduce the inherent ambiguity and uncertainty in single-source analysis. To bridge this gap, we introduce RingMoE, a unified multi-modal RS foundation model with 14.7 billion parameters, pre-trained on 400 million multi-modal RS images from nine satellites. RingMoE incorporates three key innovations: (1) A hierarchical Mixture-of-Experts (MoE) architecture comprising modal-specialized, collaborative, and shared experts, effectively modeling intra-modal knowledge while capturing cross-modal dependencies to mitigate conflicts between modal representations; (2) Physics-informed self-supervised learning, explicitly embedding sensor-specific radiometric characteristics into the pre-training objectives; (3) Dynamic expert pruning, enabling adaptive model compression from 14.7B to 1B parameters while maintaining performance, facilitating efficient deployment in Earth observation applications. Evaluated across 23 benchmarks spanning six key RS tasks (i.e., classification, detection, segmentation, tracking, change detection, and depth estimation), RingMoE outperforms existing foundation models and sets new SOTAs, demonstrating remarkable adaptability from single-modal to multi-modal scenarios. Beyond theoretical progress, it has been deployed and trialed in multiple sectors, including emergency response, land management, marine sciences, and urban planning.
RS-vHeat: Heat Conduction Guided Efficient Remote Sensing Foundation Model
Nov 27, 2024Remote sensing foundation models largely break away from the traditional paradigm of designing task-specific models, offering greater scalability across multiple tasks. However, they face challenges such as low computational efficiency and limited interpretability, especially when dealing with high-resolution remote sensing images. To overcome these, we draw inspiration from heat conduction, a physical process modeling local heat diffusion. Building on this idea, we are the first to explore the potential of using the parallel computing model of heat conduction to simulate the local region correlations in high-resolution remote sensing images, and introduce RS-vHeat, an efficient multi-modal remote sensing foundation model. Specifically, RS-vHeat 1) applies the Heat Conduction Operator (HCO) with a complexity of $O(N^{1.5})$ and a global receptive field, reducing computational overhead while capturing remote sensing object structure information to guide heat diffusion; 2) learns the frequency distribution representations of various scenes through a self-supervised strategy based on frequency domain hierarchical masking and multi-domain reconstruction; 3) significantly improves efficiency and performance over state-of-the-art techniques across 4 tasks and 10 datasets. Compared to attention-based remote sensing foundation models, we reduces memory consumption by 84%, decreases FLOPs by 24% and improves throughput by 2.7 times.
Prompt-and-Transfer: Dynamic Class-aware Enhancement for Few-shot Segmentation
Sep 16, 2024For more efficient generalization to unseen domains (classes), most Few-shot Segmentation (FSS) would directly exploit pre-trained encoders and only fine-tune the decoder, especially in the current era of large models. However, such fixed feature encoders tend to be class-agnostic, inevitably activating objects that are irrelevant to the target class. In contrast, humans can effortlessly focus on specific objects in the line of sight. This paper mimics the visual perception pattern of human beings and proposes a novel and powerful prompt-driven scheme, called ``Prompt and Transfer" (PAT), which constructs a dynamic class-aware prompting paradigm to tune the encoder for focusing on the interested object (target class) in the current task. Three key points are elaborated to enhance the prompting: 1) Cross-modal linguistic information is introduced to initialize prompts for each task. 2) Semantic Prompt Transfer (SPT) that precisely transfers the class-specific semantics within the images to prompts. 3) Part Mask Generator (PMG) that works in conjunction with SPT to adaptively generate different but complementary part prompts for different individuals. Surprisingly, PAT achieves competitive performance on 4 different tasks including standard FSS, Cross-domain FSS (e.g., CV, medical, and remote sensing domains), Weak-label FSS, and Zero-shot Segmentation, setting new state-of-the-arts on 11 benchmarks.
Breaking Immutable: Information-Coupled Prototype Elaboration for Few-Shot Object Detection
Nov 27, 2022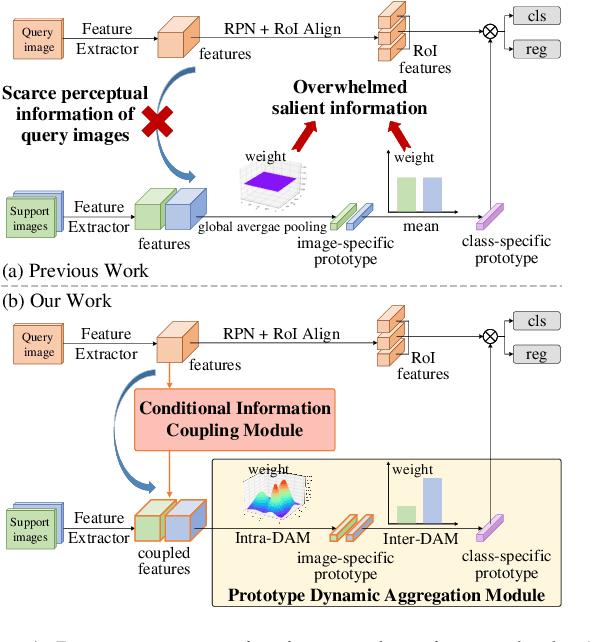
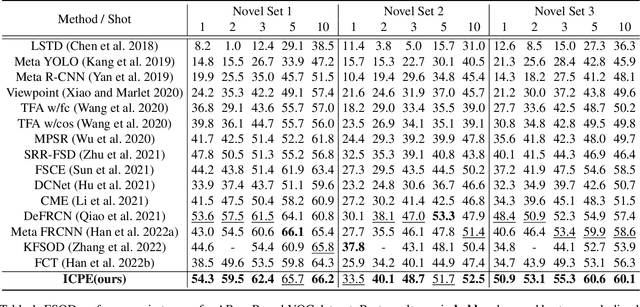
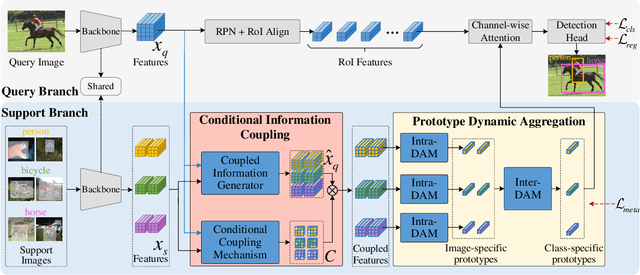
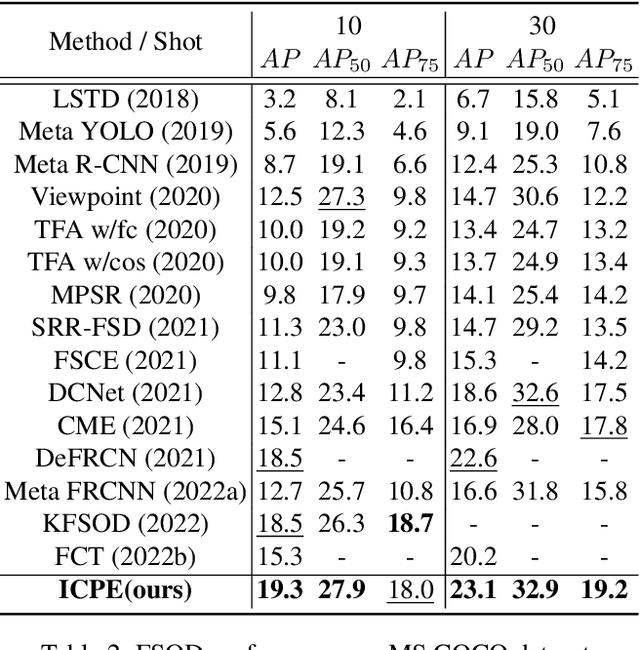
Few-shot object detection, expecting detectors to detect novel classes with a few instances, has made conspicuous progress. However, the prototypes extracted by existing meta-learning based methods still suffer from insufficient representative information and lack awareness of query images, which cannot be adaptively tailored to different query images. Firstly, only the support images are involved for extracting prototypes, resulting in scarce perceptual information of query images. Secondly, all pixels of all support images are treated equally when aggregating features into prototype vectors, thus the salient objects are overwhelmed by the cluttered background. In this paper, we propose an Information-Coupled Prototype Elaboration (ICPE) method to generate specific and representative prototypes for each query image. Concretely, a conditional information coupling module is introduced to couple information from the query branch to the support branch, strengthening the query-perceptual information in support features. Besides, we design a prototype dynamic aggregation module that dynamically adjusts intra-image and inter-image aggregation weights to highlight the salient information useful for detecting query images. Experimental results on both Pascal VOC and MS COCO demonstrate that our method achieves state-of-the-art performance in almost all settings.
FAIR1M: A Benchmark Dataset for Fine-grained Object Recognition in High-Resolution Remote Sensing Imagery
Mar 24, 2021
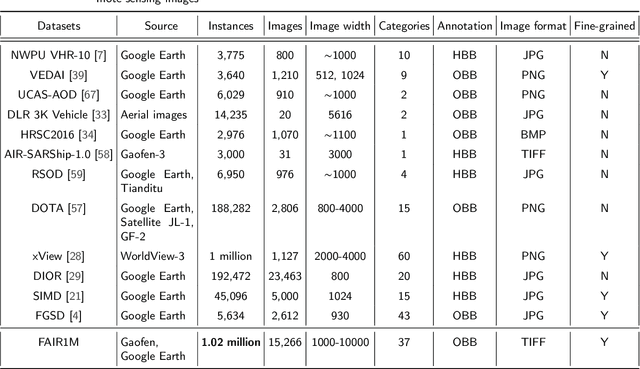
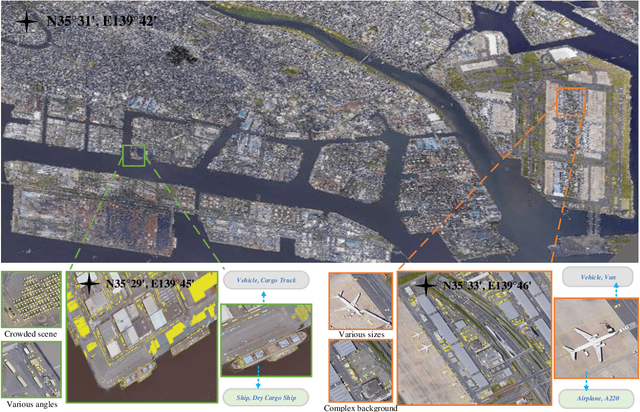
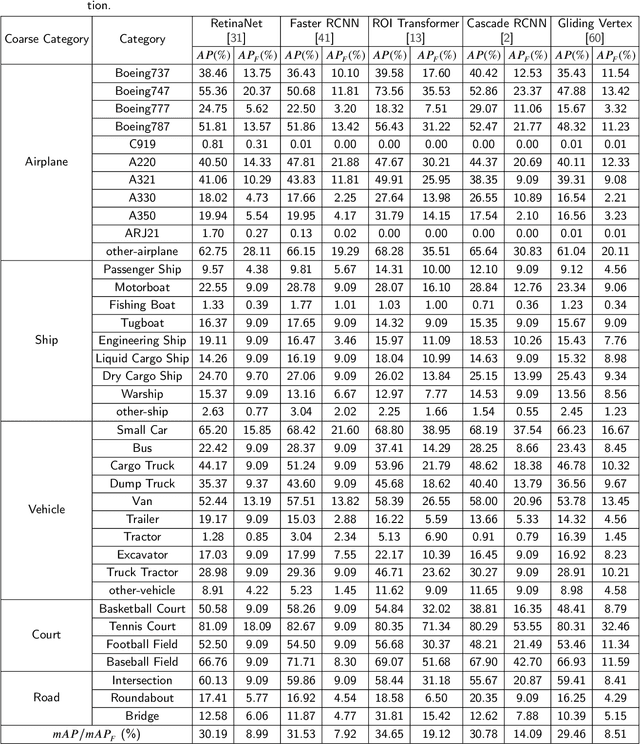
With the rapid development of deep learning, many deep learning-based approaches have made great achievements in object detection task. It is generally known that deep learning is a data-driven method. Data directly impact the performance of object detectors to some extent. Although existing datasets have included common objects in remote sensing images, they still have some limitations in terms of scale, categories, and images. Therefore, there is a strong requirement for establishing a large-scale benchmark on object detection in high-resolution remote sensing images. In this paper, we propose a novel benchmark dataset with more than 1 million instances and more than 15,000 images for Fine-grAined object recognItion in high-Resolution remote sensing imagery which is named as FAIR1M. All objects in the FAIR1M dataset are annotated with respect to 5 categories and 37 sub-categories by oriented bounding boxes. Compared with existing detection datasets dedicated to object detection, the FAIR1M dataset has 4 particular characteristics: (1) it is much larger than other existing object detection datasets both in terms of the quantity of instances and the quantity of images, (2) it provides more rich fine-grained category information for objects in remote sensing images, (3) it contains geographic information such as latitude, longitude and resolution, (4) it provides better image quality owing to a careful data cleaning procedure. To establish a baseline for fine-grained object recognition, we propose a novel evaluation method and benchmark fine-grained object detection tasks and a visual classification task using several State-Of-The-Art (SOTA) deep learning-based models on our FAIR1M dataset. Experimental results strongly indicate that the FAIR1M dataset is closer to practical application and it is considerably more challenging than existing datasets.
Object Relational Graph with Teacher-Recommended Learning for Video Captioning
Feb 26, 2020



Taking full advantage of the information from both vision and language is critical for the video captioning task. Existing models lack adequate visual representation due to the neglect of interaction between object, and sufficient training for content-related words due to long-tailed problems. In this paper, we propose a complete video captioning system including both a novel model and an effective training strategy. Specifically, we propose an object relational graph (ORG) based encoder, which captures more detailed interaction features to enrich visual representation. Meanwhile, we design a teacher-recommended learning (TRL) method to make full use of the successful external language model (ELM) to integrate the abundant linguistic knowledge into the caption model. The ELM generates more semantically similar word proposals which extend the ground-truth words used for training to deal with the long-tailed problem. Experimental evaluations on three benchmarks: MSVD, MSR-VTT and VATEX show the proposed ORG-TRL system achieves state-of-the-art performance. Extensive ablation studies and visualizations illustrate the effectiveness of our system.