 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRingMo-Agent: A Unified Remote Sensing Foundation Model for Multi-Platform and Multi-Modal Reasoning
Jul 28, 2025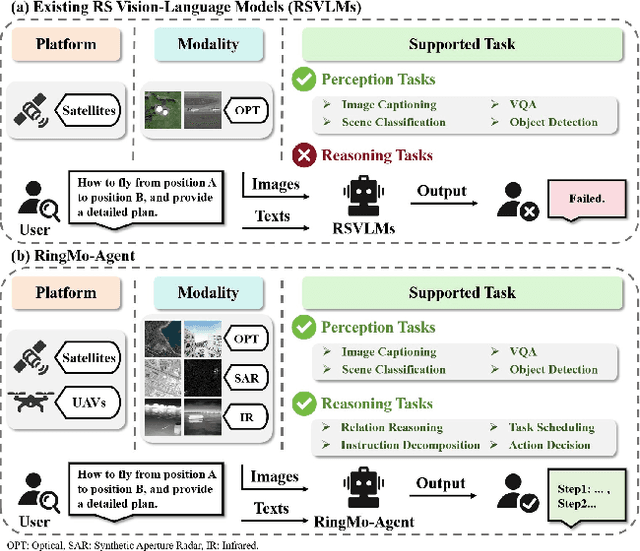
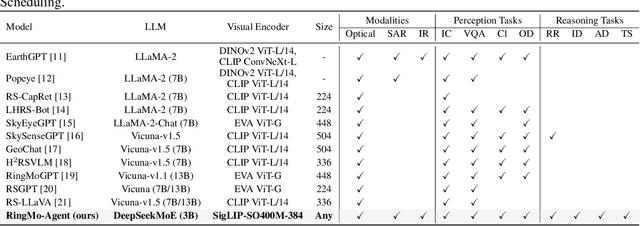

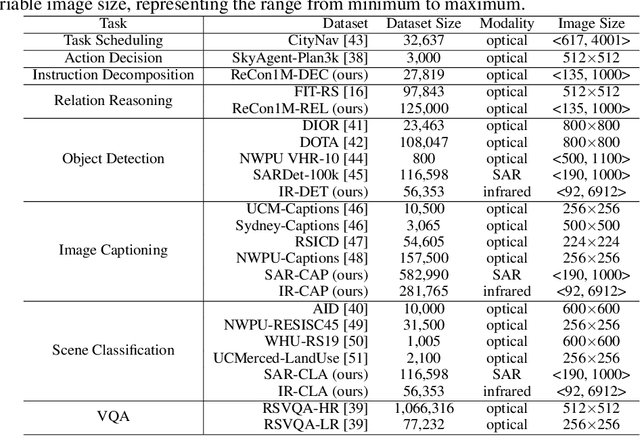
Remote sensing (RS) images from multiple modalities and platforms exhibit diverse details due to differences in sensor characteristics and imaging perspectives. Existing vision-language research in RS largely relies on relatively homogeneous data sources. Moreover, they still remain limited to conventional visual perception tasks such as classification or captioning. As a result, these methods fail to serve as a unified and standalone framework capable of effectively handling RS imagery from diverse sources in real-world applications. To address these issues, we propose RingMo-Agent, a model designed to handle multi-modal and multi-platform data that performs perception and reasoning tasks based on user textual instructions. Compared with existing models, RingMo-Agent 1) is supported by a large-scale vision-language dataset named RS-VL3M, comprising over 3 million image-text pairs, spanning optical, SAR, and infrared (IR) modalities collected from both satellite and UAV platforms, covering perception and challenging reasoning tasks; 2) learns modality adaptive representations by incorporating separated embedding layers to construct isolated features for heterogeneous modalities and reduce cross-modal interference; 3) unifies task modeling by introducing task-specific tokens and employing a token-based high-dimensional hidden state decoding mechanism designed for long-horizon spatial tasks. Extensive experiments on various RS vision-language tasks demonstrate that RingMo-Agent not only proves effective in both visual understanding and sophisticated analytical tasks, but also exhibits strong generalizability across different platforms and sensing modalities.
Inconsistency-aware Uncertainty Estimation for Semi-supervised Medical Image Segmentation
Oct 17, 2021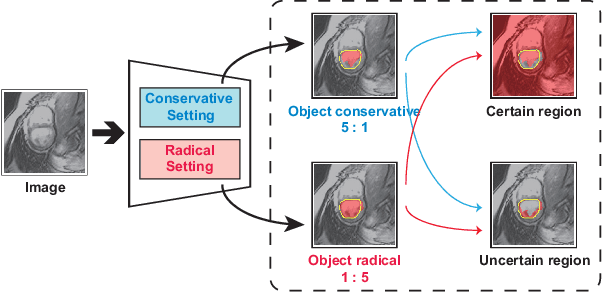

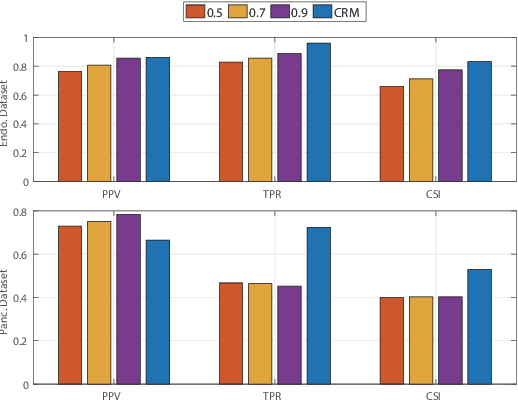

In semi-supervised medical image segmentation, most previous works draw on the common assumption that higher entropy means higher uncertainty. In this paper, we investigate a novel method of estimating uncertainty. We observe that, when assigned different misclassification costs in a certain degree, if the segmentation result of a pixel becomes inconsistent, this pixel shows a relative uncertainty in its segmentation. Therefore, we present a new semi-supervised segmentation model, namely, conservative-radical network (CoraNet in short) based on our uncertainty estimation and separate self-training strategy. In particular, our CoraNet model consists of three major components: a conservative-radical module (CRM), a certain region segmentation network (C-SN), and an uncertain region segmentation network (UC-SN) that could be alternatively trained in an end-to-end manner. We have extensively evaluated our method on various segmentation tasks with publicly available benchmark datasets, including CT pancreas, MR endocardium, and MR multi-structures segmentation on the ACDC dataset. Compared with the current state of the art, our CoraNet has demonstrated superior performance. In addition, we have also analyzed its connection with and difference from conventional methods of uncertainty estimation in semi-supervised medical image segmentation.
Class Distribution Alignment for Adversarial Domain Adaptation
Apr 20, 2020



Most existing unsupervised domain adaptation methods mainly focused on aligning the marginal distributions of samples between the source and target domains. This setting does not sufficiently consider the class distribution information between the two domains, which could adversely affect the reduction of domain gap. To address this issue, we propose a novel approach called Conditional ADversarial Image Translation (CADIT) to explicitly align the class distributions given samples between the two domains. It integrates a discriminative structure-preserving loss and a joint adversarial generation loss. The former effectively prevents undesired label-flipping during the whole process of image translation, while the latter maintains the joint distribution alignment of images and labels. Furthermore, our approach enforces the classification consistence of target domain images before and after adaptation to aid the classifier training in both domains. Extensive experiments were conducted on multiple benchmark datasets including Digits, Faces, Scenes and Office31, showing that our approach achieved superior classification in the target domain when compared to the state-of-the-art methods. Also, both qualitative and quantitative results well supported our motivation that aligning the class distributions can indeed improve domain adaptation.