 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUI2Code^N: A Visual Language Model for Test-Time Scalable Interactive UI-to-Code Generation
Nov 14, 2025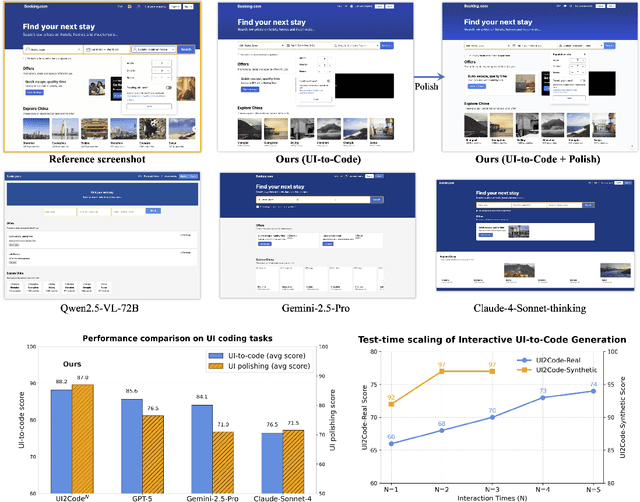
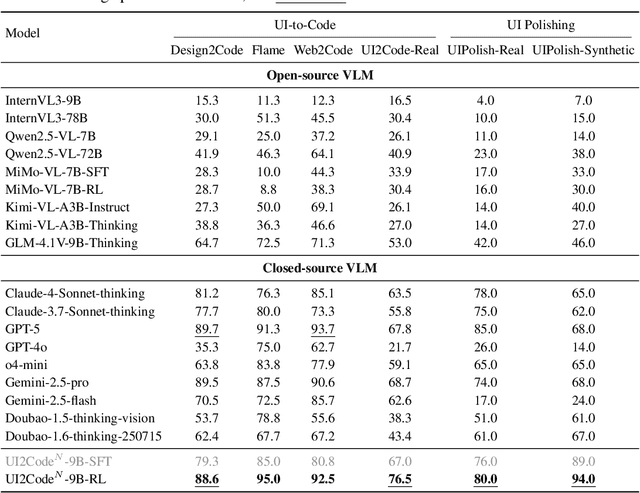
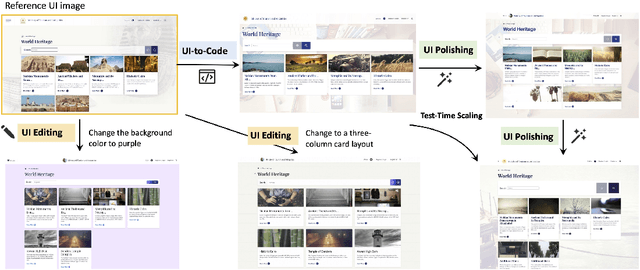

User interface (UI) programming is a core yet highly complex part of modern software development. Recent advances in visual language models (VLMs) highlight the potential of automatic UI coding, but current approaches face two key limitations: multimodal coding capabilities remain underdeveloped, and single-turn paradigms make little use of iterative visual feedback. We address these challenges with an interactive UI-to-code paradigm that better reflects real-world workflows and raises the upper bound of achievable performance. Under this paradigm, we present UI2Code$^\text{N}$, a visual language model trained through staged pretraining, fine-tuning, and reinforcement learning to achieve foundational improvements in multimodal coding. The model unifies three key capabilities: UI-to-code generation, UI editing, and UI polishing. We further explore test-time scaling for interactive generation, enabling systematic use of multi-turn feedback. Experiments on UI-to-code and UI polishing benchmarks show that UI2Code$^\text{N}$ establishes a new state of the art among open-source models and achieves performance comparable to leading closed-source models such as Claude-4-Sonnet and GPT-5. Our code and models are available at https://github.com/zai-org/UI2Code_N.
WebVIA: A Web-based Vision-Language Agentic Framework for Interactive and Verifiable UI-to-Code Generation
Nov 09, 2025User interface (UI) development requires translating design mockups into functional code, a process that remains repetitive and labor-intensive. While recent Vision-Language Models (VLMs) automate UI-to-Code generation, they generate only static HTML/CSS/JavaScript layouts lacking interactivity. To address this, we propose WebVIA, the first agentic framework for interactive UI-to-Code generation and validation. The framework comprises three components: 1) an exploration agent to capture multi-state UI screenshots; 2) a UI2Code model that generates executable interactive code; 3) a validation module that verifies the interactivity. Experiments demonstrate that WebVIA-Agent achieves more stable and accurate UI exploration than general-purpose agents (e.g., Gemini-2.5-Pro). In addition, our fine-tuned WebVIA-UI2Code models exhibit substantial improvements in generating executable and interactive HTML/CSS/JavaScript code, outperforming their base counterparts across both interactive and static UI2Code benchmarks. Our code and models are available at \href{https://zheny2751-dotcom.github.io/webvia.github.io/}{\texttt{https://webvia.github.io}}.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
MotionBench: Benchmarking and Improving Fine-grained Video Motion Understanding for Vision Language Models
Jan 06, 2025
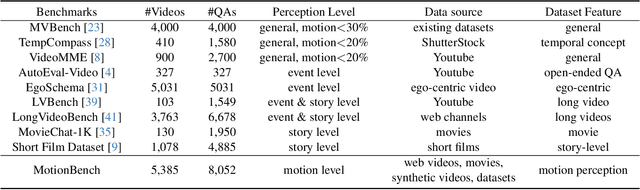


In recent years, vision language models (VLMs) have made significant advancements in video understanding. However, a crucial capability - fine-grained motion comprehension - remains under-explored in current benchmarks. To address this gap, we propose MotionBench, a comprehensive evaluation benchmark designed to assess the fine-grained motion comprehension of video understanding models. MotionBench evaluates models' motion-level perception through six primary categories of motion-oriented question types and includes data collected from diverse sources, ensuring a broad representation of real-world video content. Experimental results reveal that existing VLMs perform poorly in understanding fine-grained motions. To enhance VLM's ability to perceive fine-grained motion within a limited sequence length of LLM, we conduct extensive experiments reviewing VLM architectures optimized for video feature compression and propose a novel and efficient Through-Encoder (TE) Fusion method. Experiments show that higher frame rate inputs and TE Fusion yield improvements in motion understanding, yet there is still substantial room for enhancement. Our benchmark aims to guide and motivate the development of more capable video understanding models, emphasizing the importance of fine-grained motion comprehension. Project page: https://motion-bench.github.io .
CogVLM2: Visual Language Models for Image and Video Understanding
Aug 29, 2024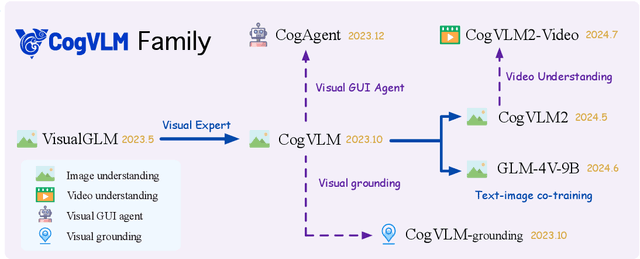

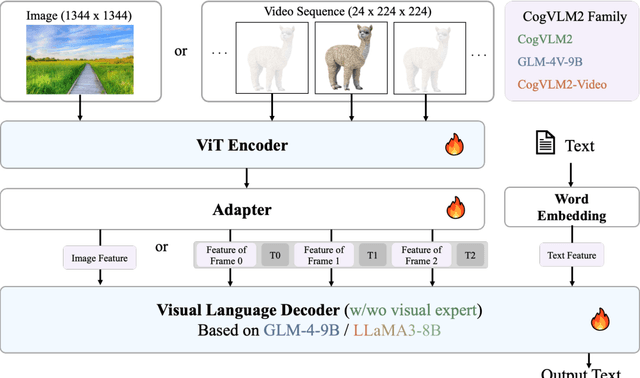
Beginning with VisualGLM and CogVLM, we are continuously exploring VLMs in pursuit of enhanced vision-language fusion, efficient higher-resolution architecture, and broader modalities and applications. Here we propose the CogVLM2 family, a new generation of visual language models for image and video understanding including CogVLM2, CogVLM2-Video and GLM-4V. As an image understanding model, CogVLM2 inherits the visual expert architecture with improved training recipes in both pre-training and post-training stages, supporting input resolution up to $1344 \times 1344$ pixels. As a video understanding model, CogVLM2-Video integrates multi-frame input with timestamps and proposes automated temporal grounding data construction. Notably, CogVLM2 family has achieved state-of-the-art results on benchmarks like MMBench, MM-Vet, TextVQA, MVBench and VCGBench. All models are open-sourced in https://github.com/THUDM/CogVLM2 and https://github.com/THUDM/GLM-4, contributing to the advancement of the field.
VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents
Aug 12, 2024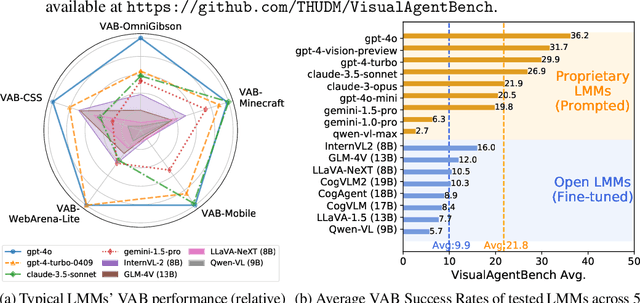
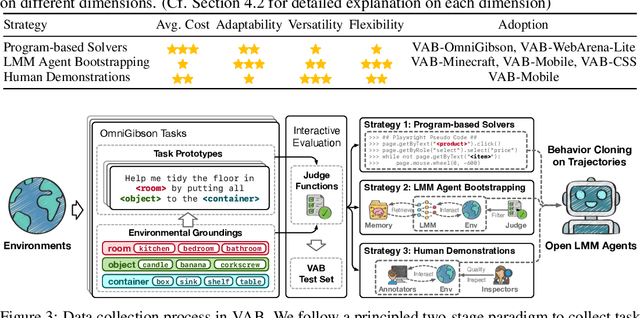
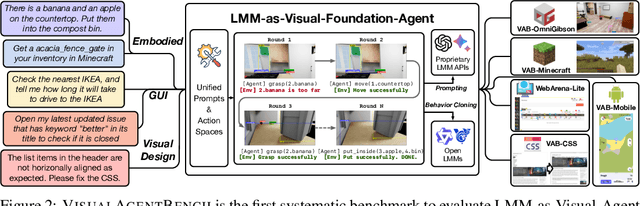
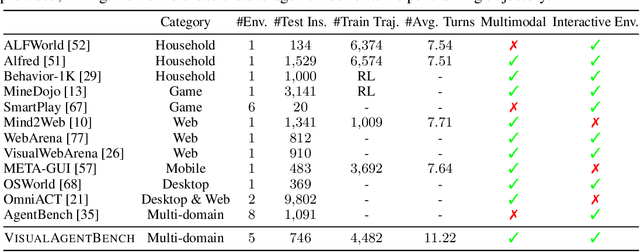
Large Multimodal Models (LMMs) have ushered in a new era in artificial intelligence, merging capabilities in both language and vision to form highly capable Visual Foundation Agents. These agents are postulated to excel across a myriad of tasks, potentially approaching general artificial intelligence. However, existing benchmarks fail to sufficiently challenge or showcase the full potential of LMMs in complex, real-world environments. To address this gap, we introduce VisualAgentBench (VAB), a comprehensive and pioneering benchmark specifically designed to train and evaluate LMMs as visual foundation agents across diverse scenarios, including Embodied, Graphical User Interface, and Visual Design, with tasks formulated to probe the depth of LMMs' understanding and interaction capabilities. Through rigorous testing across nine proprietary LMM APIs and eight open models, we demonstrate the considerable yet still developing agent capabilities of these models. Additionally, VAB constructs a trajectory training set constructed through hybrid methods including Program-based Solvers, LMM Agent Bootstrapping, and Human Demonstrations, promoting substantial performance improvements in LMMs through behavior cloning. Our work not only aims to benchmark existing models but also provides a solid foundation for future development into visual foundation agents. Code, train \& test data, and part of fine-tuned open LMMs are available at \url{https://github.com/THUDM/VisualAgentBench}.
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Aug 12, 2024We introduce CogVideoX, a large-scale diffusion transformer model designed for generating videos based on text prompts. To efficently model video data, we propose to levearge a 3D Variational Autoencoder (VAE) to compress videos along both spatial and temporal dimensions. To improve the text-video alignment, we propose an expert transformer with the expert adaptive LayerNorm to facilitate the deep fusion between the two modalities. By employing a progressive training technique, CogVideoX is adept at producing coherent, long-duration videos characterized by significant motions. In addition, we develop an effective text-video data processing pipeline that includes various data preprocessing strategies and a video captioning method. It significantly helps enhance the performance of CogVideoX, improving both generation quality and semantic alignment. Results show that CogVideoX demonstrates state-of-the-art performance across both multiple machine metrics and human evaluations. The model weights of both the 3D Causal VAE and CogVideoX are publicly available at https://github.com/THUDM/CogVideo.
LVBench: An Extreme Long Video Understanding Benchmark
Jun 12, 2024

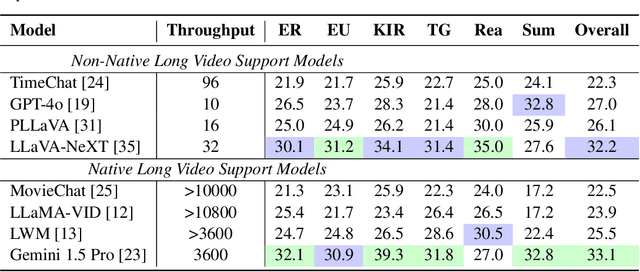
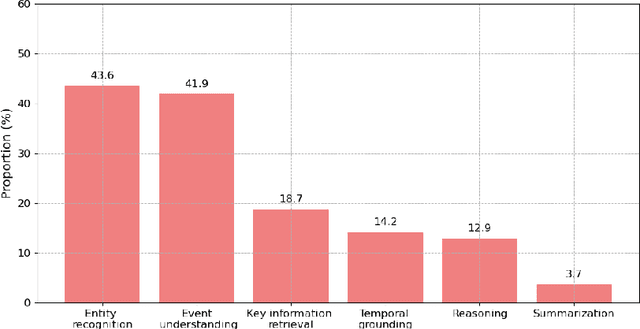
Recent progress in multimodal large language models has markedly enhanced the understanding of short videos (typically under one minute), and several evaluation datasets have emerged accordingly. However, these advancements fall short of meeting the demands of real-world applications such as embodied intelligence for long-term decision-making, in-depth movie reviews and discussions, and live sports commentary, all of which require comprehension of long videos spanning several hours. To address this gap, we introduce LVBench, a benchmark specifically designed for long video understanding. Our dataset comprises publicly sourced videos and encompasses a diverse set of tasks aimed at long video comprehension and information extraction. LVBench is designed to challenge multimodal models to demonstrate long-term memory and extended comprehension capabilities. Our extensive evaluations reveal that current multimodal models still underperform on these demanding long video understanding tasks. Through LVBench, we aim to spur the development of more advanced models capable of tackling the complexities of long video comprehension. Our data and code are publicly available at: https://lvbench.github.io.
Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer
May 08, 2024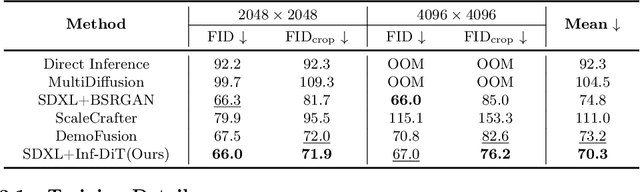
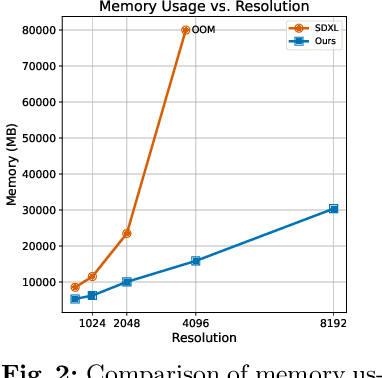

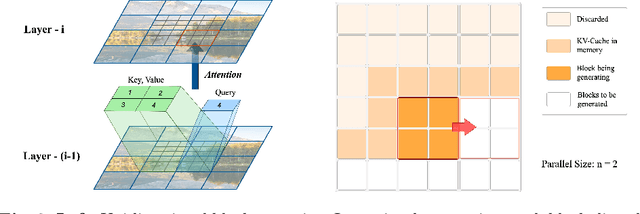
Diffusion models have shown remarkable performance in image generation in recent years. However, due to a quadratic increase in memory during generating ultra-high-resolution images (e.g. 4096*4096), the resolution of generated images is often limited to 1024*1024. In this work. we propose a unidirectional block attention mechanism that can adaptively adjust the memory overhead during the inference process and handle global dependencies. Building on this module, we adopt the DiT structure for upsampling and develop an infinite super-resolution model capable of upsampling images of various shapes and resolutions. Comprehensive experiments show that our model achieves SOTA performance in generating ultra-high-resolution images in both machine and human evaluation. Compared to commonly used UNet structures, our model can save more than 5x memory when generating 4096*4096 images. The project URL is https://github.com/THUDM/Inf-DiT.
CogCoM: Train Large Vision-Language Models Diving into Details through Chain of Manipulations
Feb 06, 2024



Vision-Language Models (VLMs) have demonstrated their widespread viability thanks to extensive training in aligning visual instructions to answers. However, this conclusive alignment leads models to ignore critical visual reasoning, and further result in failures on meticulous visual problems and unfaithful responses. In this paper, we propose Chain of Manipulations, a mechanism that enables VLMs to solve problems with a series of manipulations, where each manipulation refers to an operation on the visual input, either from intrinsic abilities (e.g., grounding) acquired through prior training or from imitating human-like behaviors (e.g., zoom in). This mechanism encourages VLMs to generate faithful responses with evidential visual reasoning, and permits users to trace error causes in the interpretable paths. We thus train CogCoM, a general 17B VLM with a memory-based compatible architecture endowed this reasoning mechanism. Experiments show that our model achieves the state-of-the-art performance across 8 benchmarks from 3 categories, and a limited number of training steps with the data swiftly gains a competitive performance. The code and data are publicly available at https://github.com/THUDM/CogCoM.