 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatStyler: Advancing Multi-category Style Generation for Source-free Domain Generalization
Jan 02, 2025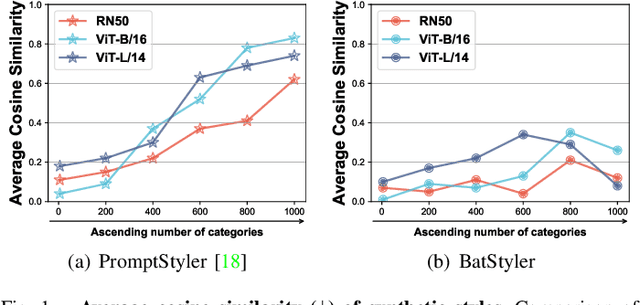
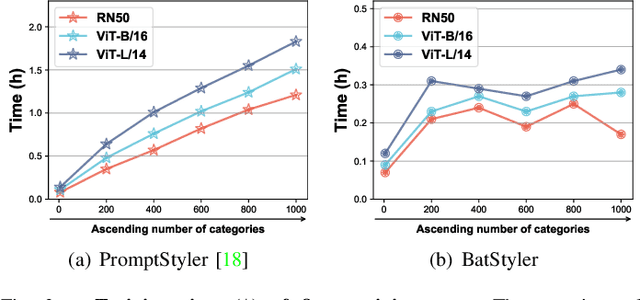
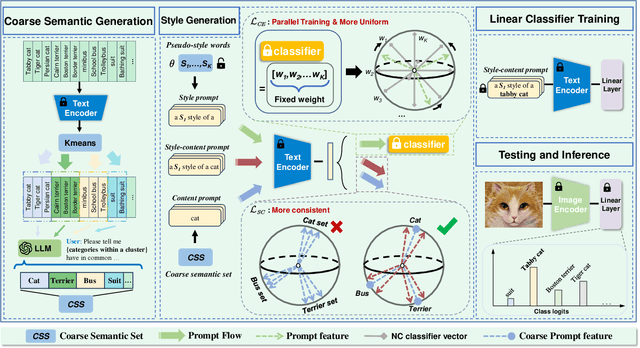
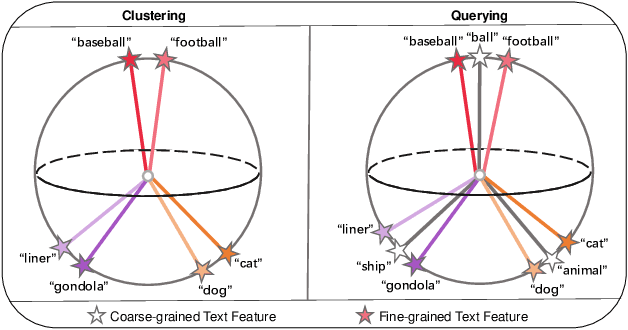
Source-Free Domain Generalization (SFDG) aims to develop a model that performs on unseen domains without relying on any source domains. However, the implementation remains constrained due to the unavailability of training data. Research on SFDG focus on knowledge transfer of multi-modal models and style synthesis based on joint space of multiple modalities, thus eliminating the dependency on source domain images. However, existing works primarily work for multi-domain and less-category configuration, but performance on multi-domain and multi-category configuration is relatively poor. In addition, the efficiency of style synthesis also deteriorates in multi-category scenarios. How to efficiently synthesize sufficiently diverse data and apply it to multi-category configuration is a direction with greater practical value. In this paper, we propose a method called BatStyler, which is utilized to improve the capability of style synthesis in multi-category scenarios. BatStyler consists of two modules: Coarse Semantic Generation and Uniform Style Generation modules. The Coarse Semantic Generation module extracts coarse-grained semantics to prevent the compression of space for style diversity learning in multi-category configuration, while the Uniform Style Generation module provides a template of styles that are uniformly distributed in space and implements parallel training. Extensive experiments demonstrate that our method exhibits comparable performance on less-category datasets, while surpassing state-of-the-art methods on multi-category datasets.
Costal Cartilage Segmentation with Topology Guided Deformable Mamba: Method and Benchmark
Aug 14, 2024



Costal cartilage segmentation is crucial to various medical applications, necessitating precise and reliable techniques due to its complex anatomy and the importance of accurate diagnosis and surgical planning. We propose a novel deep learning-based approach called topology-guided deformable Mamba (TGDM) for costal cartilage segmentation. The TGDM is tailored to capture the intricate long-range costal cartilage relationships. Our method leverages a deformable model that integrates topological priors to enhance the adaptability and accuracy of the segmentation process. Furthermore, we developed a comprehensive benchmark that contains 165 cases for costal cartilage segmentation. This benchmark sets a new standard for evaluating costal cartilage segmentation techniques and provides a valuable resource for future research. Extensive experiments conducted on both in-domain benchmarks and out-of domain test sets demonstrate the superiority of our approach over existing methods, showing significant improvements in segmentation precision and robustness.
Representational dissimilarity metric spaces for stochastic neural networks
Nov 21, 2022Quantifying similarity between neural representations -- e.g. hidden layer activation vectors -- is a perennial problem in deep learning and neuroscience research. Existing methods compare deterministic responses (e.g. artificial networks that lack stochastic layers) or averaged responses (e.g., trial-averaged firing rates in biological data). However, these measures of deterministic representational similarity ignore the scale and geometric structure of noise, both of which play important roles in neural computation. To rectify this, we generalize previously proposed shape metrics (Williams et al. 2021) to quantify differences in stochastic representations. These new distances satisfy the triangle inequality, and thus can be used as a rigorous basis for many supervised and unsupervised analyses. Leveraging this novel framework, we find that the stochastic geometries of neurobiological representations of oriented visual gratings and naturalistic scenes respectively resemble untrained and trained deep network representations. Further, we are able to more accurately predict certain network attributes (e.g. training hyperparameters) from its position in stochastic (versus deterministic) shape space.
Training Stronger Baselines for Learning to Optimize
Oct 18, 2020
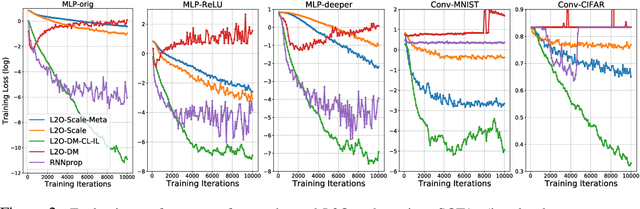
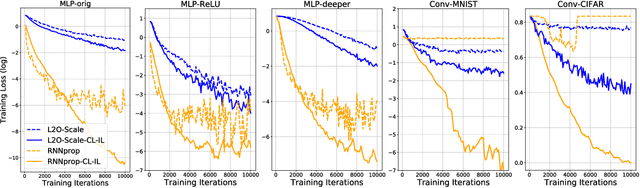
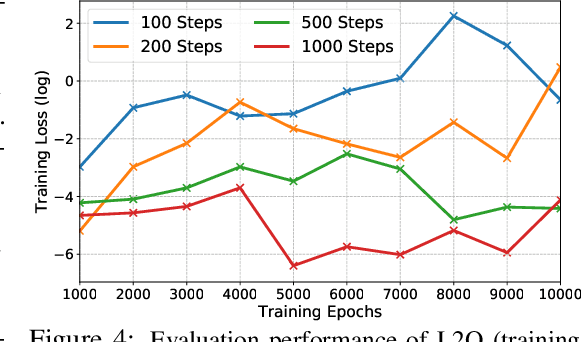
Learning to optimize (L2O) has gained increasing attention since classical optimizers require laborious problem-specific design and hyperparameter tuning. However, there is a gap between the practical demand and the achievable performance of existing L2O models. Specifically, those learned optimizers are applicable to only a limited class of problems, and often exhibit instability. With many efforts devoted to designing more sophisticated L2O models, we argue for another orthogonal, under-explored theme: the training techniques for those L2O models. We show that even the simplest L2O model could have been trained much better. We first present a progressive training scheme to gradually increase the optimizer unroll length, to mitigate a well-known L2O dilemma of truncation bias (shorter unrolling) versus gradient explosion (longer unrolling). We further leverage off-policy imitation learning to guide the L2O learning, by taking reference to the behavior of analytical optimizers. Our improved training techniques are plugged into a variety of state-of-the-art L2O models, and immediately boost their performance, without making any change to their model structures. Especially, by our proposed techniques, an earliest and simplest L2O model can be trained to outperform the latest complicated L2O models on a number of tasks. Our results demonstrate a greater potential of L2O yet to be unleashed, and urge to rethink the recent progress. Our codes are publicly available at: https://github.com/VITA-Group/L2O-Training-Techniques.
Can 3D Adversarial Logos Cloak Humans?
Jun 25, 2020



With the trend of adversarial attacks, researchers attempt to fool trained object detectors in 2D scenes. Among many of them, an intriguing new form of attack with potential real-world usage is to append adversarial patches (e.g. logos) to images. Nevertheless, much less have we known about adversarial attacks from 3D rendering views, which is essential for the attack to be persistently strong in the physical world. This paper presents a new 3D adversarial logo attack: we construct an arbitrary shape logo from a 2D texture image and map this image into a 3D adversarial logo via a texture mapping called logo transformation. The resulting 3D adversarial logo is then viewed as an adversarial texture enabling easy manipulation of its shape and position. This greatly extends the versatility of adversarial training for computer graphics synthesized imagery. Contrary to the traditional adversarial patch, this new form of attack is mapped into the 3D object world and back-propagates to the 2D image domain through differentiable rendering. In addition, and unlike existing adversarial patches, our new 3D adversarial logo is shown to fool state-of-the-art deep object detectors robustly under model rotations, leading to one step further for realistic attacks in the physical world. Our codes are available at https://github.com/TAMU-VITA/3D_Adversarial_Logo.