 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
NavAgent: Multi-scale Urban Street View Fusion For UAV Embodied Vision-and-Language Navigation
Nov 13, 2024Vision-and-Language Navigation (VLN), as a widely discussed research direction in embodied intelligence, aims to enable embodied agents to navigate in complicated visual environments through natural language commands. Most existing VLN methods focus on indoor ground robot scenarios. However, when applied to UAV VLN in outdoor urban scenes, it faces two significant challenges. First, urban scenes contain numerous objects, which makes it challenging to match fine-grained landmarks in images with complex textual descriptions of these landmarks. Second, overall environmental information encompasses multiple modal dimensions, and the diversity of representations significantly increases the complexity of the encoding process. To address these challenges, we propose NavAgent, the first urban UAV embodied navigation model driven by a large Vision-Language Model. NavAgent undertakes navigation tasks by synthesizing multi-scale environmental information, including topological maps (global), panoramas (medium), and fine-grained landmarks (local). Specifically, we utilize GLIP to build a visual recognizer for landmark capable of identifying and linguisticizing fine-grained landmarks. Subsequently, we develop dynamically growing scene topology map that integrate environmental information and employ Graph Convolutional Networks to encode global environmental data. In addition, to train the visual recognizer for landmark, we develop NavAgent-Landmark2K, the first fine-grained landmark dataset for real urban street scenes. In experiments conducted on the Touchdown and Map2seq datasets, NavAgent outperforms strong baseline models. The code and dataset will be released to the community to facilitate the exploration and development of outdoor VLN.
AeroVerse: UAV-Agent Benchmark Suite for Simulating, Pre-training, Finetuning, and Evaluating Aerospace Embodied World Models
Aug 28, 2024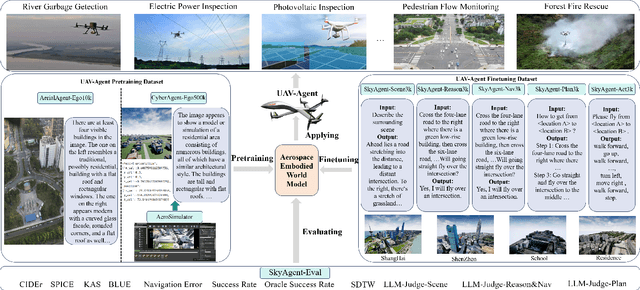
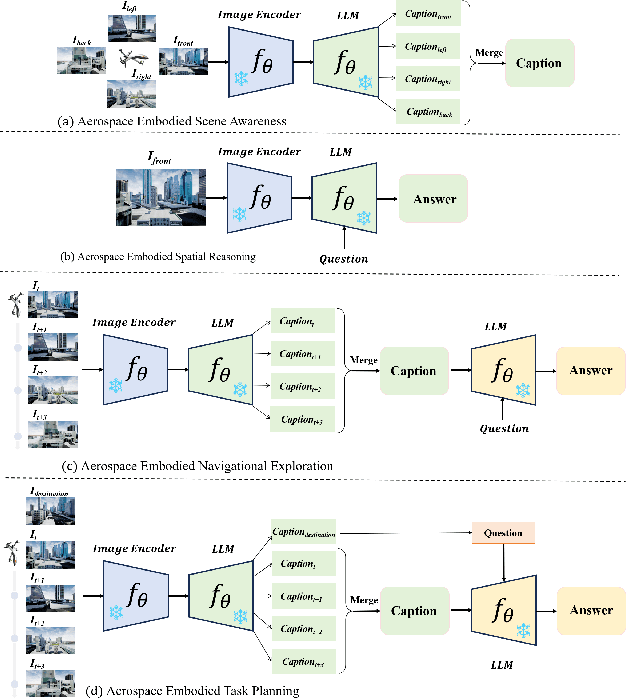


Aerospace embodied intelligence aims to empower unmanned aerial vehicles (UAVs) and other aerospace platforms to achieve autonomous perception, cognition, and action, as well as egocentric active interaction with humans and the environment. The aerospace embodied world model serves as an effective means to realize the autonomous intelligence of UAVs and represents a necessary pathway toward aerospace embodied intelligence. However, existing embodied world models primarily focus on ground-level intelligent agents in indoor scenarios, while research on UAV intelligent agents remains unexplored. To address this gap, we construct the first large-scale real-world image-text pre-training dataset, AerialAgent-Ego10k, featuring urban drones from a first-person perspective. We also create a virtual image-text-pose alignment dataset, CyberAgent Ego500k, to facilitate the pre-training of the aerospace embodied world model. For the first time, we clearly define 5 downstream tasks, i.e., aerospace embodied scene awareness, spatial reasoning, navigational exploration, task planning, and motion decision, and construct corresponding instruction datasets, i.e., SkyAgent-Scene3k, SkyAgent-Reason3k, SkyAgent-Nav3k and SkyAgent-Plan3k, and SkyAgent-Act3k, for fine-tuning the aerospace embodiment world model. Simultaneously, we develop SkyAgentEval, the downstream task evaluation metrics based on GPT-4, to comprehensively, flexibly, and objectively assess the results, revealing the potential and limitations of 2D/3D visual language models in UAV-agent tasks. Furthermore, we integrate over 10 2D/3D visual-language models, 2 pre-training datasets, 5 finetuning datasets, more than 10 evaluation metrics, and a simulator into the benchmark suite, i.e., AeroVerse, which will be released to the community to promote exploration and development of aerospace embodied intelligence.