 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive whitening with fast gain modulation and slow synaptic plasticity
Aug 25, 2023Neurons in early sensory areas rapidly adapt to changing sensory statistics, both by normalizing the variance of their individual responses and by reducing correlations between their responses. Together, these transformations may be viewed as an adaptive form of statistical whitening. Existing mechanistic models of adaptive whitening exclusively use either synaptic plasticity or gain modulation as the biological substrate for adaptation; however, on their own, each of these models has significant limitations. In this work, we unify these approaches in a normative multi-timescale mechanistic model that adaptively whitens its responses with complementary computational roles for synaptic plasticity and gain modulation. Gains are modified on a fast timescale to adapt to the current statistical context, whereas synapses are modified on a slow timescale to learn structural properties of the input statistics that are invariant across contexts. Our model is derived from a novel multi-timescale whitening objective that factorizes the inverse whitening matrix into basis vectors, which correspond to synaptic weights, and a diagonal matrix, which corresponds to neuronal gains. We test our model on synthetic and natural datasets and find that the synapses learn optimal configurations over long timescales that enable the circuit to adaptively whiten neural responses on short timescales exclusively using gain modulation.
Statistical whitening of neural populations with gain-modulating interneurons
Jan 27, 2023Statistical whitening transformations play a fundamental role in many computational systems, and may also play an important role in biological sensory systems. Individual neurons appear to rapidly and reversibly alter their input-output gains, approximately normalizing the variance of their responses. Populations of neurons appear to regulate their joint responses, reducing correlations between neural activities. It is natural to see whitening as the objective that guides these behaviors, but the mechanism for such joint changes is unknown, and direct adjustment of synaptic interactions would seem to be both too slow, and insufficiently reversible. Motivated by the extensive neuroscience literature on rapid gain modulation, we propose a recurrent network architecture in which joint whitening is achieved through modulation of gains within the circuit. Specifically, we derive an online statistical whitening algorithm that regulates the joint second-order statistics of a multi-dimensional input by adjusting the marginal variances of an overcomplete set of interneuron projections. The gains of these interneurons are adjusted individually, using only local signals, and feed back onto the primary neurons. The network converges to a state in which the responses of the primary neurons are whitened. We demonstrate through simulations that the behavior of the network is robust to poor conditioning or noise when the gains are sign-constrained, and can be generalized to achieve a form of local whitening in convolutional populations, such as those found throughout the visual or auditory system.
Representational dissimilarity metric spaces for stochastic neural networks
Nov 21, 2022Quantifying similarity between neural representations -- e.g. hidden layer activation vectors -- is a perennial problem in deep learning and neuroscience research. Existing methods compare deterministic responses (e.g. artificial networks that lack stochastic layers) or averaged responses (e.g., trial-averaged firing rates in biological data). However, these measures of deterministic representational similarity ignore the scale and geometric structure of noise, both of which play important roles in neural computation. To rectify this, we generalize previously proposed shape metrics (Williams et al. 2021) to quantify differences in stochastic representations. These new distances satisfy the triangle inequality, and thus can be used as a rigorous basis for many supervised and unsupervised analyses. Leveraging this novel framework, we find that the stochastic geometries of neurobiological representations of oriented visual gratings and naturalistic scenes respectively resemble untrained and trained deep network representations. Further, we are able to more accurately predict certain network attributes (e.g. training hyperparameters) from its position in stochastic (versus deterministic) shape space.
Multi-rate adaptive transform coding for video compression
Oct 25, 2022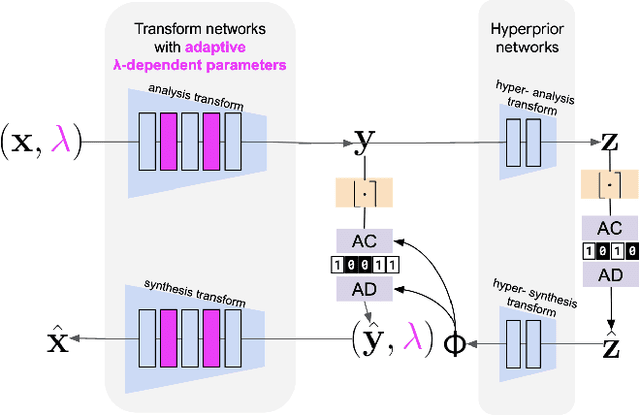
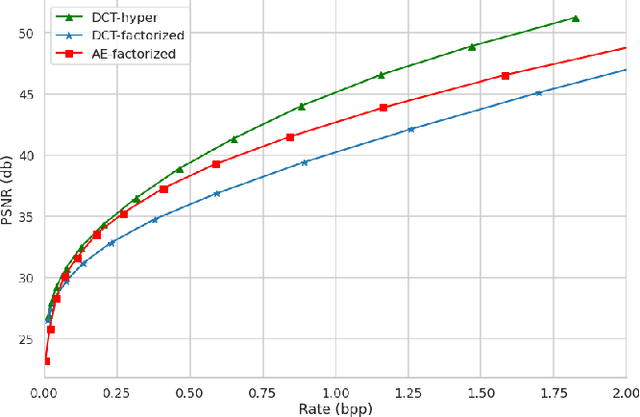
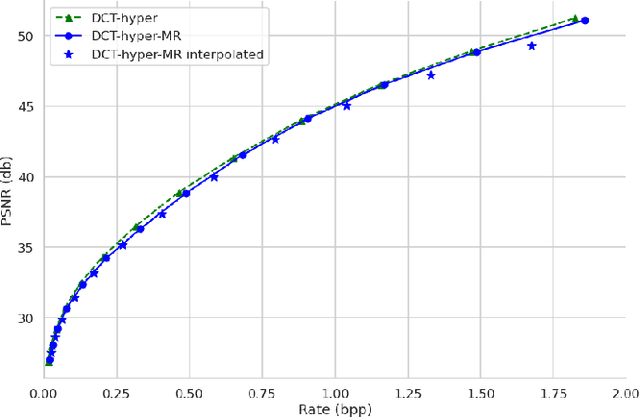
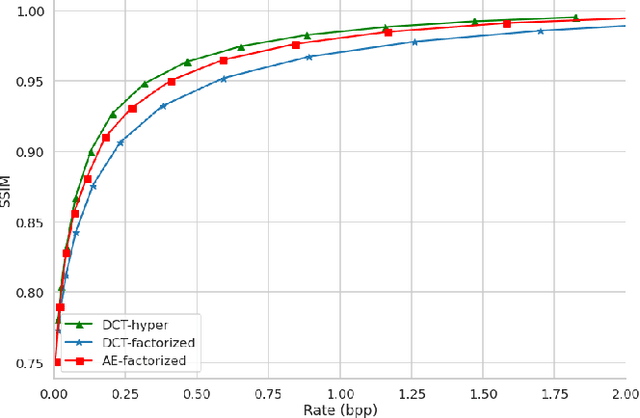
Contemporary lossy image and video coding standards rely on transform coding, the process through which pixels are mapped to an alternative representation to facilitate efficient data compression. Despite impressive performance of end-to-end optimized compression with deep neural networks, the high computational and space demands of these models has prevented them from superseding the relatively simple transform coding found in conventional video codecs. In this study, we propose learned transforms and entropy coding that may either serve as (non)linear drop-in replacements, or enhancements for linear transforms in existing codecs. These transforms can be multi-rate, allowing a single model to operate along the entire rate-distortion curve. To demonstrate the utility of our framework, we augmented the DCT with learned quantization matrices and adaptive entropy coding to compress intra-frame AV1 block prediction residuals. We report substantial BD-rate and perceptual quality improvements over more complex nonlinear transforms at a fraction of the computational cost.