 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI autonomously build, operate, and use the entire data stack?
Dec 08, 2025Enterprise data management is a monumental task. It spans data architecture and systems, integration, quality, governance, and continuous improvement. While AI assistants can help specific persona, such as data engineers and stewards, to navigate and configure the data stack, they fall far short of full automation. However, as AI becomes increasingly capable of tackling tasks that have previously resisted automation due to inherent complexities, we believe there is an imminent opportunity to target fully autonomous data estates. Currently, AI is used in different parts of the data stack, but in this paper, we argue for a paradigm shift from the use of AI in independent data component operations towards a more holistic and autonomous handling of the entire data lifecycle. Towards that end, we explore how each stage of the modern data stack can be autonomously managed by intelligent agents to build self-sufficient systems that can be used not only by human end-users, but also by AI itself. We begin by describing the mounting forces and opportunities that demand this paradigm shift, examine how agents can streamline the data lifecycle, and highlight open questions and areas where additional research is needed. We hope this work will inspire lively debate, stimulate further research, motivate collaborative approaches, and facilitate a more autonomous future for data systems.
Queried Unlabeled Data Improves and Robustifies Class-Incremental Learning
Jun 17, 2022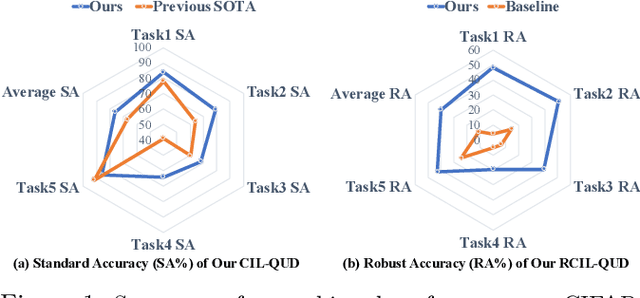
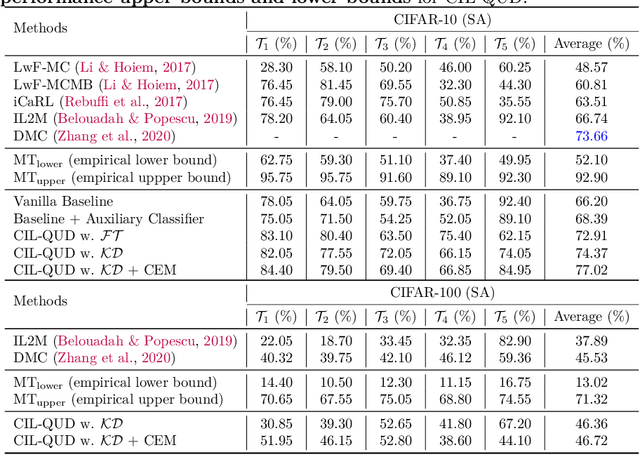
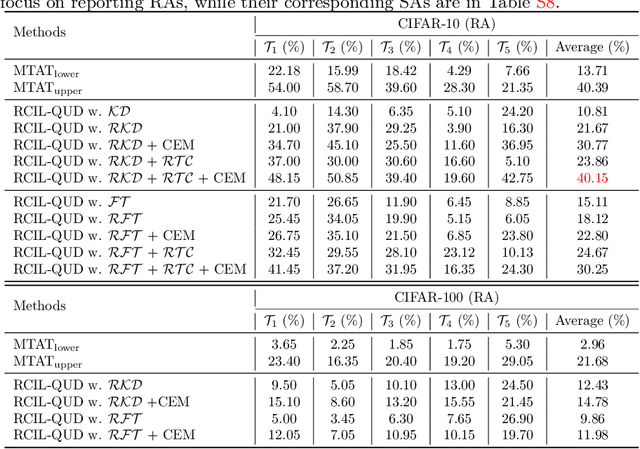
Class-incremental learning (CIL) suffers from the notorious dilemma between learning newly added classes and preserving previously learned class knowledge. That catastrophic forgetting issue could be mitigated by storing historical data for replay, which yet would cause memory overheads as well as imbalanced prediction updates. To address this dilemma, we propose to leverage "free" external unlabeled data querying in continual learning. We first present a CIL with Queried Unlabeled Data (CIL-QUD) scheme, where we only store a handful of past training samples as anchors and use them to query relevant unlabeled examples each time. Along with new and past stored data, the queried unlabeled are effectively utilized, through learning-without-forgetting (LwF) regularizers and class-balance training. Besides preserving model generalization over past and current tasks, we next study the problem of adversarial robustness for CIL-QUD. Inspired by the recent success of learning robust models with unlabeled data, we explore a new robustness-aware CIL setting, where the learned adversarial robustness has to resist forgetting and be transferred as new tasks come in continually. While existing options easily fail, we show queried unlabeled data can continue to benefit, and seamlessly extend CIL-QUD into its robustified versions, RCIL-QUD. Extensive experiments demonstrate that CIL-QUD achieves substantial accuracy gains on CIFAR-10 and CIFAR-100, compared to previous state-of-the-art CIL approaches. Moreover, RCIL-QUD establishes the first strong milestone for robustness-aware CIL. Codes are available in https://github.com/VITA-Group/CIL-QUD.
Optimizer Amalgamation
Mar 15, 2022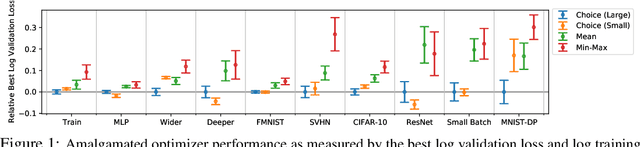
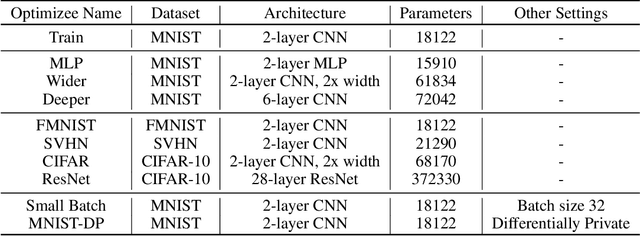
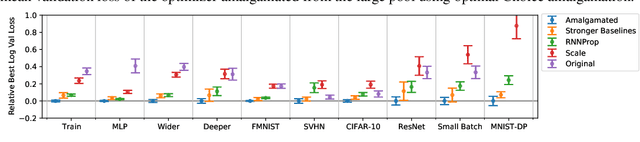
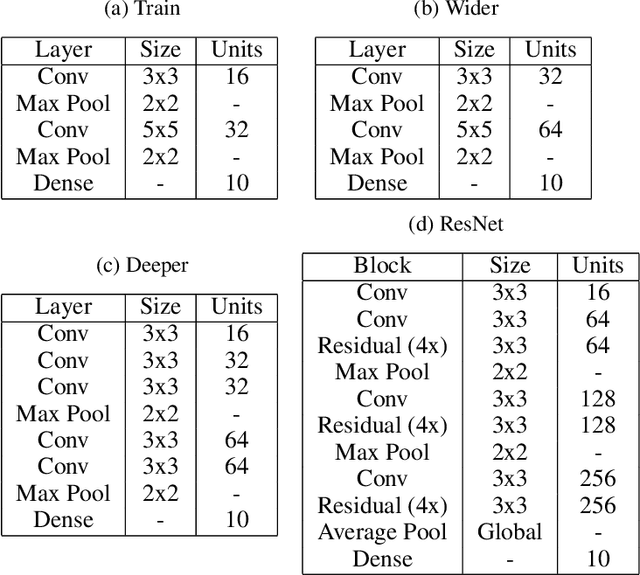
Selecting an appropriate optimizer for a given problem is of major interest for researchers and practitioners. Many analytical optimizers have been proposed using a variety of theoretical and empirical approaches; however, none can offer a universal advantage over other competitive optimizers. We are thus motivated to study a new problem named Optimizer Amalgamation: how can we best combine a pool of "teacher" optimizers into a single "student" optimizer that can have stronger problem-specific performance? In this paper, we draw inspiration from the field of "learning to optimize" to use a learnable amalgamation target. First, we define three differentiable amalgamation mechanisms to amalgamate a pool of analytical optimizers by gradient descent. Then, in order to reduce variance of the amalgamation process, we also explore methods to stabilize the amalgamation process by perturbing the amalgamation target. Finally, we present experiments showing the superiority of our amalgamated optimizer compared to its amalgamated components and learning to optimize baselines, and the efficacy of our variance reducing perturbations. Our code and pre-trained models are publicly available at http://github.com/VITA-Group/OptimizerAmalgamation.
How Much Automation Does a Data Scientist Want?
Jan 07, 2021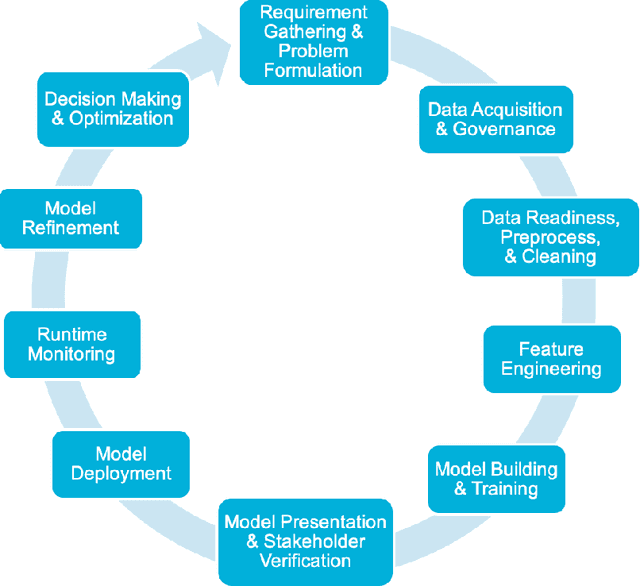
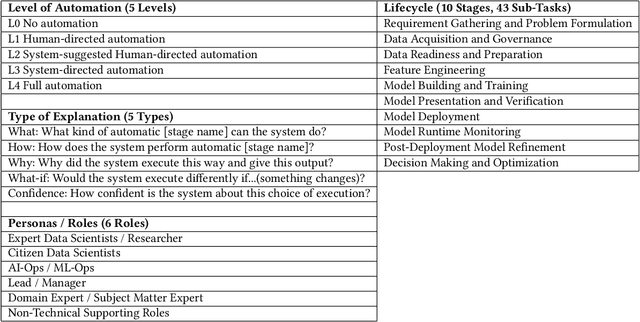
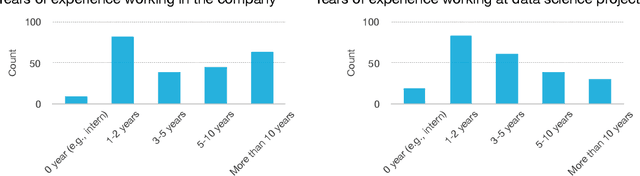
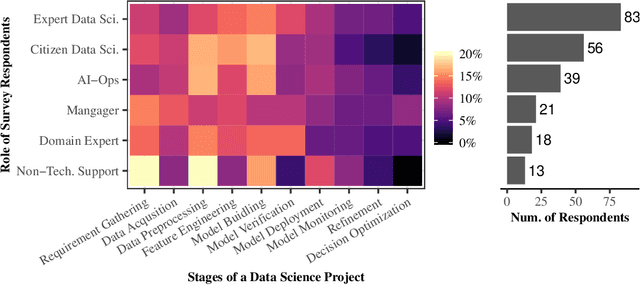
Data science and machine learning (DS/ML) are at the heart of the recent advancements of many Artificial Intelligence (AI) applications. There is an active research thread in AI, \autoai, that aims to develop systems for automating end-to-end the DS/ML Lifecycle. However, do DS and ML workers really want to automate their DS/ML workflow? To answer this question, we first synthesize a human-centered AutoML framework with 6 User Role/Personas, 10 Stages and 43 Sub-Tasks, 5 Levels of Automation, and 5 Types of Explanation, through reviewing research literature and marketing reports. Secondly, we use the framework to guide the design of an online survey study with 217 DS/ML workers who had varying degrees of experience, and different user roles "matching" to our 6 roles/personas. We found that different user personas participated in distinct stages of the lifecycle -- but not all stages. Their desired levels of automation and types of explanation for AutoML also varied significantly depending on the DS/ML stage and the user persona. Based on the survey results, we argue there is no rationale from user needs for complete automation of the end-to-end DS/ML lifecycle. We propose new next steps for user-controlled DS/ML automation.
Training Stronger Baselines for Learning to Optimize
Oct 18, 2020
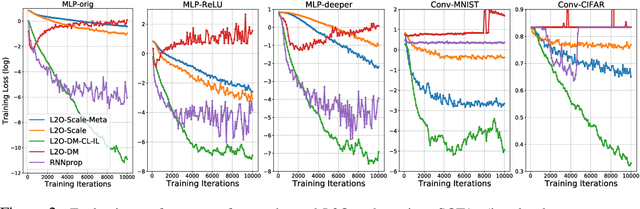
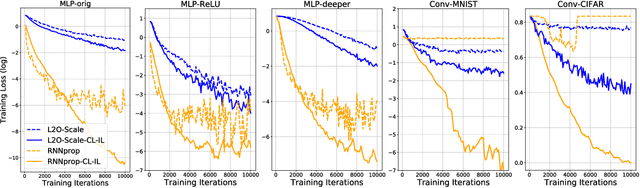
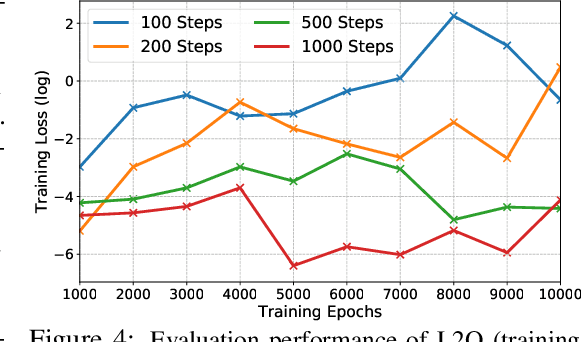
Learning to optimize (L2O) has gained increasing attention since classical optimizers require laborious problem-specific design and hyperparameter tuning. However, there is a gap between the practical demand and the achievable performance of existing L2O models. Specifically, those learned optimizers are applicable to only a limited class of problems, and often exhibit instability. With many efforts devoted to designing more sophisticated L2O models, we argue for another orthogonal, under-explored theme: the training techniques for those L2O models. We show that even the simplest L2O model could have been trained much better. We first present a progressive training scheme to gradually increase the optimizer unroll length, to mitigate a well-known L2O dilemma of truncation bias (shorter unrolling) versus gradient explosion (longer unrolling). We further leverage off-policy imitation learning to guide the L2O learning, by taking reference to the behavior of analytical optimizers. Our improved training techniques are plugged into a variety of state-of-the-art L2O models, and immediately boost their performance, without making any change to their model structures. Especially, by our proposed techniques, an earliest and simplest L2O model can be trained to outperform the latest complicated L2O models on a number of tasks. Our results demonstrate a greater potential of L2O yet to be unleashed, and urge to rethink the recent progress. Our codes are publicly available at: https://github.com/VITA-Group/L2O-Training-Techniques.
Adversarial Robustness: From Self-Supervised Pre-Training to Fine-Tuning
Mar 28, 2020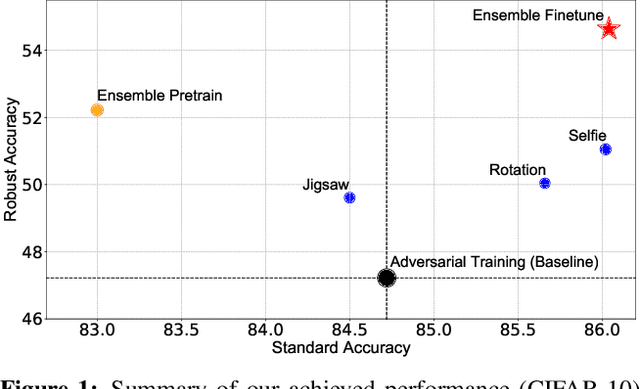


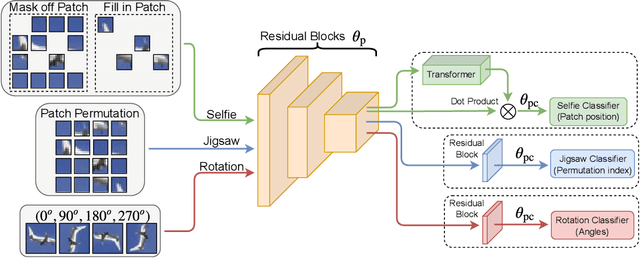
Pretrained models from self-supervision are prevalently used in fine-tuning downstream tasks faster or for better accuracy. However, gaining robustness from pretraining is left unexplored. We introduce adversarial training into self-supervision, to provide general-purpose robust pre-trained models for the first time. We find these robust pre-trained models can benefit the subsequent fine-tuning in two ways: i) boosting final model robustness; ii) saving the computation cost, if proceeding towards adversarial fine-tuning. We conduct extensive experiments to demonstrate that the proposed framework achieves large performance margins (eg, 3.83% on robust accuracy and 1.3% on standard accuracy, on the CIFAR-10 dataset), compared with the conventional end-to-end adversarial training baseline. Moreover, we find that different self-supervised pre-trained models have a diverse adversarial vulnerability. It inspires us to ensemble several pretraining tasks, which boosts robustness more. Our ensemble strategy contributes to a further improvement of 3.59% on robust accuracy, while maintaining a slightly higher standard accuracy on CIFAR-10. Our codes are available at https://github.com/TAMU-VITA/Adv-SS-Pretraining.
Zeroth-Order Stochastic Variance Reduction for Nonconvex Optimization
Jun 07, 2018
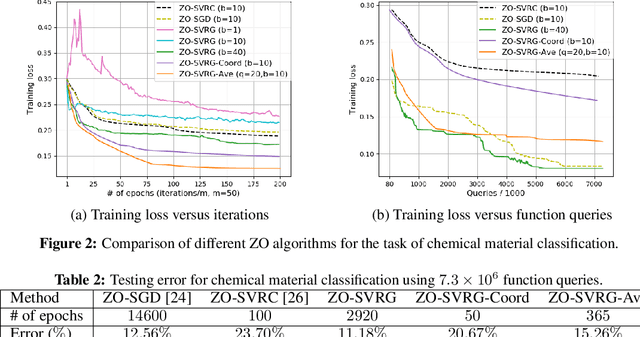
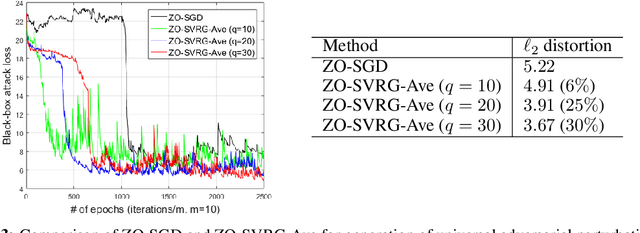
As application demands for zeroth-order (gradient-free) optimization accelerate, the need for variance reduced and faster converging approaches is also intensifying. This paper addresses these challenges by presenting: a) a comprehensive theoretical analysis of variance reduced zeroth-order (ZO) optimization, b) a novel variance reduced ZO algorithm, called ZO-SVRG, and c) an experimental evaluation of our approach in the context of two compelling applications, black-box chemical material classification and generation of adversarial examples from black-box deep neural network models. Our theoretical analysis uncovers an essential difficulty in the analysis of ZO-SVRG: the unbiased assumption on gradient estimates no longer holds. We prove that compared to its first-order counterpart, ZO-SVRG with a two-point random gradient estimator could suffer an additional error of order $O(1/b)$, where $b$ is the mini-batch size. To mitigate this error, we propose two accelerated versions of ZO-SVRG utilizing variance reduced gradient estimators, which achieve the best rate known for ZO stochastic optimization (in terms of iterations). Our extensive experimental results show that our approaches outperform other state-of-the-art ZO algorithms, and strike a balance between the convergence rate and the function query complexity.