 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
Facilitating Knowledge Sharing from Domain Experts to Data Scientists for Building NLP Models
Jan 29, 2021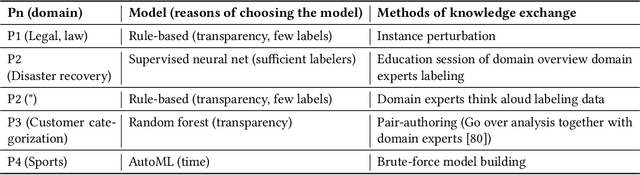

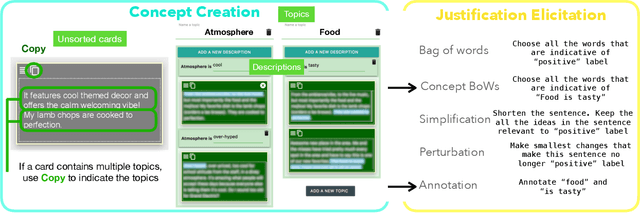
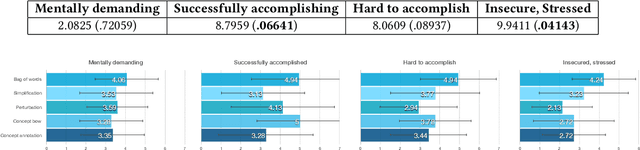
Data scientists face a steep learning curve in understanding a new domain for which they want to build machine learning (ML) models. While input from domain experts could offer valuable help, such input is often limited, expensive, and generally not in a form readily consumable by a model development pipeline. In this paper, we propose Ziva, a framework to guide domain experts in sharing essential domain knowledge to data scientists for building NLP models. With Ziva, experts are able to distill and share their domain knowledge using domain concept extractors and five types of label justification over a representative data sample. The design of Ziva is informed by preliminary interviews with data scientists, in order to understand current practices of domain knowledge acquisition process for ML development projects. To assess our design, we run a mix-method case-study to evaluate how Ziva can facilitate interaction of domain experts and data scientists. Our results highlight that (1) domain experts are able to use Ziva to provide rich domain knowledge, while maintaining low mental load and stress levels; and (2) data scientists find Ziva's output helpful for learning essential information about the domain, offering scalability of information, and lowering the burden on domain experts to share knowledge. We conclude this work by experimenting with building NLP models using the Ziva output by our case study.
How AI Developers Overcome Communication Challenges in a Multidisciplinary Team: A Case Study
Jan 13, 2021
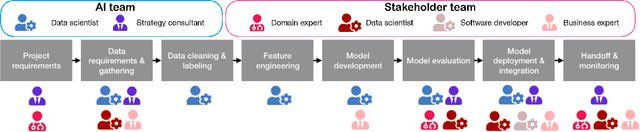
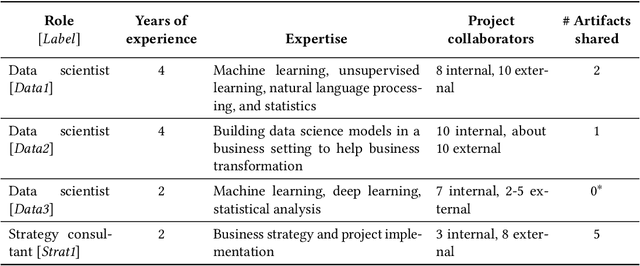
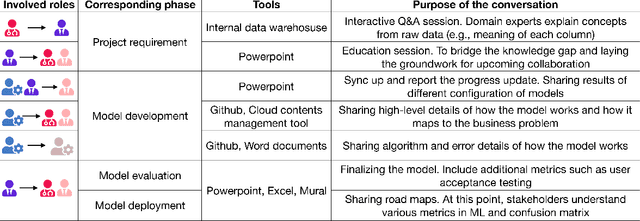
The development of AI applications is a multidisciplinary effort, involving multiple roles collaborating with the AI developers, an umbrella term we use to include data scientists and other AI-adjacent roles on the same team. During these collaborations, there is a knowledge mismatch between AI developers, who are skilled in data science, and external stakeholders who are typically not. This difference leads to communication gaps, and the onus falls on AI developers to explain data science concepts to their collaborators. In this paper, we report on a study including analyses of both interviews with AI developers and artifacts they produced for communication. Using the analytic lens of shared mental models, we report on the types of communication gaps that AI developers face, how AI developers communicate across disciplinary and organizational boundaries, and how they simultaneously manage issues regarding trust and expectations.
How Much Automation Does a Data Scientist Want?
Jan 07, 2021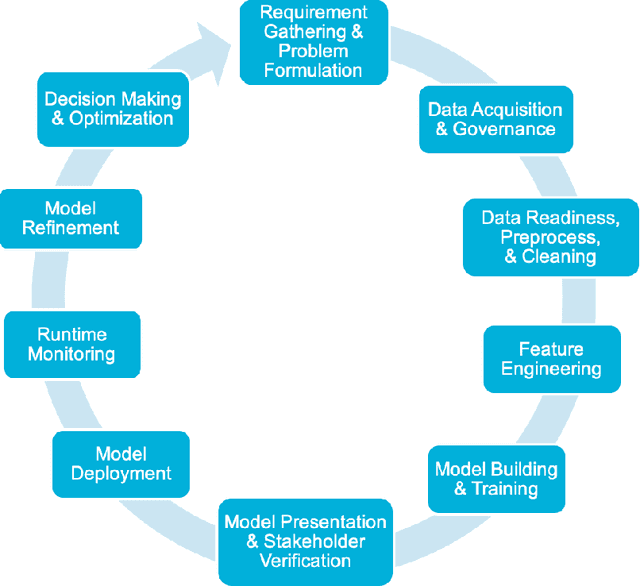
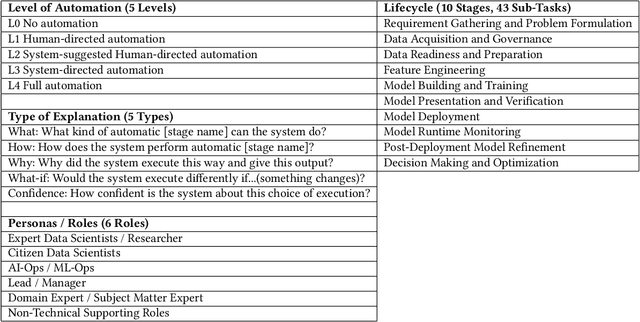
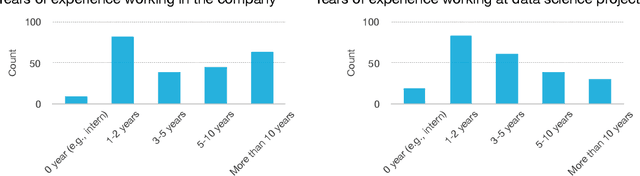
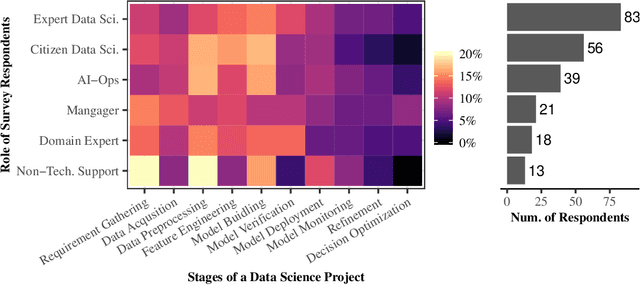
Data science and machine learning (DS/ML) are at the heart of the recent advancements of many Artificial Intelligence (AI) applications. There is an active research thread in AI, \autoai, that aims to develop systems for automating end-to-end the DS/ML Lifecycle. However, do DS and ML workers really want to automate their DS/ML workflow? To answer this question, we first synthesize a human-centered AutoML framework with 6 User Role/Personas, 10 Stages and 43 Sub-Tasks, 5 Levels of Automation, and 5 Types of Explanation, through reviewing research literature and marketing reports. Secondly, we use the framework to guide the design of an online survey study with 217 DS/ML workers who had varying degrees of experience, and different user roles "matching" to our 6 roles/personas. We found that different user personas participated in distinct stages of the lifecycle -- but not all stages. Their desired levels of automation and types of explanation for AutoML also varied significantly depending on the DS/ML stage and the user persona. Based on the survey results, we argue there is no rationale from user needs for complete automation of the end-to-end DS/ML lifecycle. We propose new next steps for user-controlled DS/ML automation.