 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Library of LLM Intrinsics for Retrieval-Augmented Generation
Apr 16, 2025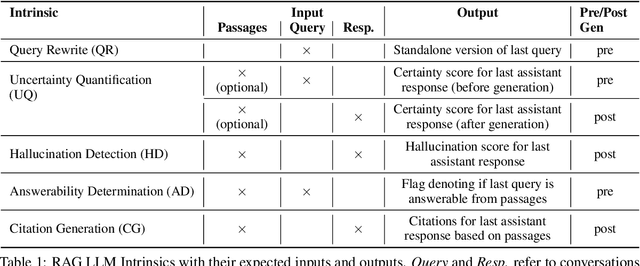
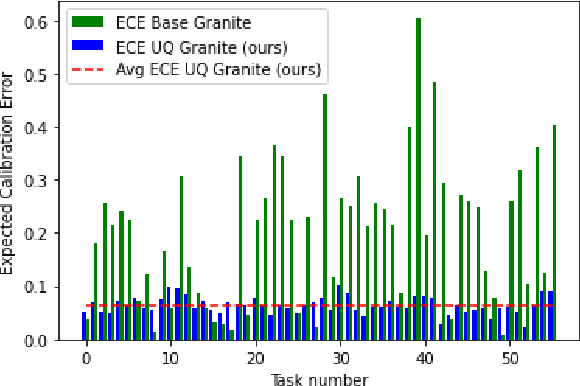

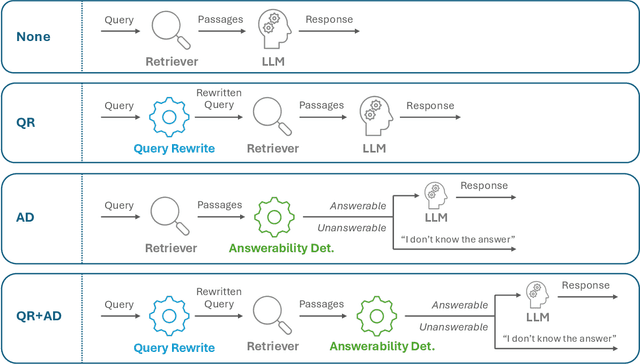
In the developer community for large language models (LLMs), there is not yet a clean pattern analogous to a software library, to support very large scale collaboration. Even for the commonplace use case of Retrieval-Augmented Generation (RAG), it is not currently possible to write a RAG application against a well-defined set of APIs that are agreed upon by different LLM providers. Inspired by the idea of compiler intrinsics, we propose some elements of such a concept through introducing a library of LLM Intrinsics for RAG. An LLM intrinsic is defined as a capability that can be invoked through a well-defined API that is reasonably stable and independent of how the LLM intrinsic itself is implemented. The intrinsics in our library are released as LoRA adapters on HuggingFace, and through a software interface with clear structured input/output characteristics on top of vLLM as an inference platform, accompanied in both places with documentation and code. This article describes the intended usage, training details, and evaluations for each intrinsic, as well as compositions of multiple intrinsics.
MTRAG: A Multi-Turn Conversational Benchmark for Evaluating Retrieval-Augmented Generation Systems
Jan 07, 2025



Retrieval-augmented generation (RAG) has recently become a very popular task for Large Language Models (LLMs). Evaluating them on multi-turn RAG conversations, where the system is asked to generate a response to a question in the context of a preceding conversation is an important and often overlooked task with several additional challenges. We present MTRAG: an end-to-end human-generated multi-turn RAG benchmark that reflects several real-world properties across diverse dimensions for evaluating the full RAG pipeline. MTRAG contains 110 conversations averaging 7.7 turns each across four domains for a total of 842 tasks. We also explore automation paths via synthetic data and LLM-as-a-Judge evaluation. Our human and automatic evaluations show that even state-of-the-art LLM RAG systems struggle on MTRAG. We demonstrate the need for strong retrieval and generation systems that can handle later turns, unanswerable questions, non-standalone questions, and multiple domains. MTRAG is available at https://github.com/ibm/mt-rag-benchmark.
Evaluating Robustness of Dialogue Summarization Models in the Presence of Naturally Occurring Variations
Nov 15, 2023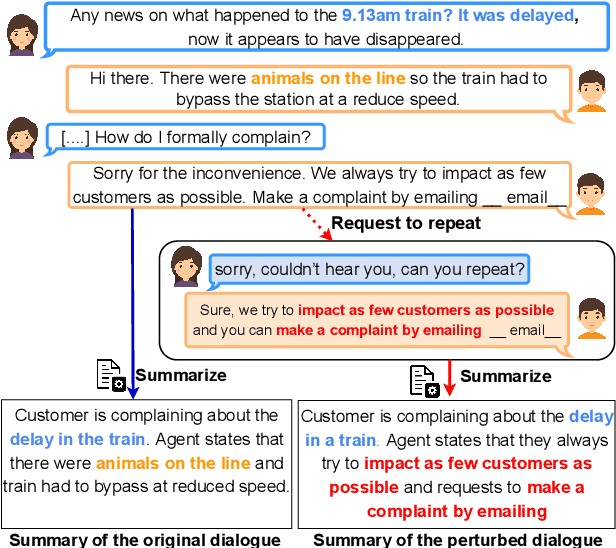
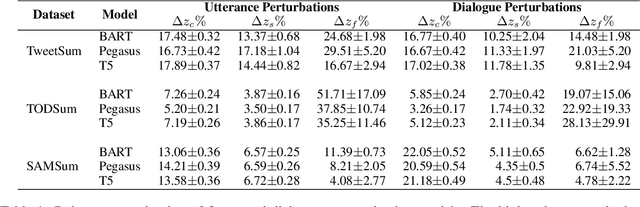
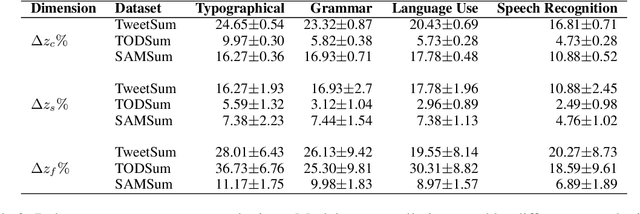
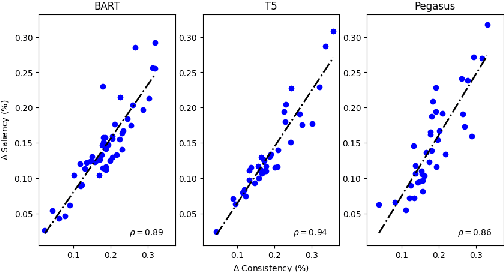
Dialogue summarization task involves summarizing long conversations while preserving the most salient information. Real-life dialogues often involve naturally occurring variations (e.g., repetitions, hesitations) and existing dialogue summarization models suffer from performance drop on such conversations. In this study, we systematically investigate the impact of such variations on state-of-the-art dialogue summarization models using publicly available datasets. To simulate real-life variations, we introduce two types of perturbations: utterance-level perturbations that modify individual utterances with errors and language variations, and dialogue-level perturbations that add non-informative exchanges (e.g., repetitions, greetings). We conduct our analysis along three dimensions of robustness: consistency, saliency, and faithfulness, which capture different aspects of the summarization model's performance. We find that both fine-tuned and instruction-tuned models are affected by input variations, with the latter being more susceptible, particularly to dialogue-level perturbations. We also validate our findings via human evaluation. Finally, we investigate if the robustness of fine-tuned models can be improved by training them with a fraction of perturbed data and observe that this approach is insufficient to address robustness challenges with current models and thus warrants a more thorough investigation to identify better solutions. Overall, our work highlights robustness challenges in dialogue summarization and provides insights for future research.
How Can Context Help? Exploring Joint Retrieval of Passage and Personalized Context
Aug 26, 2023



The integration of external personalized context information into document-grounded conversational systems has significant potential business value, but has not been well-studied. Motivated by the concept of personalized context-aware document-grounded conversational systems, we introduce the task of context-aware passage retrieval. We also construct a dataset specifically curated for this purpose. We describe multiple baseline systems to address this task, and propose a novel approach, Personalized Context-Aware Search (PCAS), that effectively harnesses contextual information during passage retrieval. Experimental evaluations conducted on multiple popular dense retrieval systems demonstrate that our proposed approach not only outperforms the baselines in retrieving the most relevant passage but also excels at identifying the pertinent context among all the available contexts. We envision that our contributions will serve as a catalyst for inspiring future research endeavors in this promising direction.
Semi-Structured Object Sequence Encoders
Jan 10, 2023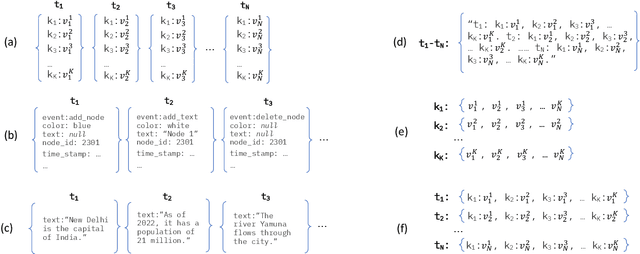

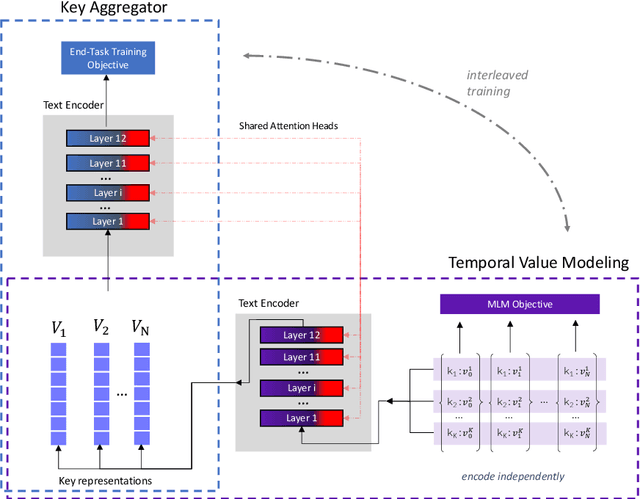
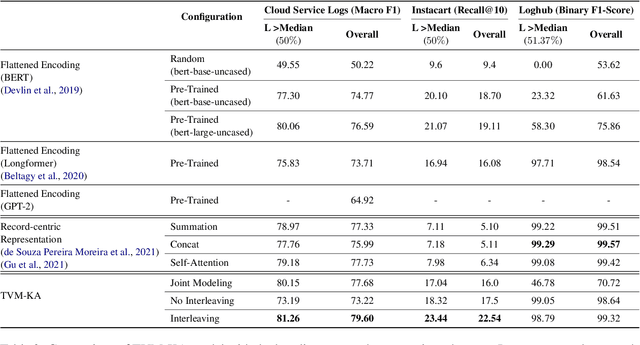
In this paper we explore the task of modeling (semi) structured object sequences; in particular we focus our attention on the problem of developing a structure-aware input representation for such sequences. In such sequences, we assume that each structured object is represented by a set of key-value pairs which encode the attributes of the structured object. Given a universe of keys, a sequence of structured objects can then be viewed as an evolution of the values for each key, over time. We encode and construct a sequential representation using the values for a particular key (Temporal Value Modeling - TVM) and then self-attend over the set of key-conditioned value sequences to a create a representation of the structured object sequence (Key Aggregation - KA). We pre-train and fine-tune the two components independently and present an innovative training schedule that interleaves the training of both modules with shared attention heads. We find that this iterative two part-training results in better performance than a unified network with hierarchical encoding as well as over, other methods that use a {\em record-view} representation of the sequence \cite{de2021transformers4rec} or a simple {\em flattened} representation of the sequence. We conduct experiments using real-world data to demonstrate the advantage of interleaving TVM-KA on multiple tasks and detailed ablation studies motivating our modeling choices. We find that our approach performs better than flattening sequence objects and also allows us to operate on significantly larger sequences than existing methods.
PriMeSRL-Eval: A Practical Quality Metric for Semantic Role Labeling Systems Evaluation
Oct 12, 2022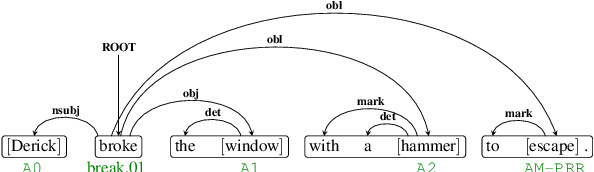
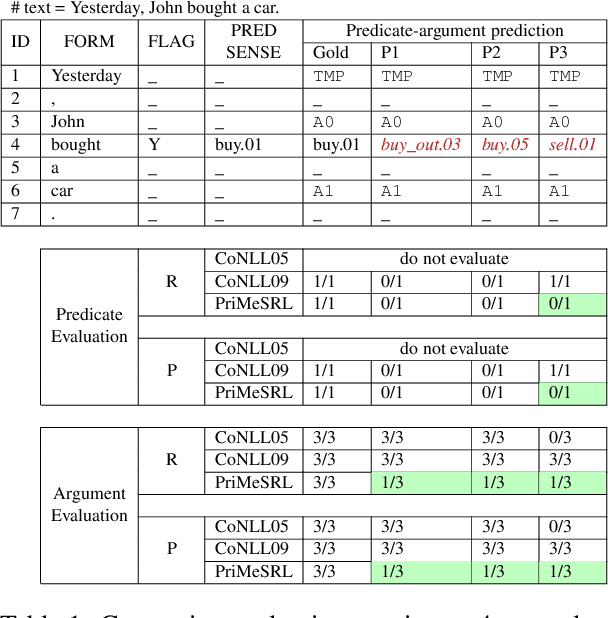
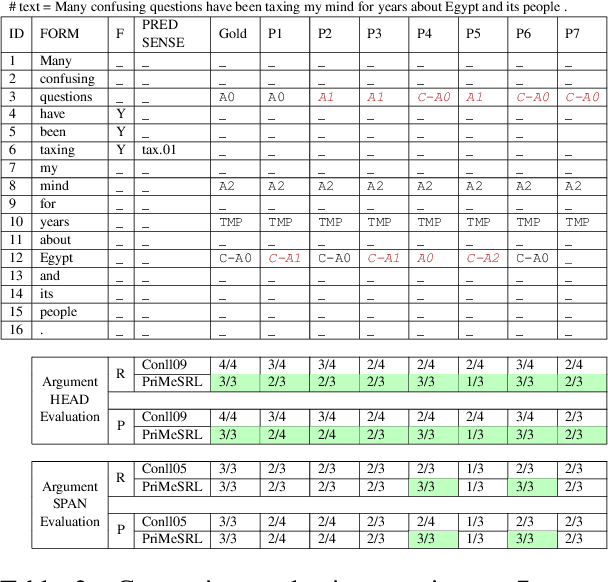
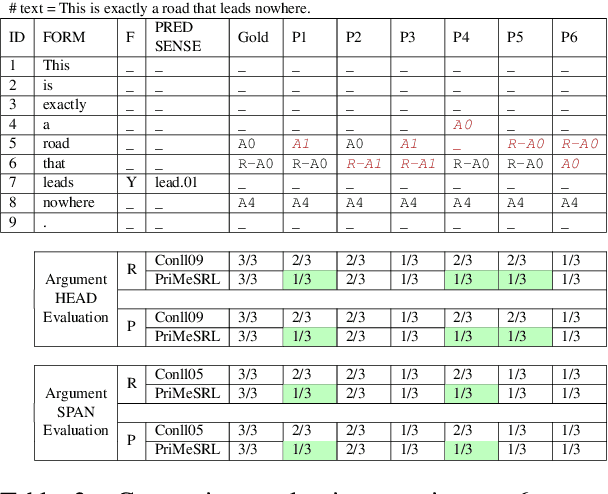
Semantic role labeling (SRL) identifies the predicate-argument structure in a sentence. This task is usually accomplished in four steps: predicate identification, predicate sense disambiguation, argument identification, and argument classification. Errors introduced at one step propagate to later steps. Unfortunately, the existing SRL evaluation scripts do not consider the full effect of this error propagation aspect. They either evaluate arguments independent of predicate sense (CoNLL09) or do not evaluate predicate sense at all (CoNLL05), yielding an inaccurate SRL model performance on the argument classification task. In this paper, we address key practical issues with existing evaluation scripts and propose a more strict SRL evaluation metric PriMeSRL. We observe that by employing PriMeSRL, the quality evaluation of all SoTA SRL models drops significantly, and their relative rankings also change. We also show that PriMeSRLsuccessfully penalizes actual failures in SoTA SRL models.
Label Sleuth: From Unlabeled Text to a Classifier in a Few Hours
Aug 02, 2022



Text classification can be useful in many real-world scenarios, saving a lot of time for end users. However, building a custom classifier typically requires coding skills and ML knowledge, which poses a significant barrier for many potential users. To lift this barrier, we introduce Label Sleuth, a free open source system for labeling and creating text classifiers. This system is unique for (a) being a no-code system, making NLP accessible to non-experts, (b) guiding users through the entire labeling process until they obtain a custom classifier, making the process efficient -- from cold start to classifier in a few hours, and (c) being open for configuration and extension by developers. By open sourcing Label Sleuth we hope to build a community of users and developers that will broaden the utilization of NLP models.
Learning to Robustly Aggregate Labeling Functions for Semi-supervised Data Programming
Sep 23, 2021
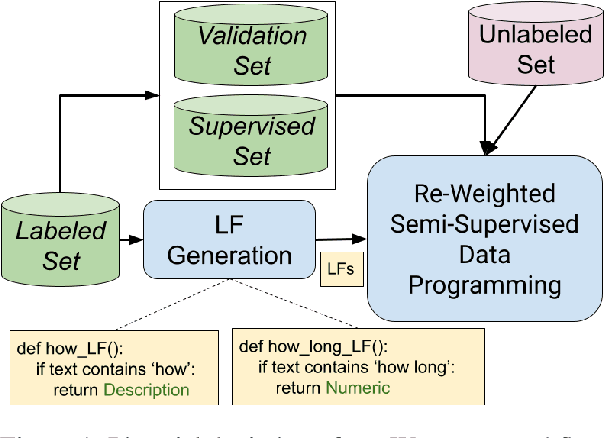
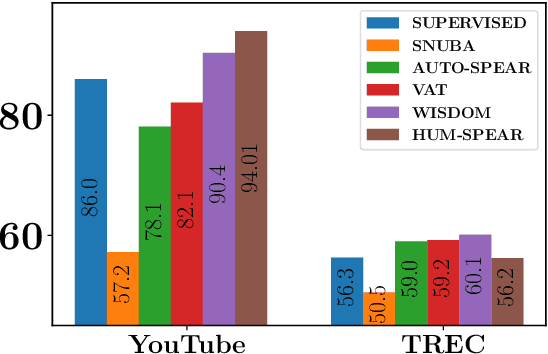
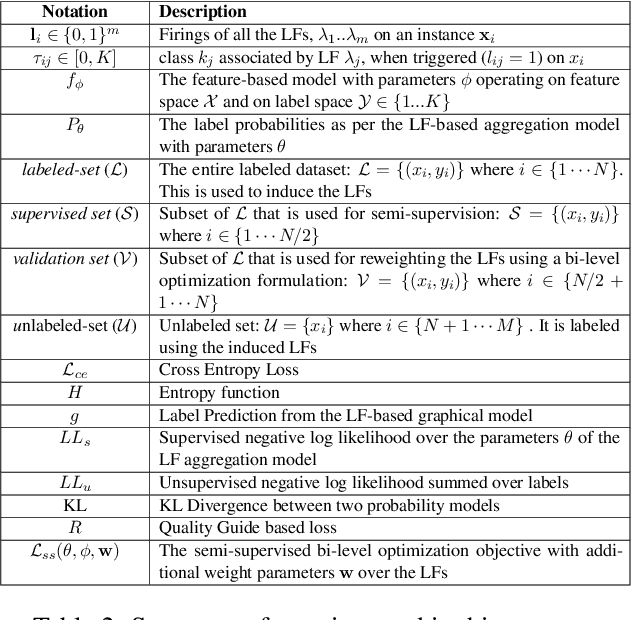
A critical bottleneck in supervised machine learning is the need for large amounts of labeled data which is expensive and time consuming to obtain. However, it has been shown that a small amount of labeled data, while insufficient to re-train a model, can be effectively used to generate human-interpretable labeling functions (LFs). These LFs, in turn, have been used to generate a large amount of additional noisy labeled data, in a paradigm that is now commonly referred to as data programming. However, previous approaches to automatically generate LFs make no attempt to further use the given labeled data for model training, thus giving up opportunities for improved performance. Moreover, since the LFs are generated from a relatively small labeled dataset, they are prone to being noisy, and naively aggregating these LFs can lead to very poor performance in practice. In this work, we propose an LF based reweighting framework \ouralgo{} to solve these two critical limitations. Our algorithm learns a joint model on the (same) labeled dataset used for LF induction along with any unlabeled data in a semi-supervised manner, and more critically, reweighs each LF according to its goodness, influencing its contribution to the semi-supervised loss using a robust bi-level optimization algorithm. We show that our algorithm significantly outperforms prior approaches on several text classification datasets.
Facilitating Knowledge Sharing from Domain Experts to Data Scientists for Building NLP Models
Jan 29, 2021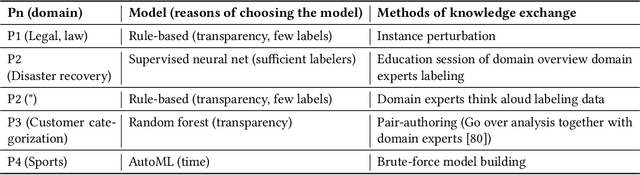

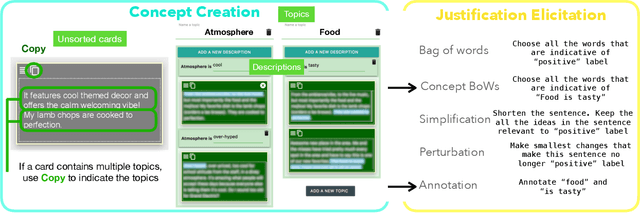
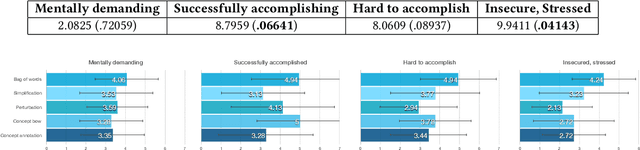
Data scientists face a steep learning curve in understanding a new domain for which they want to build machine learning (ML) models. While input from domain experts could offer valuable help, such input is often limited, expensive, and generally not in a form readily consumable by a model development pipeline. In this paper, we propose Ziva, a framework to guide domain experts in sharing essential domain knowledge to data scientists for building NLP models. With Ziva, experts are able to distill and share their domain knowledge using domain concept extractors and five types of label justification over a representative data sample. The design of Ziva is informed by preliminary interviews with data scientists, in order to understand current practices of domain knowledge acquisition process for ML development projects. To assess our design, we run a mix-method case-study to evaluate how Ziva can facilitate interaction of domain experts and data scientists. Our results highlight that (1) domain experts are able to use Ziva to provide rich domain knowledge, while maintaining low mental load and stress levels; and (2) data scientists find Ziva's output helpful for learning essential information about the domain, offering scalability of information, and lowering the burden on domain experts to share knowledge. We conclude this work by experimenting with building NLP models using the Ziva output by our case study.
A Survey of the State of Explainable AI for Natural Language Processing
Oct 01, 2020

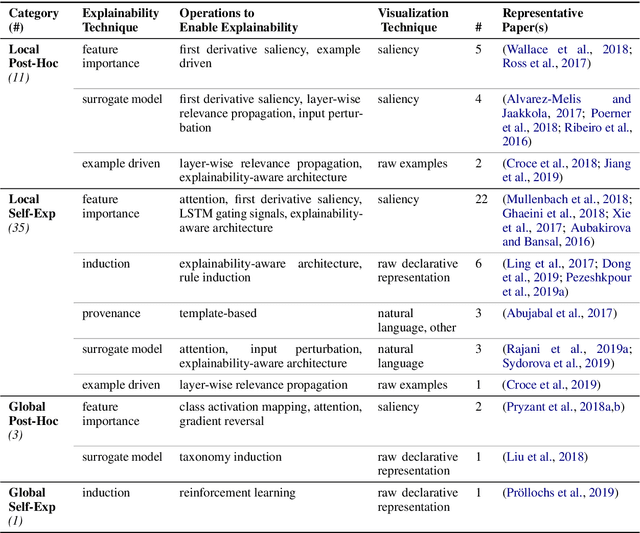

Recent years have seen important advances in the quality of state-of-the-art models, but this has come at the expense of models becoming less interpretable. This survey presents an overview of the current state of Explainable AI (XAI), considered within the domain of Natural Language Processing (NLP). We discuss the main categorization of explanations, as well as the various ways explanations can be arrived at and visualized. We detail the operations and explainability techniques currently available for generating explanations for NLP model predictions, to serve as a resource for model developers in the community. Finally, we point out the current gaps and encourage directions for future work in this important research area.