 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
CogVLM2: Visual Language Models for Image and Video Understanding
Aug 29, 2024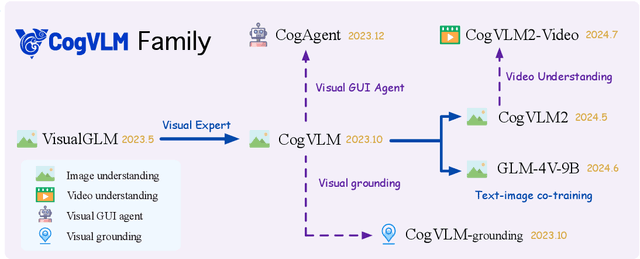

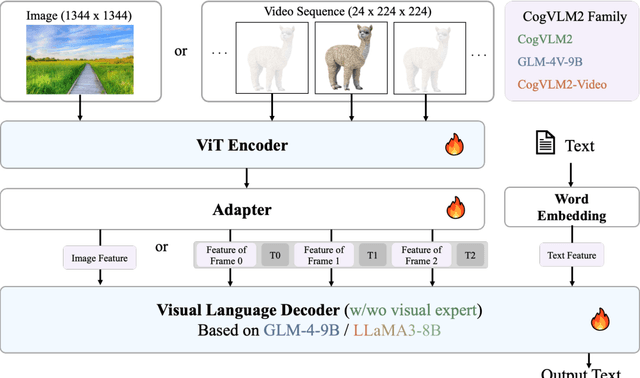
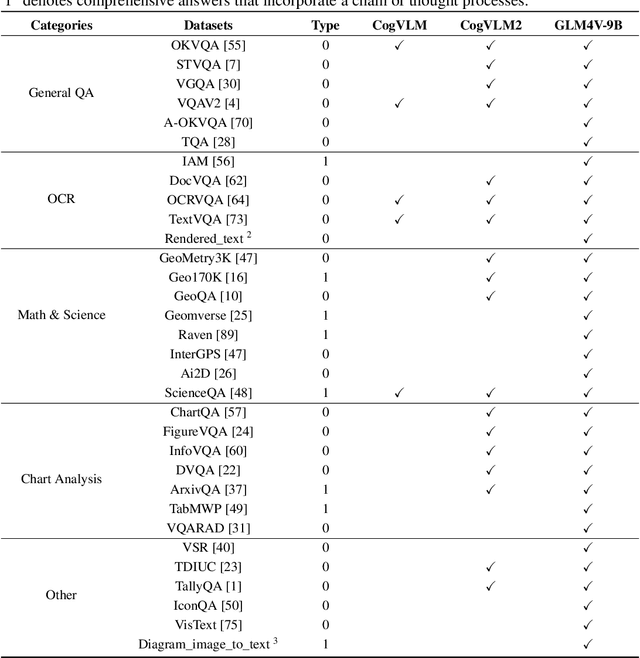
Beginning with VisualGLM and CogVLM, we are continuously exploring VLMs in pursuit of enhanced vision-language fusion, efficient higher-resolution architecture, and broader modalities and applications. Here we propose the CogVLM2 family, a new generation of visual language models for image and video understanding including CogVLM2, CogVLM2-Video and GLM-4V. As an image understanding model, CogVLM2 inherits the visual expert architecture with improved training recipes in both pre-training and post-training stages, supporting input resolution up to $1344 \times 1344$ pixels. As a video understanding model, CogVLM2-Video integrates multi-frame input with timestamps and proposes automated temporal grounding data construction. Notably, CogVLM2 family has achieved state-of-the-art results on benchmarks like MMBench, MM-Vet, TextVQA, MVBench and VCGBench. All models are open-sourced in https://github.com/THUDM/CogVLM2 and https://github.com/THUDM/GLM-4, contributing to the advancement of the field.
CogAgent: A Visual Language Model for GUI Agents
Dec 21, 2023



People are spending an enormous amount of time on digital devices through graphical user interfaces (GUIs), e.g., computer or smartphone screens. Large language models (LLMs) such as ChatGPT can assist people in tasks like writing emails, but struggle to understand and interact with GUIs, thus limiting their potential to increase automation levels. In this paper, we introduce CogAgent, an 18-billion-parameter visual language model (VLM) specializing in GUI understanding and navigation. By utilizing both low-resolution and high-resolution image encoders, CogAgent supports input at a resolution of 1120*1120, enabling it to recognize tiny page elements and text. As a generalist visual language model, CogAgent achieves the state of the art on five text-rich and four general VQA benchmarks, including VQAv2, OK-VQA, Text-VQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet, and POPE. CogAgent, using only screenshots as input, outperforms LLM-based methods that consume extracted HTML text on both PC and Android GUI navigation tasks -- Mind2Web and AITW, advancing the state of the art. The model and codes are available at https://github.com/THUDM/CogVLM .
CogVLM: Visual Expert for Pretrained Language Models
Nov 06, 2023We introduce CogVLM, a powerful open-source visual language foundation model. Different from the popular shallow alignment method which maps image features into the input space of language model, CogVLM bridges the gap between the frozen pretrained language model and image encoder by a trainable visual expert module in the attention and FFN layers. As a result, CogVLM enables deep fusion of vision language features without sacrificing any performance on NLP tasks. CogVLM-17B achieves state-of-the-art performance on 10 classic cross-modal benchmarks, including NoCaps, Flicker30k captioning, RefCOCO, RefCOCO+, RefCOCOg, Visual7W, GQA, ScienceQA, VizWiz VQA and TDIUC, and ranks the 2nd on VQAv2, OKVQA, TextVQA, COCO captioning, etc., surpassing or matching PaLI-X 55B. Codes and checkpoints are available at https://github.com/THUDM/CogVLM.