 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing RLVR training instability through the lens of objective-level hacking
Feb 01, 2026Prolonged reinforcement learning with verifiable rewards (RLVR) has been shown to drive continuous improvements in the reasoning capabilities of large language models, but the training is often prone to instabilities, especially in Mixture-of-Experts (MoE) architectures. Training instability severely undermines model capability improvement, yet its underlying causes and mechanisms remain poorly understood. In this work, we introduce a principled framework for understanding RLVR instability through the lens of objective-level hacking. Unlike reward hacking, which arises from exploitable verifiers, objective-level hacking emerges from token-level credit misalignment and is manifested as system-level spurious signals in the optimization objective. Grounded in our framework, together with extensive experiments on a 30B MoE model, we trace the origin and formalize the mechanism behind a key pathological training dynamic in MoE models: the abnormal growth of the training-inference discrepancy, a phenomenon widely associated with instability but previously lacking a mechanistic explanation. These findings provide a concrete and causal account of the training dynamics underlying instabilities in MoE models, offering guidance for the design of stable RLVR algorithms.
RingMo-Agent: A Unified Remote Sensing Foundation Model for Multi-Platform and Multi-Modal Reasoning
Jul 28, 2025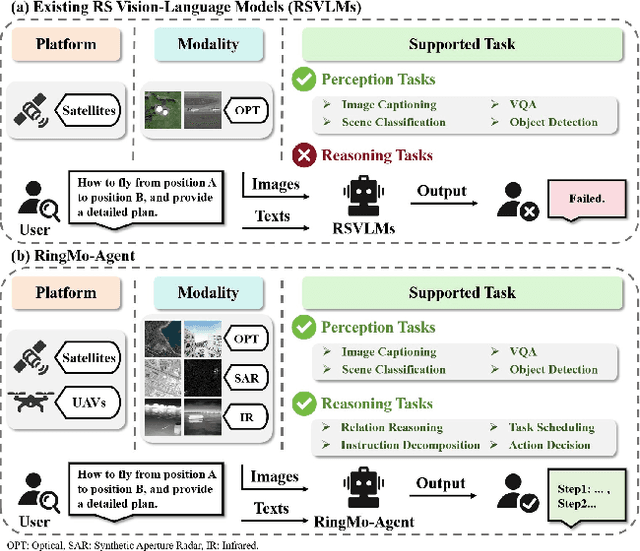
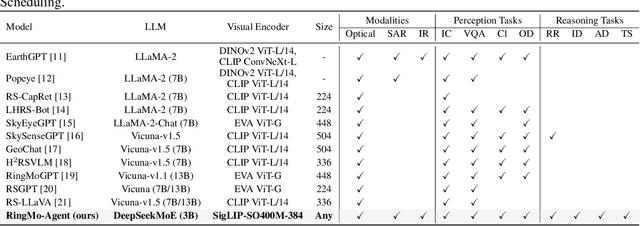

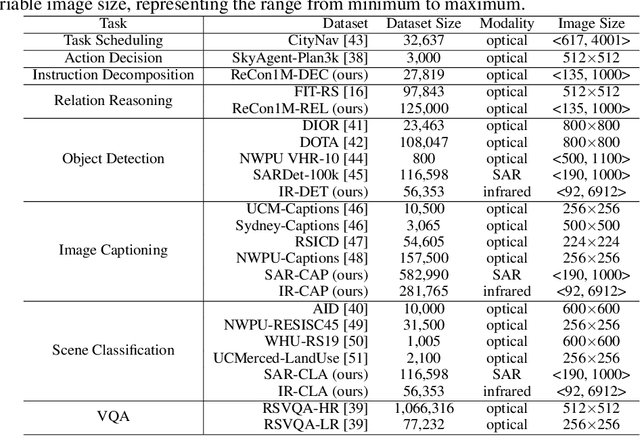
Remote sensing (RS) images from multiple modalities and platforms exhibit diverse details due to differences in sensor characteristics and imaging perspectives. Existing vision-language research in RS largely relies on relatively homogeneous data sources. Moreover, they still remain limited to conventional visual perception tasks such as classification or captioning. As a result, these methods fail to serve as a unified and standalone framework capable of effectively handling RS imagery from diverse sources in real-world applications. To address these issues, we propose RingMo-Agent, a model designed to handle multi-modal and multi-platform data that performs perception and reasoning tasks based on user textual instructions. Compared with existing models, RingMo-Agent 1) is supported by a large-scale vision-language dataset named RS-VL3M, comprising over 3 million image-text pairs, spanning optical, SAR, and infrared (IR) modalities collected from both satellite and UAV platforms, covering perception and challenging reasoning tasks; 2) learns modality adaptive representations by incorporating separated embedding layers to construct isolated features for heterogeneous modalities and reduce cross-modal interference; 3) unifies task modeling by introducing task-specific tokens and employing a token-based high-dimensional hidden state decoding mechanism designed for long-horizon spatial tasks. Extensive experiments on various RS vision-language tasks demonstrate that RingMo-Agent not only proves effective in both visual understanding and sophisticated analytical tasks, but also exhibits strong generalizability across different platforms and sensing modalities.
RingMoE: Mixture-of-Modality-Experts Multi-Modal Foundation Models for Universal Remote Sensing Image Interpretation
Apr 04, 2025The rapid advancement of foundation models has revolutionized visual representation learning in a self-supervised manner. However, their application in remote sensing (RS) remains constrained by a fundamental gap: existing models predominantly handle single or limited modalities, overlooking the inherently multi-modal nature of RS observations. Optical, synthetic aperture radar (SAR), and multi-spectral data offer complementary insights that significantly reduce the inherent ambiguity and uncertainty in single-source analysis. To bridge this gap, we introduce RingMoE, a unified multi-modal RS foundation model with 14.7 billion parameters, pre-trained on 400 million multi-modal RS images from nine satellites. RingMoE incorporates three key innovations: (1) A hierarchical Mixture-of-Experts (MoE) architecture comprising modal-specialized, collaborative, and shared experts, effectively modeling intra-modal knowledge while capturing cross-modal dependencies to mitigate conflicts between modal representations; (2) Physics-informed self-supervised learning, explicitly embedding sensor-specific radiometric characteristics into the pre-training objectives; (3) Dynamic expert pruning, enabling adaptive model compression from 14.7B to 1B parameters while maintaining performance, facilitating efficient deployment in Earth observation applications. Evaluated across 23 benchmarks spanning six key RS tasks (i.e., classification, detection, segmentation, tracking, change detection, and depth estimation), RingMoE outperforms existing foundation models and sets new SOTAs, demonstrating remarkable adaptability from single-modal to multi-modal scenarios. Beyond theoretical progress, it has been deployed and trialed in multiple sectors, including emergency response, land management, marine sciences, and urban planning.
A Generalist Cross-Domain Molecular Learning Framework for Structure-Based Drug Discovery
Mar 06, 2025Structure-based drug discovery (SBDD) is a systematic scientific process that develops new drugs by leveraging the detailed physical structure of the target protein. Recent advancements in pre-trained models for biomolecules have demonstrated remarkable success across various biochemical applications, including drug discovery and protein engineering. However, in most approaches, the pre-trained models primarily focus on the characteristics of either small molecules or proteins, without delving into their binding interactions which are essential cross-domain relationships pivotal to SBDD. To fill this gap, we propose a general-purpose foundation model named BIT (an abbreviation for Biomolecular Interaction Transformer), which is capable of encoding a range of biochemical entities, including small molecules, proteins, and protein-ligand complexes, as well as various data formats, encompassing both 2D and 3D structures. Specifically, we introduce Mixture-of-Domain-Experts (MoDE) to handle the biomolecules from diverse biochemical domains and Mixture-of-Structure-Experts (MoSE) to capture positional dependencies in the molecular structures. The proposed mixture-of-experts approach enables BIT to achieve both deep fusion and domain-specific encoding, effectively capturing fine-grained molecular interactions within protein-ligand complexes. Then, we perform cross-domain pre-training on the shared Transformer backbone via several unified self-supervised denoising tasks. Experimental results on various benchmarks demonstrate that BIT achieves exceptional performance in downstream tasks, including binding affinity prediction, structure-based virtual screening, and molecular property prediction.
GENERator: A Long-Context Generative Genomic Foundation Model
Feb 11, 2025Advancements in DNA sequencing technologies have significantly improved our ability to decode genomic sequences. However, the prediction and interpretation of these sequences remain challenging due to the intricate nature of genetic material. Large language models (LLMs) have introduced new opportunities for biological sequence analysis. Recent developments in genomic language models have underscored the potential of LLMs in deciphering DNA sequences. Nonetheless, existing models often face limitations in robustness and application scope, primarily due to constraints in model structure and training data scale. To address these limitations, we present GENERator, a generative genomic foundation model featuring a context length of 98k base pairs (bp) and 1.2B parameters. Trained on an expansive dataset comprising 386B bp of eukaryotic DNA, the GENERator demonstrates state-of-the-art performance across both established and newly proposed benchmarks. The model adheres to the central dogma of molecular biology, accurately generating protein-coding sequences that translate into proteins structurally analogous to known families. It also shows significant promise in sequence optimization, particularly through the prompt-responsive generation of promoter sequences with specific activity profiles. These capabilities position the GENERator as a pivotal tool for genomic research and biotechnological advancement, enhancing our ability to interpret and predict complex biological systems and enabling precise genomic interventions.
ProtCLIP: Function-Informed Protein Multi-Modal Learning
Dec 28, 2024Multi-modality pre-training paradigm that aligns protein sequences and biological descriptions has learned general protein representations and achieved promising performance in various downstream applications. However, these works were still unable to replicate the extraordinary success of language-supervised visual foundation models due to the ineffective usage of aligned protein-text paired data and the lack of an effective function-informed pre-training paradigm. To address these issues, this paper curates a large-scale protein-text paired dataset called ProtAnno with a property-driven sampling strategy, and introduces a novel function-informed protein pre-training paradigm. Specifically, the sampling strategy determines selecting probability based on the sample confidence and property coverage, balancing the data quality and data quantity in face of large-scale noisy data. Furthermore, motivated by significance of the protein specific functional mechanism, the proposed paradigm explicitly model protein static and dynamic functional segments by two segment-wise pre-training objectives, injecting fine-grained information in a function-informed manner. Leveraging all these innovations, we develop ProtCLIP, a multi-modality foundation model that comprehensively represents function-aware protein embeddings. On 22 different protein benchmarks within 5 types, including protein functionality classification, mutation effect prediction, cross-modal transformation, semantic similarity inference and protein-protein interaction prediction, our ProtCLIP consistently achieves SOTA performance, with remarkable improvements of 75% on average in five cross-modal transformation benchmarks, 59.9% in GO-CC and 39.7% in GO-BP protein function prediction. The experimental results verify the extraordinary potential of ProtCLIP serving as the protein multi-modality foundation model.
RS-vHeat: Heat Conduction Guided Efficient Remote Sensing Foundation Model
Nov 27, 2024Remote sensing foundation models largely break away from the traditional paradigm of designing task-specific models, offering greater scalability across multiple tasks. However, they face challenges such as low computational efficiency and limited interpretability, especially when dealing with high-resolution remote sensing images. To overcome these, we draw inspiration from heat conduction, a physical process modeling local heat diffusion. Building on this idea, we are the first to explore the potential of using the parallel computing model of heat conduction to simulate the local region correlations in high-resolution remote sensing images, and introduce RS-vHeat, an efficient multi-modal remote sensing foundation model. Specifically, RS-vHeat 1) applies the Heat Conduction Operator (HCO) with a complexity of $O(N^{1.5})$ and a global receptive field, reducing computational overhead while capturing remote sensing object structure information to guide heat diffusion; 2) learns the frequency distribution representations of various scenes through a self-supervised strategy based on frequency domain hierarchical masking and multi-domain reconstruction; 3) significantly improves efficiency and performance over state-of-the-art techniques across 4 tasks and 10 datasets. Compared to attention-based remote sensing foundation models, we reduces memory consumption by 84%, decreases FLOPs by 24% and improves throughput by 2.7 times.
NavAgent: Multi-scale Urban Street View Fusion For UAV Embodied Vision-and-Language Navigation
Nov 13, 2024Vision-and-Language Navigation (VLN), as a widely discussed research direction in embodied intelligence, aims to enable embodied agents to navigate in complicated visual environments through natural language commands. Most existing VLN methods focus on indoor ground robot scenarios. However, when applied to UAV VLN in outdoor urban scenes, it faces two significant challenges. First, urban scenes contain numerous objects, which makes it challenging to match fine-grained landmarks in images with complex textual descriptions of these landmarks. Second, overall environmental information encompasses multiple modal dimensions, and the diversity of representations significantly increases the complexity of the encoding process. To address these challenges, we propose NavAgent, the first urban UAV embodied navigation model driven by a large Vision-Language Model. NavAgent undertakes navigation tasks by synthesizing multi-scale environmental information, including topological maps (global), panoramas (medium), and fine-grained landmarks (local). Specifically, we utilize GLIP to build a visual recognizer for landmark capable of identifying and linguisticizing fine-grained landmarks. Subsequently, we develop dynamically growing scene topology map that integrate environmental information and employ Graph Convolutional Networks to encode global environmental data. In addition, to train the visual recognizer for landmark, we develop NavAgent-Landmark2K, the first fine-grained landmark dataset for real urban street scenes. In experiments conducted on the Touchdown and Map2seq datasets, NavAgent outperforms strong baseline models. The code and dataset will be released to the community to facilitate the exploration and development of outdoor VLN.
TokenSelect: Efficient Long-Context Inference and Length Extrapolation for LLMs via Dynamic Token-Level KV Cache Selection
Nov 05, 2024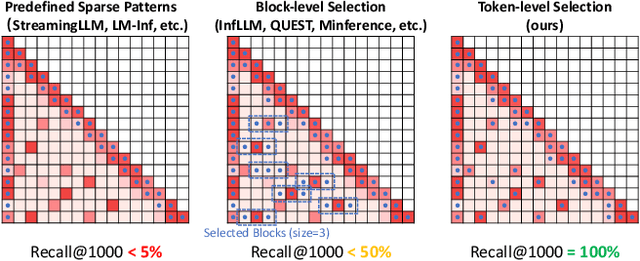
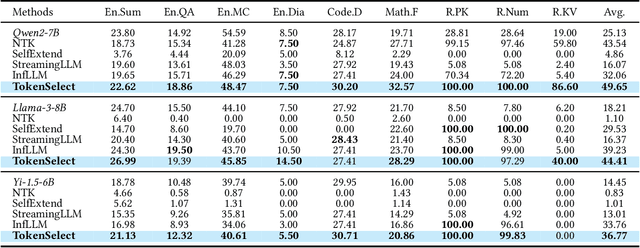
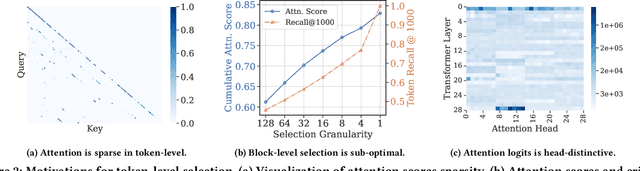
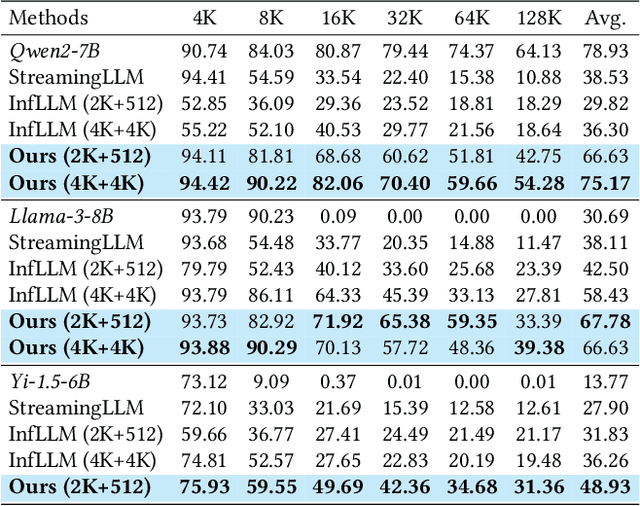
With the development of large language models (LLMs), the ability to handle longer contexts has become a key capability for Web applications such as cross-document understanding and LLM-powered search systems. However, this progress faces two major challenges: performance degradation due to sequence lengths out-of-distribution, and excessively long inference times caused by the quadratic computational complexity of attention. These issues hinder the application of LLMs in long-context scenarios. In this paper, we propose Dynamic Token-Level KV Cache Selection (TokenSelect), a model-agnostic, training-free method for efficient and accurate long-context inference. TokenSelect builds upon the observation of non-contiguous attention sparsity, using Query-Key dot products to measure per-head KV Cache criticality at token-level. By per-head soft voting mechanism, TokenSelect selectively involves a small number of critical KV cache tokens in the attention calculation without sacrificing accuracy. To further accelerate TokenSelect, we designed the Selection Cache based on observations of consecutive Query similarity and implemented efficient dot product kernel, significantly reducing the overhead of token selection. A comprehensive evaluation of TokenSelect demonstrates up to 23.84x speedup in attention computation and up to 2.28x acceleration in end-to-end latency, while providing superior performance compared to state-of-the-art long-context inference methods.
Structure-Enhanced Protein Instruction Tuning: Towards General-Purpose Protein Understanding
Oct 04, 2024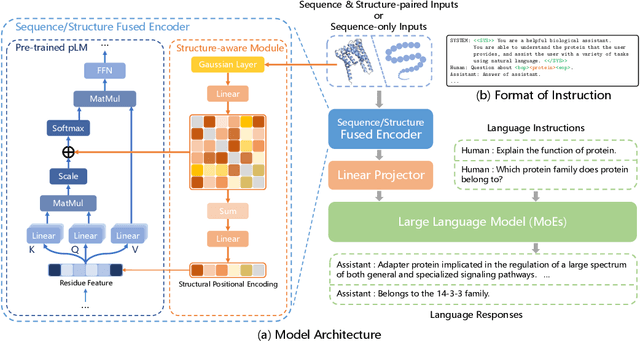



Proteins, as essential biomolecules, play a central role in biological processes, including metabolic reactions and DNA replication. Accurate prediction of their properties and functions is crucial in biological applications. Recent development of protein language models (pLMs) with supervised fine tuning provides a promising solution to this problem. However, the fine-tuned model is tailored for particular downstream prediction task, and achieving general-purpose protein understanding remains a challenge. In this paper, we introduce Structure-Enhanced Protein Instruction Tuning (SEPIT) framework to bridge this gap. Our approach integrates a noval structure-aware module into pLMs to inform them with structural knowledge, and then connects these enhanced pLMs to large language models (LLMs) to generate understanding of proteins. In this framework, we propose a novel two-stage instruction tuning pipeline that first establishes a basic understanding of proteins through caption-based instructions and then refines this understanding using a mixture of experts (MoEs) to learn more complex properties and functional information with the same amount of activated parameters. Moreover, we construct the largest and most comprehensive protein instruction dataset to date, which allows us to train and evaluate the general-purpose protein understanding model. Extensive experimental results on open-ended generation and closed-set answer tasks demonstrate the superior performance of SEPIT over both closed-source general LLMs and open-source LLMs trained with protein knowledge.