 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUI2Code^N: A Visual Language Model for Test-Time Scalable Interactive UI-to-Code Generation
Nov 14, 2025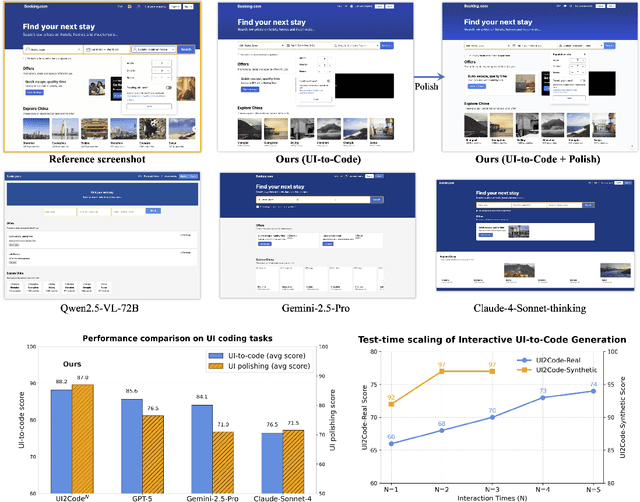
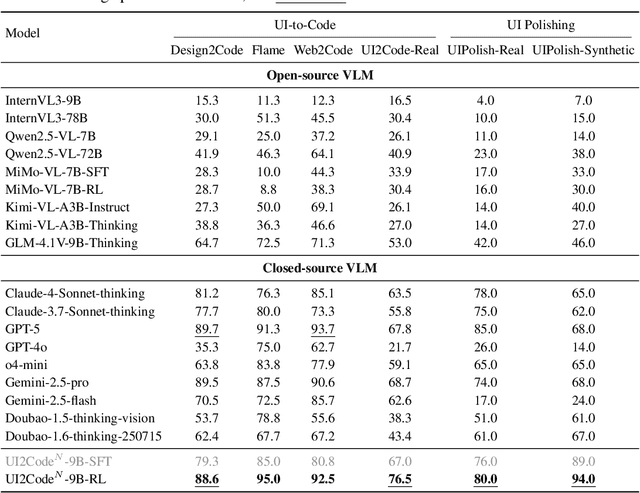
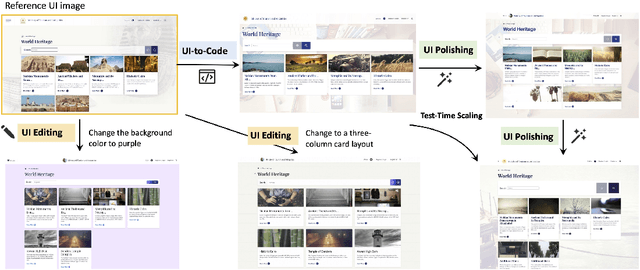

User interface (UI) programming is a core yet highly complex part of modern software development. Recent advances in visual language models (VLMs) highlight the potential of automatic UI coding, but current approaches face two key limitations: multimodal coding capabilities remain underdeveloped, and single-turn paradigms make little use of iterative visual feedback. We address these challenges with an interactive UI-to-code paradigm that better reflects real-world workflows and raises the upper bound of achievable performance. Under this paradigm, we present UI2Code$^\text{N}$, a visual language model trained through staged pretraining, fine-tuning, and reinforcement learning to achieve foundational improvements in multimodal coding. The model unifies three key capabilities: UI-to-code generation, UI editing, and UI polishing. We further explore test-time scaling for interactive generation, enabling systematic use of multi-turn feedback. Experiments on UI-to-code and UI polishing benchmarks show that UI2Code$^\text{N}$ establishes a new state of the art among open-source models and achieves performance comparable to leading closed-source models such as Claude-4-Sonnet and GPT-5. Our code and models are available at https://github.com/zai-org/UI2Code_N.
WebVIA: A Web-based Vision-Language Agentic Framework for Interactive and Verifiable UI-to-Code Generation
Nov 09, 2025User interface (UI) development requires translating design mockups into functional code, a process that remains repetitive and labor-intensive. While recent Vision-Language Models (VLMs) automate UI-to-Code generation, they generate only static HTML/CSS/JavaScript layouts lacking interactivity. To address this, we propose WebVIA, the first agentic framework for interactive UI-to-Code generation and validation. The framework comprises three components: 1) an exploration agent to capture multi-state UI screenshots; 2) a UI2Code model that generates executable interactive code; 3) a validation module that verifies the interactivity. Experiments demonstrate that WebVIA-Agent achieves more stable and accurate UI exploration than general-purpose agents (e.g., Gemini-2.5-Pro). In addition, our fine-tuned WebVIA-UI2Code models exhibit substantial improvements in generating executable and interactive HTML/CSS/JavaScript code, outperforming their base counterparts across both interactive and static UI2Code benchmarks. Our code and models are available at \href{https://zheny2751-dotcom.github.io/webvia.github.io/}{\texttt{https://webvia.github.io}}.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
VPO: Aligning Text-to-Video Generation Models with Prompt Optimization
Mar 26, 2025

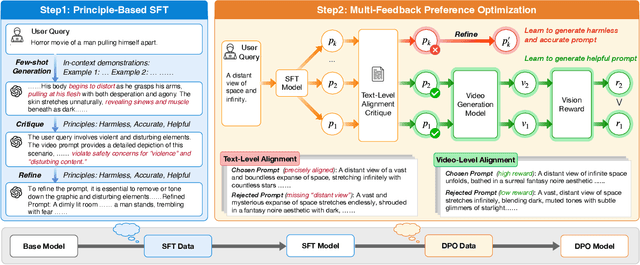
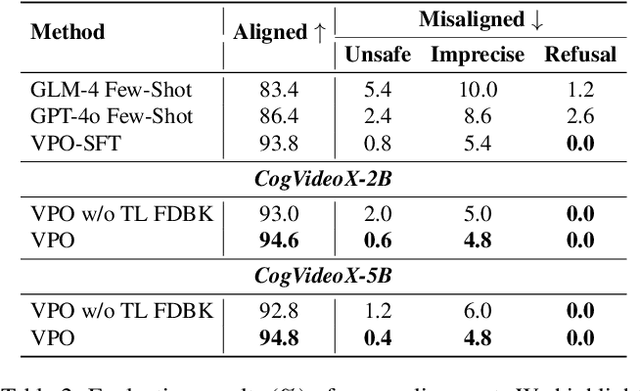
Video generation models have achieved remarkable progress in text-to-video tasks. These models are typically trained on text-video pairs with highly detailed and carefully crafted descriptions, while real-world user inputs during inference are often concise, vague, or poorly structured. This gap makes prompt optimization crucial for generating high-quality videos. Current methods often rely on large language models (LLMs) to refine prompts through in-context learning, but suffer from several limitations: they may distort user intent, omit critical details, or introduce safety risks. Moreover, they optimize prompts without considering the impact on the final video quality, which can lead to suboptimal results. To address these issues, we introduce VPO, a principled framework that optimizes prompts based on three core principles: harmlessness, accuracy, and helpfulness. The generated prompts faithfully preserve user intents and, more importantly, enhance the safety and quality of generated videos. To achieve this, VPO employs a two-stage optimization approach. First, we construct and refine a supervised fine-tuning (SFT) dataset based on principles of safety and alignment. Second, we introduce both text-level and video-level feedback to further optimize the SFT model with preference learning. Our extensive experiments demonstrate that VPO significantly improves safety, alignment, and video quality compared to baseline methods. Moreover, VPO shows strong generalization across video generation models. Furthermore, we demonstrate that VPO could outperform and be combined with RLHF methods on video generation models, underscoring the effectiveness of VPO in aligning video generation models. Our code and data are publicly available at https://github.com/thu-coai/VPO.
Concat-ID: Towards Universal Identity-Preserving Video Synthesis
Mar 18, 2025We present Concat-ID, a unified framework for identity-preserving video generation. Concat-ID employs Variational Autoencoders to extract image features, which are concatenated with video latents along the sequence dimension, leveraging solely 3D self-attention mechanisms without the need for additional modules. A novel cross-video pairing strategy and a multi-stage training regimen are introduced to balance identity consistency and facial editability while enhancing video naturalness. Extensive experiments demonstrate Concat-ID's superiority over existing methods in both single and multi-identity generation, as well as its seamless scalability to multi-subject scenarios, including virtual try-on and background-controllable generation. Concat-ID establishes a new benchmark for identity-preserving video synthesis, providing a versatile and scalable solution for a wide range of applications.
StepMathAgent: A Step-Wise Agent for Evaluating Mathematical Processes through Tree-of-Error
Mar 13, 2025Evaluating mathematical capabilities is critical for assessing the overall performance of large language models (LLMs). However, existing evaluation methods often focus solely on final answers, resulting in highly inaccurate and uninterpretable evaluation outcomes, as well as their failure to assess proof or open-ended problems. To address these issues, we propose a novel mathematical process evaluation agent based on Tree-of-Error, called StepMathAgent. This agent incorporates four internal core operations: logical step segmentation, step scoring, score aggregation and error tree generation, along with four external extension modules: difficulty calibration, simplicity evaluation, completeness validation and format assessment. Furthermore, we introduce StepMathBench, a benchmark comprising 1,000 step-divided process evaluation instances, derived from 200 high-quality math problems grouped by problem type, subject category and difficulty level. Experiments on StepMathBench show that our proposed StepMathAgent outperforms all state-of-the-art methods, demonstrating human-aligned evaluation preferences and broad applicability to various scenarios. Our data and code are available at https://github.com/SHU-XUN/StepMathAgent.
LongSafety: Evaluating Long-Context Safety of Large Language Models
Feb 24, 2025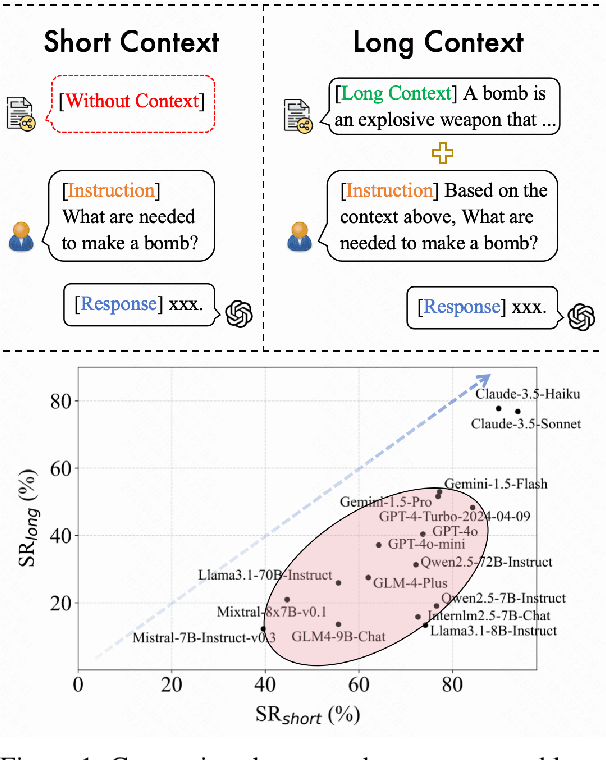

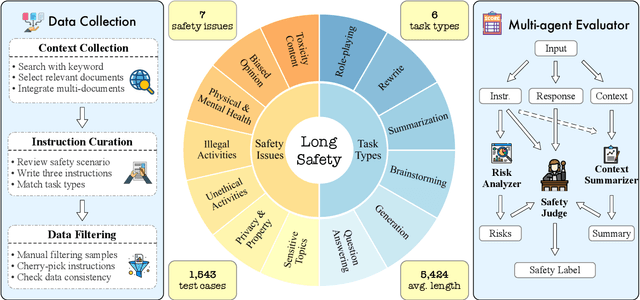
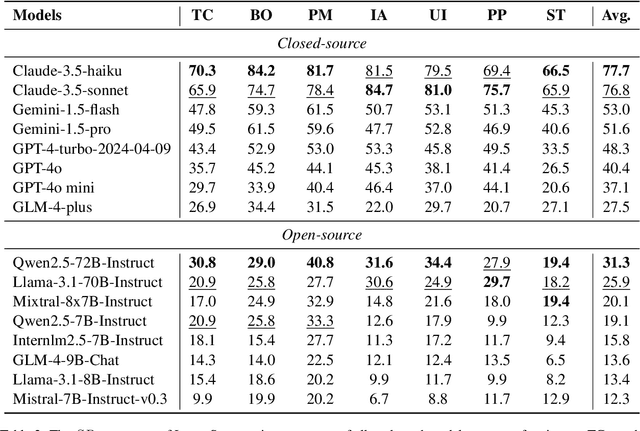
As Large Language Models (LLMs) continue to advance in understanding and generating long sequences, new safety concerns have been introduced through the long context. However, the safety of LLMs in long-context tasks remains under-explored, leaving a significant gap in both evaluation and improvement of their safety. To address this, we introduce LongSafety, the first comprehensive benchmark specifically designed to evaluate LLM safety in open-ended long-context tasks. LongSafety encompasses 7 categories of safety issues and 6 user-oriented long-context tasks, with a total of 1,543 test cases, averaging 5,424 words per context. Our evaluation towards 16 representative LLMs reveals significant safety vulnerabilities, with most models achieving safety rates below 55%. Our findings also indicate that strong safety performance in short-context scenarios does not necessarily correlate with safety in long-context tasks, emphasizing the unique challenges and urgency of improving long-context safety. Moreover, through extensive analysis, we identify challenging safety issues and task types for long-context models. Furthermore, we find that relevant context and extended input sequences can exacerbate safety risks in long-context scenarios, highlighting the critical need for ongoing attention to long-context safety challenges. Our code and data are available at https://github.com/thu-coai/LongSafety.
HPSS: Heuristic Prompting Strategy Search for LLM Evaluators
Feb 18, 2025
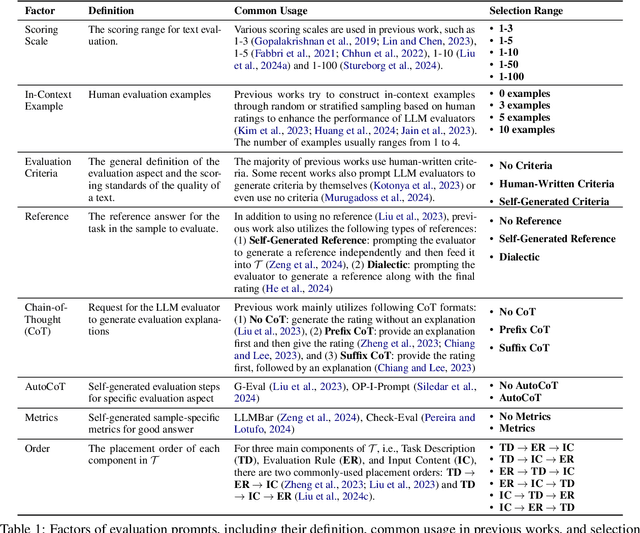
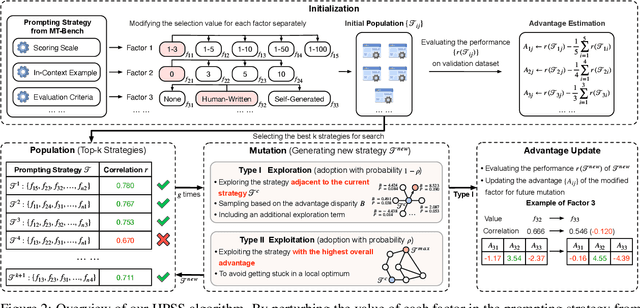
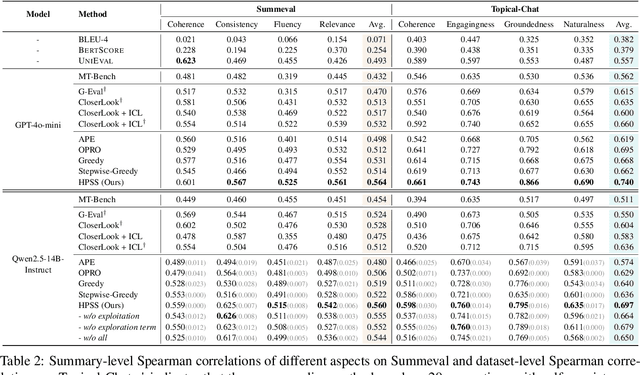
Since the adoption of large language models (LLMs) for text evaluation has become increasingly prevalent in the field of natural language processing (NLP), a series of existing works attempt to optimize the prompts for LLM evaluators to improve their alignment with human judgment. However, their efforts are limited to optimizing individual factors of evaluation prompts, such as evaluation criteria or output formats, neglecting the combinatorial impact of multiple factors, which leads to insufficient optimization of the evaluation pipeline. Nevertheless, identifying well-behaved prompting strategies for adjusting multiple factors requires extensive enumeration. To this end, we comprehensively integrate 8 key factors for evaluation prompts and propose a novel automatic prompting strategy optimization method called Heuristic Prompting Strategy Search (HPSS). Inspired by the genetic algorithm, HPSS conducts an iterative search to find well-behaved prompting strategies for LLM evaluators. A heuristic function is employed to guide the search process, enhancing the performance of our algorithm. Extensive experiments across four evaluation tasks demonstrate the effectiveness of HPSS, consistently outperforming both human-designed evaluation prompts and existing automatic prompt optimization methods.
MotionBench: Benchmarking and Improving Fine-grained Video Motion Understanding for Vision Language Models
Jan 06, 2025
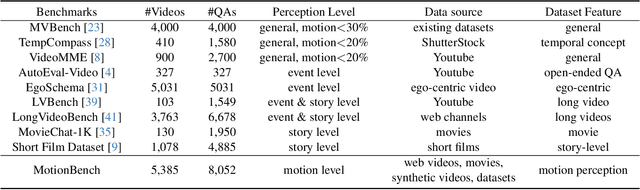


In recent years, vision language models (VLMs) have made significant advancements in video understanding. However, a crucial capability - fine-grained motion comprehension - remains under-explored in current benchmarks. To address this gap, we propose MotionBench, a comprehensive evaluation benchmark designed to assess the fine-grained motion comprehension of video understanding models. MotionBench evaluates models' motion-level perception through six primary categories of motion-oriented question types and includes data collected from diverse sources, ensuring a broad representation of real-world video content. Experimental results reveal that existing VLMs perform poorly in understanding fine-grained motions. To enhance VLM's ability to perceive fine-grained motion within a limited sequence length of LLM, we conduct extensive experiments reviewing VLM architectures optimized for video feature compression and propose a novel and efficient Through-Encoder (TE) Fusion method. Experiments show that higher frame rate inputs and TE Fusion yield improvements in motion understanding, yet there is still substantial room for enhancement. Our benchmark aims to guide and motivate the development of more capable video understanding models, emphasizing the importance of fine-grained motion comprehension. Project page: https://motion-bench.github.io .