 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Structured Low-Rank Adaptation for Continual Learning
May 26, 2026While orthogonal subspace methods try to mitigate task interference in Continual Learning (CL), they often suffer from energy diffusion across the basis, hindering knowledge compaction and exhausting capacity for future tasks. We observe that output feature drift induced by parameter updates is inherently low-rank, and theoretically prove that preserving parameters along the principal directions of this drift minimizes the output reconstruction error. Motivated by this, we propose \textbf{E}nergy-Concentrated and \textbf{E}nergy-Ordered \textbf{Lo}w-\textbf{R}ank \textbf{A}daptation (E$^2$-LoRA). By explicitly ordering and concentrating knowledge into leading ranks, E$^2$-LoRA frees capacity for subsequent tasks. Furthermore, we design a dynamic rank allocation strategy to balance stability and plasticity by jointly optimizing energy retention and model plasticity. Extensive experiments across multiple benchmarks demonstrate that E$^2$-LoRA achieves state-of-the-art performance.
Towards the Connection between Activation Sparsity and Flat Minima
May 25, 2026The observation that activation sparsity emerges in MLP blocks of standardly trained Transformers offers an opportunity to drastically reduce computation costs without sacrificing performance. To theoretically explain this phenomenon, existing works have shown that activation sparsity does not result from the data properties or data fitting but from the implicit bias of the training process. However, these connections are obtained with strong assumptions, which cannot be applied to deep models standardly trained with a large number of steps. Different from these works, we find that the flatness of loss landscapes is also closely related to the MLP activation sparsity and can serve as a weaker and naturally emerging assumption standard deep networks. Specifically, we find that 1) the MLP activation sparsity equals a ratio between "augmented flatness" (a weighted sum of flatness measures) and the product of the input norm and activation gradient of the MLP. We empirically find that this ratio decreases during training, leading to sparse activations. 2) We also propose the notion of derivative sparsity, which reduces to activation sparsity under ReLU, but further enables pruning in the backward propagation and is more stable than activation sparsity. With the theoretical findings, we can further encourage activation sparsity by decreasing the numerator and increasing the denominator of the ratio using three methods. These plug-and-play modifications can effectively reduce the ratio and produce sparser activations. Experiments on ImageNet-1K and C4 demonstrate relative improvements of at least 36% on inference sparsity and at least 50% on training sparsity over vanilla Transformers, indicating further potential cost reduction in both inference and training
IMPACT-CYCLE: A Contract-Based Multi-Agent System for Claim-Level Supervisory Correction of Long-Video Semantic Memory
Apr 22, 2026Correcting errors in long-video understanding is disproportionately costly: existing multimodal pipelines produce opaque, end-to-end outputs that expose no intermediate state for inspection, forcing annotators to revisit raw video and reconstruct temporal logic from scratch. The core bottleneck is not generation quality alone, but the absence of a supervisory interface through which human effort can be proportional to the scope of each error. We present IMPACT-CYCLE, a supervisory multi-agent system that reformulates long-video understanding as iterative claim-level maintenance of a shared semantic memory -- a structured, versioned state encoding typed claims, a claim dependency graph, and a provenance log. Role-specialized agents operating under explicit authority contracts decompose verification into local object-relation correctness, cross-temporal consistency, and global semantic coherence, with corrections confined to structurally dependent claims. When automated evidence is insufficient, the system escalates to human arbitration as the supervisory authority with final override rights; dependency-closure re-verification then ensures correction cost remains proportional to error scope. Experiments on VidOR show substantially improved downstream reasoning (VQA: 0.71 to 0.79) and a 4.8x reduction in human arbitration cost, with workload significantly lower than manual annotation. Code will be released at https://github.com/MKong17/IMPACT_CYCLE.
InterEdit: Navigating Text-Guided Multi-Human 3D Motion Editing
Mar 13, 2026Text-guided 3D motion editing has seen success in single-person scenarios, but its extension to multi-person settings is less explored due to limited paired data and the complexity of inter-person interactions. We introduce the task of multi-person 3D motion editing, where a target motion is generated from a source and a text instruction. To support this, we propose InterEdit3D, a new dataset with manual two-person motion change annotations, and a Text-guided Multi-human Motion Editing (TMME) benchmark. We present InterEdit, a synchronized classifier-free conditional diffusion model for TMME. It introduces Semantic-Aware Plan Token Alignment with learnable tokens to capture high-level interaction cues and an Interaction-Aware Frequency Token Alignment strategy using DCT and energy pooling to model periodic motion dynamics. Experiments show that InterEdit improves text-to-motion consistency and edit fidelity, achieving state-of-the-art TMME performance. The dataset and code will be released at https://github.com/YNG916/InterEdit.
One Token, Two Fates: A Unified Framework via Vision Token Manipulation Against MLLMs Hallucination
Mar 11, 2026Current training-free methods tackle MLLM hallucination with separate strategies: either enhancing visual signals or suppressing text inertia. However, these separate methods are insufficient due to critical trade-offs: simply enhancing vision often fails against strong language prior, while suppressing language can introduce extra image-irrelevant noise. Moreover, we find their naive combination is also ineffective, necessitating a unified framework. We propose such a framework by focusing on the core asset: the vision token. Our design leverages two key insights: (1) augmented images offer complementary visual semantics, and (2) removing vision tokens (information-gap) isolates hallucination tendencies more precisely than distorting images (modality-gap). Based on these, our framework uses vision tokens in two distinct ways, both operating on latent representations: our Synergistic Visual Calibration (SVC) module incorporates augmented tokens to strengthen visual representations, while our Causal Representation Calibration (CRC) module uses pruned tokens to create latent-space negative samples for correcting internal model biases. By harmonizing these two roles, our framework effectively restores the vision-language balance, significantly reducing object hallucinations, improving POPE accuracy by an average of 2% absolute on LLaVA-1.5 across multiple benchmarks with only a 1.06x inference latency overhead.
RTLocating: Intent-aware RTL Localization for Hardware Design Iteration
Feb 28, 2026Industrial chip development is inherently iterative, favoring localized, intent-driven updates over rewriting RTL from scratch. Yet most LLM-Aided Hardware Design (LAD) work focuses on one-shot synthesis, leaving this workflow underexplored. To bridge this gap, we for the first time formalize $Δ$Spec-to-RTL localization, a multi-positive problem mapping natural language change requests ($Δ$Spec) to the affected Register Transfer Level (RTL) syntactic blocks. We propose RTLocating, an intent-aware RTL localization framework, featuring a dynamic router that adaptively fuses complementary views from a textual semantic encoder, a local structural encoder, and a global interaction and dependency encoder (GLIDE). To enable scalable supervision, we introduce EvoRTL-Bench, the first industrial-scale benchmark for intent-code alignment derived from OpenTitan's Git history, comprising 1,905 validated requests and 13,583 $Δ$Spec-RTL block pairs. On EvoRTL-Bench, RTLocating achieves 0.568 MRR and 15.08% R@1, outperforming the strongest baseline by +22.9% and +67.0%, respectively, establishing a new state-of-the-art for intent-driven localization in evolving hardware designs.
Model Merging in the Essential Subspace
Feb 23, 2026Model merging aims to integrate multiple task-specific fine-tuned models derived from a shared pre-trained checkpoint into a single multi-task model without additional training. Despite extensive research, task interference remains a major obstacle that often undermines the performance of merged models. In this paper, we propose ESM (Essential Subspace Merging) , a robust framework for effective model merging. We begin by performing Principal Component Analysis (PCA) on feature shifts induced by parameter updates. The resulting principal directions span an essential subspace that dominantly influences feature representations. Each task's parameter update matrix is projected onto its respective essential subspace for low-rank decomposition before merging. This methodology mitigates inter-task interference while preserving core task-specific functionality. Furthermore, we introduce a multi-level polarized scaling strategy that amplifies parameters containing critical knowledge and suppresses redundant ones, preventing essential knowledge from being overwhelmed during fusion. Extensive experiments across multiple task sets and model scales demonstrate that our method achieves state-of-the-art performance in multi-task model merging.
Decomposing and Composing: Towards Efficient Vision-Language Continual Learning via Rank-1 Expert Pool in a Single LoRA
Jan 30, 2026Continual learning (CL) in vision-language models (VLMs) faces significant challenges in improving task adaptation and avoiding catastrophic forgetting. Existing methods usually have heavy inference burden or rely on external knowledge, while Low-Rank Adaptation (LoRA) has shown potential in reducing these issues by enabling parameter-efficient tuning. However, considering directly using LoRA to alleviate the catastrophic forgetting problem is non-trivial, we introduce a novel framework that restructures a single LoRA module as a decomposable Rank-1 Expert Pool. Our method learns to dynamically compose a sparse, task-specific update by selecting from this expert pool, guided by the semantics of the [CLS] token. In addition, we propose an Activation-Guided Orthogonal (AGO) loss that orthogonalizes critical parts of LoRA weights across tasks. This sparse composition and orthogonalization enable fewer parameter updates, resulting in domain-aware learning while minimizing inter-task interference and maintaining downstream task performance. Extensive experiments across multiple settings demonstrate state-of-the-art results in all metrics, surpassing zero-shot upper bounds in generalization. Notably, it reduces trainable parameters by 96.7% compared to the baseline method, eliminating reliance on external datasets or task-ID discriminators. The merged LoRAs retain less weights and incur no inference latency, making our method computationally lightweight.
Leveraging Flatness to Improve Information-Theoretic Generalization Bounds for SGD
Jan 04, 2026Information-theoretic (IT) generalization bounds have been used to study the generalization of learning algorithms. These bounds are intrinsically data- and algorithm-dependent so that one can exploit the properties of data and algorithm to derive tighter bounds. However, we observe that although the flatness bias is crucial for SGD's generalization, these bounds fail to capture the improved generalization under better flatness and are also numerically loose. This is caused by the inadequate leverage of SGD's flatness bias in existing IT bounds. This paper derives a more flatness-leveraging IT bound for the flatness-favoring SGD. The bound indicates the learned models generalize better if the large-variance directions of the final weight covariance have small local curvatures in the loss landscape. Experiments on deep neural networks show our bound not only correctly reflects the better generalization when flatness is improved, but is also numerically much tighter. This is achieved by a flexible technique called "omniscient trajectory". When applied to Gradient Descent's minimax excess risk on convex-Lipschitz-Bounded problems, it improves representative IT bounds' $Ω(1)$ rates to $O(1/\sqrt{n})$. It also implies a by-pass of memorization-generalization trade-offs.
* Published as a conference paper at ICLR 2025
MAGIC: Achieving Superior Model Merging via Magnitude Calibration
Dec 22, 2025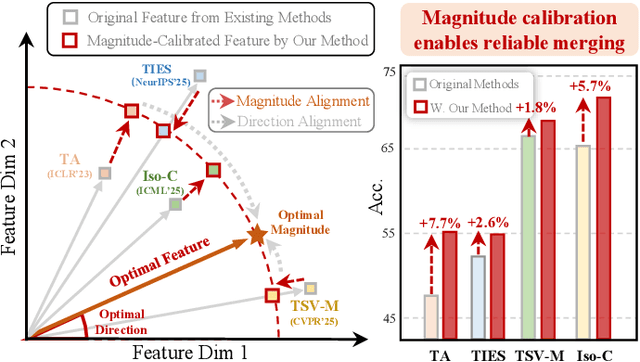
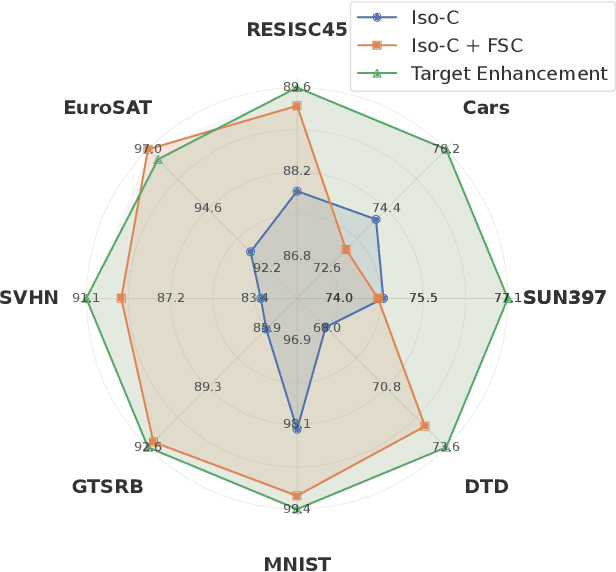
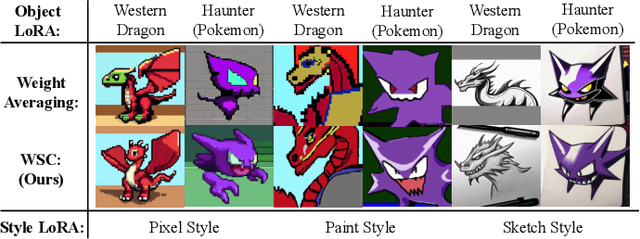
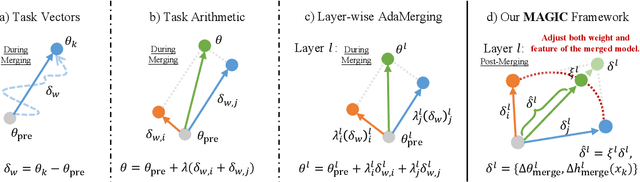
The proliferation of pre-trained models has given rise to a wide array of specialised, fine-tuned models. Model merging aims to merge the distinct capabilities of these specialised models into a unified model, requiring minimal or even no additional training. A core objective of model merging is to ensure the merged model retains the behavioural characteristics of the specialised models, typically achieved through feature alignment. We identify that features consist of two critical components: direction and magnitude. Prior research has predominantly focused on directional alignment, while the influence of magnitude remains largely neglected, despite its pronounced vulnerability to perturbations introduced by common merging operations (e.g., parameter fusion and sparsification). Such perturbations to magnitude inevitably lead to feature deviations in the merged model from the specialised models, resulting in subsequent performance degradation. To address this, we propose MAGnItude Calibration (MAGIC), a plug-and-play framework that rectifies layer-wise magnitudes in feature and weight spaces, with three variants. Specifically, our Feature Space Calibration (FSC) realigns the merged model's features using a small set of unlabelled data, while Weight Space Calibration (WSC) extends this calibration to the weight space without requiring additional data. Combining these yields Dual Space Calibration (DSC). Comprehensive experiments demonstrate that MAGIC consistently boosts performance across diverse Computer Vision tasks (+4.3% on eight datasets) and NLP tasks (+8.0% on Llama) without additional training. Our code is available at: https://github.com/lyymuwu/MAGIC