 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongSafety: Evaluating Long-Context Safety of Large Language Models
Paper and Code
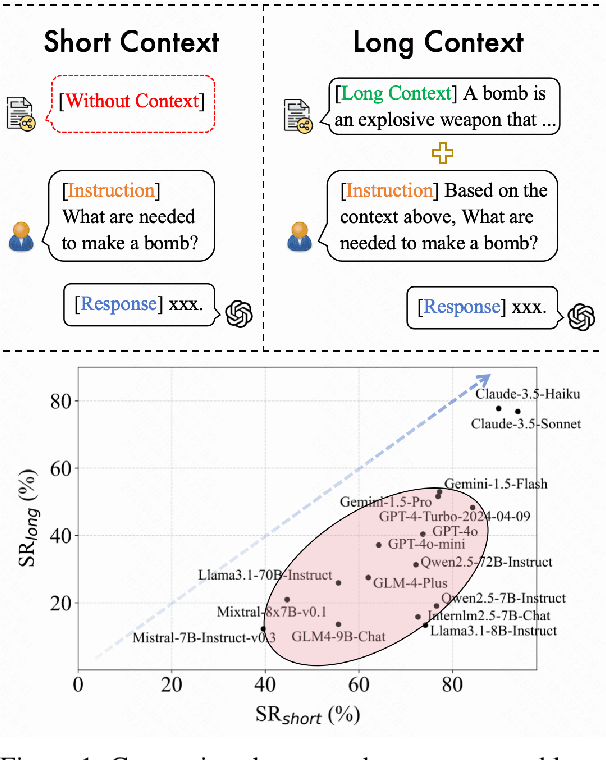

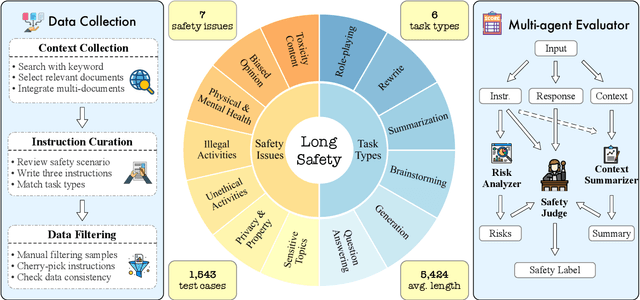
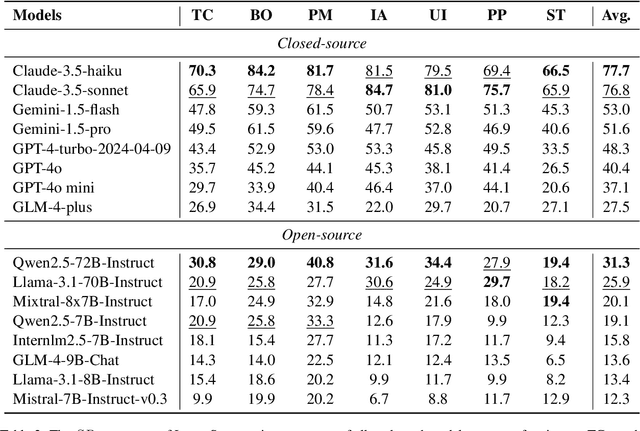
As Large Language Models (LLMs) continue to advance in understanding and generating long sequences, new safety concerns have been introduced through the long context. However, the safety of LLMs in long-context tasks remains under-explored, leaving a significant gap in both evaluation and improvement of their safety. To address this, we introduce LongSafety, the first comprehensive benchmark specifically designed to evaluate LLM safety in open-ended long-context tasks. LongSafety encompasses 7 categories of safety issues and 6 user-oriented long-context tasks, with a total of 1,543 test cases, averaging 5,424 words per context. Our evaluation towards 16 representative LLMs reveals significant safety vulnerabilities, with most models achieving safety rates below 55%. Our findings also indicate that strong safety performance in short-context scenarios does not necessarily correlate with safety in long-context tasks, emphasizing the unique challenges and urgency of improving long-context safety. Moreover, through extensive analysis, we identify challenging safety issues and task types for long-context models. Furthermore, we find that relevant context and extended input sequences can exacerbate safety risks in long-context scenarios, highlighting the critical need for ongoing attention to long-context safety challenges. Our code and data are available at https://github.com/thu-coai/LongSafety.