 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTRAG-UN: A Benchmark for Open Challenges in Multi-Turn RAG Conversations
Feb 26, 2026We present MTRAG-UN, a benchmark for exploring open challenges in multi-turn retrieval augmented generation, a popular use of large language models. We release a benchmark of 666 tasks containing over 2,800 conversation turns across 6 domains with accompanying corpora. Our experiments show that retrieval and generation models continue to struggle on conversations with UNanswerable, UNderspecified, and NONstandalone questions and UNclear responses. Our benchmark is available at https://github.com/IBM/mt-rag-benchmark
A Library of LLM Intrinsics for Retrieval-Augmented Generation
Apr 16, 2025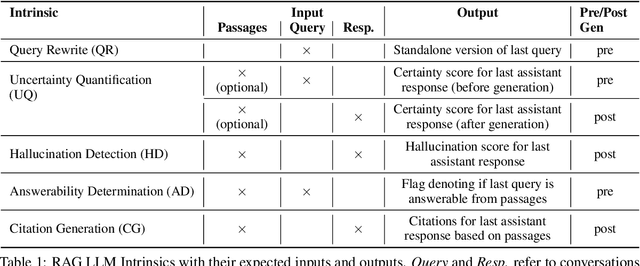
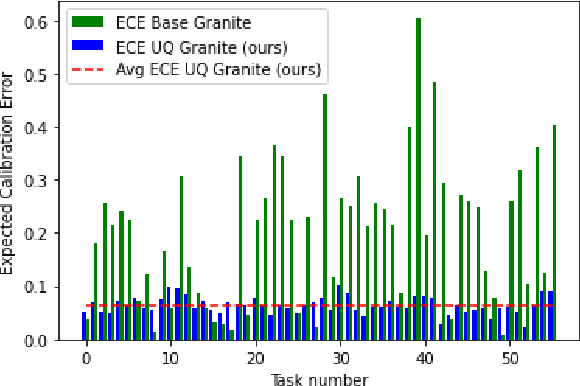

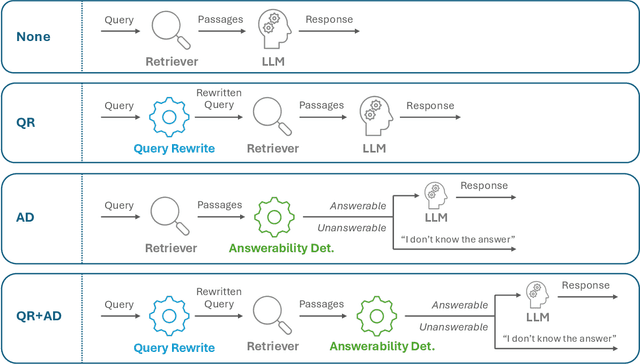
In the developer community for large language models (LLMs), there is not yet a clean pattern analogous to a software library, to support very large scale collaboration. Even for the commonplace use case of Retrieval-Augmented Generation (RAG), it is not currently possible to write a RAG application against a well-defined set of APIs that are agreed upon by different LLM providers. Inspired by the idea of compiler intrinsics, we propose some elements of such a concept through introducing a library of LLM Intrinsics for RAG. An LLM intrinsic is defined as a capability that can be invoked through a well-defined API that is reasonably stable and independent of how the LLM intrinsic itself is implemented. The intrinsics in our library are released as LoRA adapters on HuggingFace, and through a software interface with clear structured input/output characteristics on top of vLLM as an inference platform, accompanied in both places with documentation and code. This article describes the intended usage, training details, and evaluations for each intrinsic, as well as compositions of multiple intrinsics.
Activated LoRA: Fine-tuned LLMs for Intrinsics
Apr 16, 2025Low-Rank Adaptation (LoRA) has emerged as a highly efficient framework for finetuning the weights of large foundation models, and has become the go-to method for data-driven customization of LLMs. Despite the promise of highly customized behaviors and capabilities, switching between relevant LoRAs in a multiturn setting is highly inefficient, as the key-value (KV) cache of the entire turn history must be recomputed with the LoRA weights before generation can begin. To address this problem, we propose Activated LoRA (aLoRA), which modifies the LoRA framework to only adapt weights for the tokens in the sequence \emph{after} the aLoRA is invoked. This change crucially allows aLoRA to accept the base model's KV cache of the input string, meaning that aLoRA can be instantly activated whenever needed in a chain without recomputing the cache. This enables building what we call \emph{intrinsics}, i.e. highly specialized models invoked to perform well-defined operations on portions of an input chain or conversation that otherwise uses the base model by default. We use aLoRA to train a set of intrinsics models, demonstrating competitive accuracy with standard LoRA while achieving significant inference benefits.
MTRAG: A Multi-Turn Conversational Benchmark for Evaluating Retrieval-Augmented Generation Systems
Jan 07, 2025



Retrieval-augmented generation (RAG) has recently become a very popular task for Large Language Models (LLMs). Evaluating them on multi-turn RAG conversations, where the system is asked to generate a response to a question in the context of a preceding conversation is an important and often overlooked task with several additional challenges. We present MTRAG: an end-to-end human-generated multi-turn RAG benchmark that reflects several real-world properties across diverse dimensions for evaluating the full RAG pipeline. MTRAG contains 110 conversations averaging 7.7 turns each across four domains for a total of 842 tasks. We also explore automation paths via synthetic data and LLM-as-a-Judge evaluation. Our human and automatic evaluations show that even state-of-the-art LLM RAG systems struggle on MTRAG. We demonstrate the need for strong retrieval and generation systems that can handle later turns, unanswerable questions, non-standalone questions, and multiple domains. MTRAG is available at https://github.com/ibm/mt-rag-benchmark.
Are Key-Foreign Key Joins Safe to Avoid when Learning High-Capacity Classifiers?
Jun 04, 2017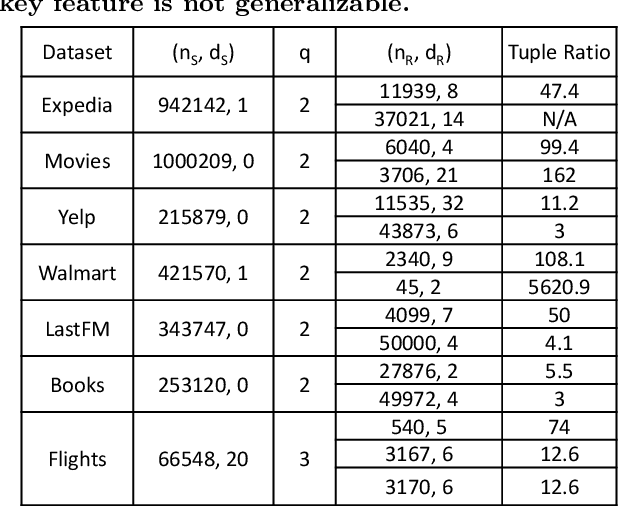
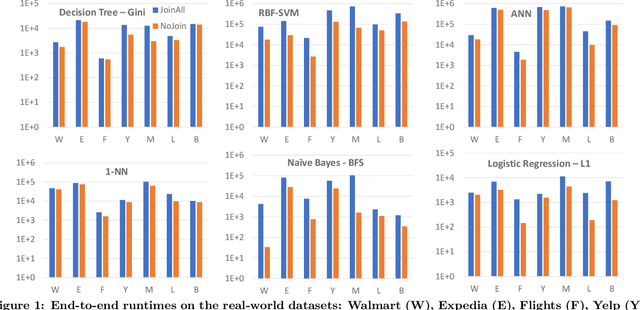
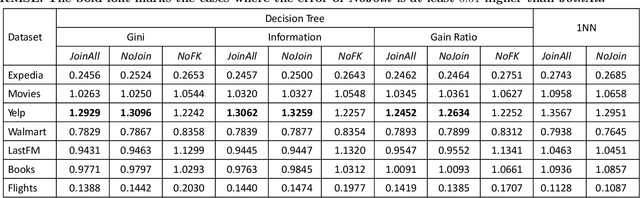
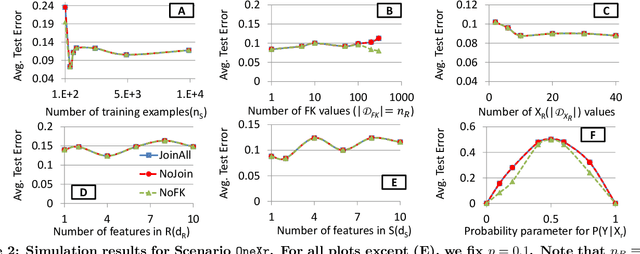
Machine learning (ML) over relational data is a booming area of the database industry and academia. While several projects aim to build scalable and fast ML systems, little work has addressed the pains of sourcing data and features for ML tasks. Real-world relational databases typically have many tables (often, dozens) and data scientists often struggle to even obtain and join all possible tables that provide features for ML. In this context, Kumar et al. showed recently that key-foreign key dependencies (KFKDs) between tables often lets us avoid such joins without significantly affecting prediction accuracy--an idea they called avoiding joins safely. While initially controversial, this idea has since been used by multiple companies to reduce the burden of data sourcing for ML. But their work applied only to linear classifiers. In this work, we verify if their results hold for three popular complex classifiers: decision trees, SVMs, and ANNs. We conduct an extensive experimental study using both real-world datasets and simulations to analyze the effects of avoiding KFK joins on such models. Our results show that these high-capacity classifiers are surprisingly and counter-intuitively more robust to avoiding KFK joins compared to linear classifiers, refuting an intuition from the prior work's analysis. We explain this behavior intuitively and identify open questions at the intersection of data management and ML theoretical research. All of our code and datasets are available for download from http://cseweb.ucsd.edu/~arunkk/hamlet.