 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Data Processing using Meta-Agents
Jan 30, 2026Traditional data processing pipelines are typically static and handcrafted for specific tasks, limiting their adaptability to evolving requirements. While general-purpose agents and coding assistants can generate code for well-understood data pipelines, they lack the ability to autonomously monitor, manage, and optimize an end-to-end pipeline once deployed. We present \textbf{Autonomous Data Processing using Meta-agents} (ADP-MA), a framework that dynamically constructs, executes, and iteratively refines data processing pipelines through hierarchical agent orchestration. At its core, \textit{meta-agents} analyze input data and task specifications to design a multi-phase plan, instantiate specialized \textit{ground-level agents}, and continuously evaluate pipeline performance. The architecture comprises three key components: a planning module for strategy generation, an orchestration layer for agent coordination and tool integration, and a monitoring loop for iterative evaluation and backtracking. Unlike conventional approaches, ADP-MA emphasizes context-aware optimization, adaptive workload partitioning, and progressive sampling for scalability. Additionally, the framework leverages a diverse set of external tools and can reuse previously designed agents, reducing redundancy and accelerating pipeline construction. We demonstrate ADP-MA through an interactive demo that showcases pipeline construction, execution monitoring, and adaptive refinement across representative data processing tasks.
A Vision for Semantically Enriched Data Science
Mar 02, 2023The recent efforts in automation of machine learning or data science has achieved success in various tasks such as hyper-parameter optimization or model selection. However, key areas such as utilizing domain knowledge and data semantics are areas where we have seen little automation. Data Scientists have long leveraged common sense reasoning and domain knowledge to understand and enrich data for building predictive models. In this paper we discuss important shortcomings of current data science and machine learning solutions. We then envision how leveraging "semantic" understanding and reasoning on data in combination with novel tools for data science automation can help with consistent and explainable data augmentation and transformation. Additionally, we discuss how semantics can assist data scientists in a new manner by helping with challenges related to trust, bias, and explainability in machine learning. Semantic annotation can also help better explore and organize large data sources.
A Survey on Semantics in Automated Data Science
May 16, 2022
Data Scientists leverage common sense reasoning and domain knowledge to understand and enrich data for building predictive models. In recent years, we have witnessed a surge in tools and techniques for {\em automated machine learning}. While data scientists can employ various such tools to help with model building, many other aspects such as {\em feature engineering} that require semantic understanding of concepts, remain manual to a large extent. In this paper we discuss important shortcomings of current automated data science solutions and machine learning. We discuss how leveraging basic semantic reasoning on data in combination with novel tools for data science automation can help with consistent and explainable data augmentation and transformation. Moreover, semantics can assist data scientists in a new manner by helping with challenges related to {\em trust}, {\em bias}, and {\em explainability}.
How Much Automation Does a Data Scientist Want?
Jan 07, 2021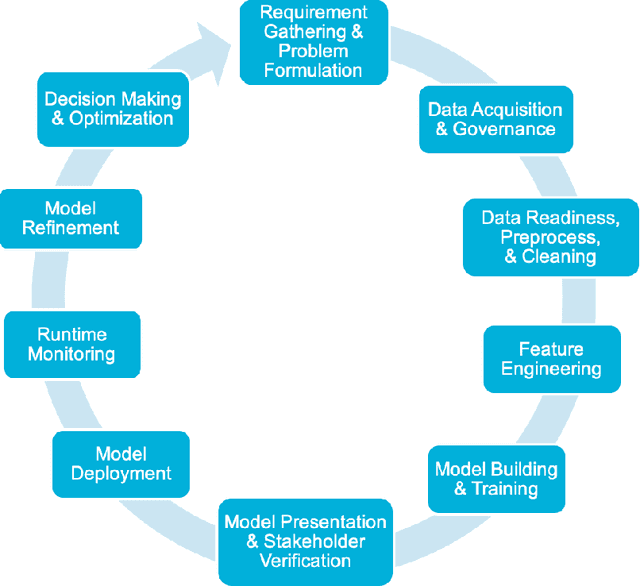
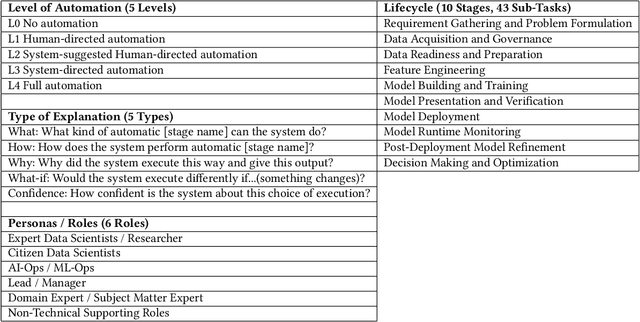
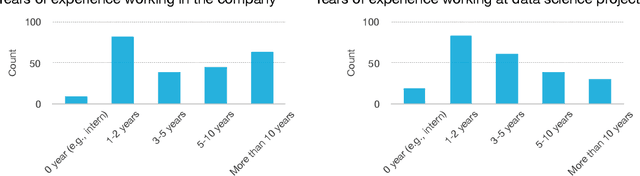
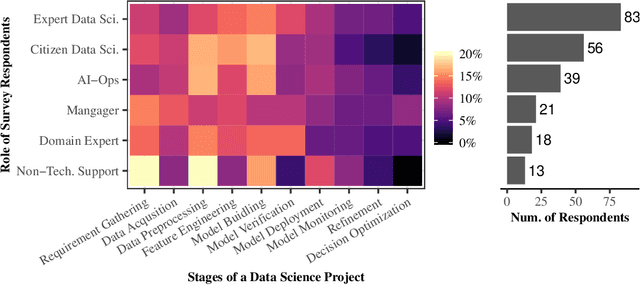
Data science and machine learning (DS/ML) are at the heart of the recent advancements of many Artificial Intelligence (AI) applications. There is an active research thread in AI, \autoai, that aims to develop systems for automating end-to-end the DS/ML Lifecycle. However, do DS and ML workers really want to automate their DS/ML workflow? To answer this question, we first synthesize a human-centered AutoML framework with 6 User Role/Personas, 10 Stages and 43 Sub-Tasks, 5 Levels of Automation, and 5 Types of Explanation, through reviewing research literature and marketing reports. Secondly, we use the framework to guide the design of an online survey study with 217 DS/ML workers who had varying degrees of experience, and different user roles "matching" to our 6 roles/personas. We found that different user personas participated in distinct stages of the lifecycle -- but not all stages. Their desired levels of automation and types of explanation for AutoML also varied significantly depending on the DS/ML stage and the user persona. Based on the survey results, we argue there is no rationale from user needs for complete automation of the end-to-end DS/ML lifecycle. We propose new next steps for user-controlled DS/ML automation.
Semantic Annotation for Tabular Data
Dec 15, 2020



Detecting semantic concept of columns in tabular data is of particular interest to many applications ranging from data integration, cleaning, search to feature engineering and model building in machine learning. Recently, several works have proposed supervised learning-based or heuristic pattern-based approaches to semantic type annotation. Both have shortcomings that prevent them from generalizing over a large number of concepts or examples. Many neural network based methods also present scalability issues. Additionally, none of the known methods works well for numerical data. We propose $C^2$, a column to concept mapper that is based on a maximum likelihood estimation approach through ensembles. It is able to effectively utilize vast amounts of, albeit somewhat noisy, openly available table corpora in addition to two popular knowledge graphs to perform effective and efficient concept prediction for structured data. We demonstrate the effectiveness of $C^2$ over available techniques on 9 datasets, the most comprehensive comparison on this topic so far.
How can AI Automate End-to-End Data Science?
Oct 22, 2019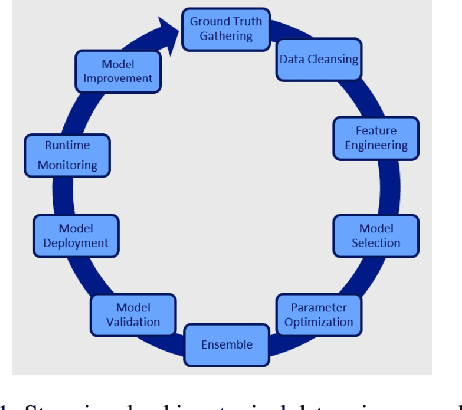
Data science is labor-intensive and human experts are scarce but heavily involved in every aspect of it. This makes data science time consuming and restricted to experts with the resulting quality heavily dependent on their experience and skills. To make data science more accessible and scalable, we need its democratization. Automated Data Science (AutoDS) is aimed towards that goal and is emerging as an important research and business topic. We introduce and define the AutoDS challenge, followed by a proposal of a general AutoDS framework that covers existing approaches but also provides guidance for the development of new methods. We categorize and review the existing literature from multiple aspects of the problem setup and employed techniques. Then we provide several views on how AI could succeed in automating end-to-end AutoDS. We hope this survey can serve as insightful guideline for the AutoDS field and provide inspiration for future research.
Automating Predictive Modeling Process using Reinforcement Learning
Mar 02, 2019

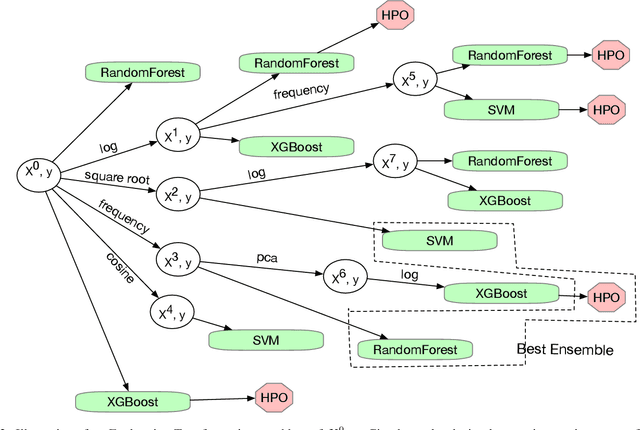

Building a good predictive model requires an array of activities such as data imputation, feature transformations, estimator selection, hyper-parameter search and ensemble construction. Given the large, complex and heterogenous space of options, off-the-shelf optimization methods are infeasible for realistic response times. In practice, much of the predictive modeling process is conducted by experienced data scientists, who selectively make use of available tools. Over time, they develop an understanding of the behavior of operators, and perform serial decision making under uncertainty, colloquially referred to as educated guesswork. With an unprecedented demand for application of supervised machine learning, there is a call for solutions that automatically search for a good combination of parameters across these tasks to minimize the modeling error. We introduce a novel system called APRL (Autonomous Predictive modeler via Reinforcement Learning), that uses past experience through reinforcement learning to optimize such sequential decision making from within a set of diverse actions under a time constraint on a previously unseen predictive learning problem. APRL actions are taken to optimize the performance of a final ensemble. This is in contrast to other systems, which maximize individual model accuracy first and create ensembles as a disconnected post-processing step. As a result, APRL is able to reduce up to 71\% of classification error on average over a wide variety of problems.
Feature Engineering for Predictive Modeling using Reinforcement Learning
Sep 21, 2017


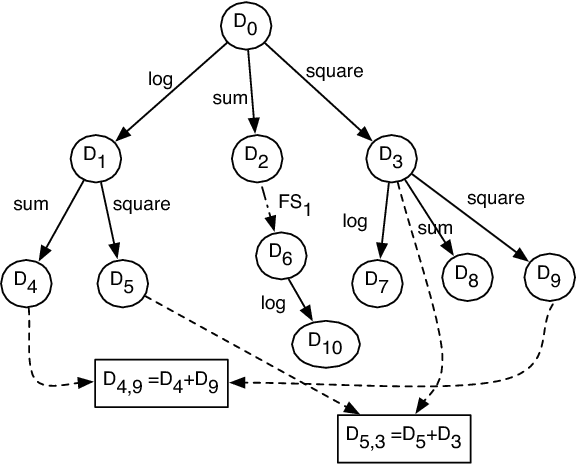
Feature engineering is a crucial step in the process of predictive modeling. It involves the transformation of given feature space, typically using mathematical functions, with the objective of reducing the modeling error for a given target. However, there is no well-defined basis for performing effective feature engineering. It involves domain knowledge, intuition, and most of all, a lengthy process of trial and error. The human attention involved in overseeing this process significantly influences the cost of model generation. We present a new framework to automate feature engineering. It is based on performance driven exploration of a transformation graph, which systematically and compactly enumerates the space of given options. A highly efficient exploration strategy is derived through reinforcement learning on past examples.