 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Library of LLM Intrinsics for Retrieval-Augmented Generation
Apr 16, 2025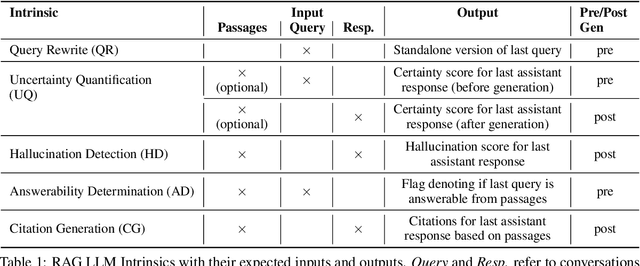
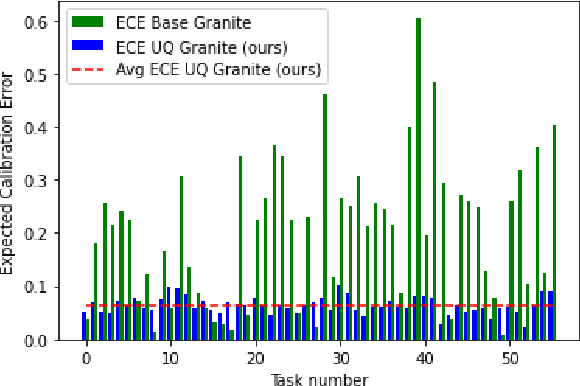

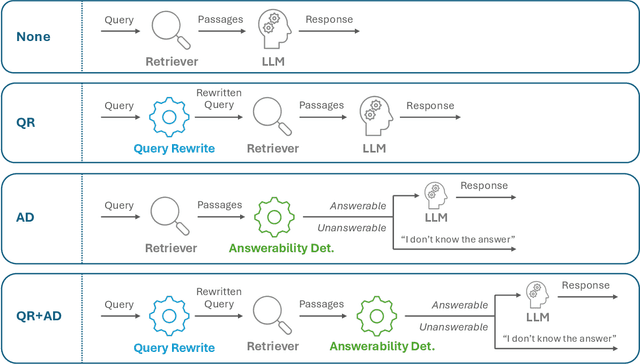
In the developer community for large language models (LLMs), there is not yet a clean pattern analogous to a software library, to support very large scale collaboration. Even for the commonplace use case of Retrieval-Augmented Generation (RAG), it is not currently possible to write a RAG application against a well-defined set of APIs that are agreed upon by different LLM providers. Inspired by the idea of compiler intrinsics, we propose some elements of such a concept through introducing a library of LLM Intrinsics for RAG. An LLM intrinsic is defined as a capability that can be invoked through a well-defined API that is reasonably stable and independent of how the LLM intrinsic itself is implemented. The intrinsics in our library are released as LoRA adapters on HuggingFace, and through a software interface with clear structured input/output characteristics on top of vLLM as an inference platform, accompanied in both places with documentation and code. This article describes the intended usage, training details, and evaluations for each intrinsic, as well as compositions of multiple intrinsics.
MTRAG: A Multi-Turn Conversational Benchmark for Evaluating Retrieval-Augmented Generation Systems
Jan 07, 2025



Retrieval-augmented generation (RAG) has recently become a very popular task for Large Language Models (LLMs). Evaluating them on multi-turn RAG conversations, where the system is asked to generate a response to a question in the context of a preceding conversation is an important and often overlooked task with several additional challenges. We present MTRAG: an end-to-end human-generated multi-turn RAG benchmark that reflects several real-world properties across diverse dimensions for evaluating the full RAG pipeline. MTRAG contains 110 conversations averaging 7.7 turns each across four domains for a total of 842 tasks. We also explore automation paths via synthetic data and LLM-as-a-Judge evaluation. Our human and automatic evaluations show that even state-of-the-art LLM RAG systems struggle on MTRAG. We demonstrate the need for strong retrieval and generation systems that can handle later turns, unanswerable questions, non-standalone questions, and multiple domains. MTRAG is available at https://github.com/ibm/mt-rag-benchmark.
Genetic Quantization-Aware Approximation for Non-Linear Operations in Transformers
Mar 29, 2024



Non-linear functions are prevalent in Transformers and their lightweight variants, incurring substantial and frequently underestimated hardware costs. Previous state-of-the-art works optimize these operations by piece-wise linear approximation and store the parameters in look-up tables (LUT), but most of them require unfriendly high-precision arithmetics such as FP/INT 32 and lack consideration of integer-only INT quantization. This paper proposed a genetic LUT-Approximation algorithm namely GQA-LUT that can automatically determine the parameters with quantization awareness. The results demonstrate that GQA-LUT achieves negligible degradation on the challenging semantic segmentation task for both vanilla and linear Transformer models. Besides, proposed GQA-LUT enables the employment of INT8-based LUT-Approximation that achieves an area savings of 81.3~81.7% and a power reduction of 79.3~80.2% compared to the high-precision FP/INT 32 alternatives. Code is available at https:// github.com/PingchengDong/GQA-LUT.
PriMeSRL-Eval: A Practical Quality Metric for Semantic Role Labeling Systems Evaluation
Oct 12, 2022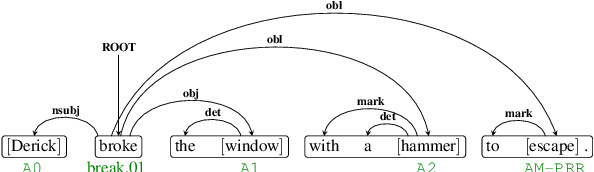
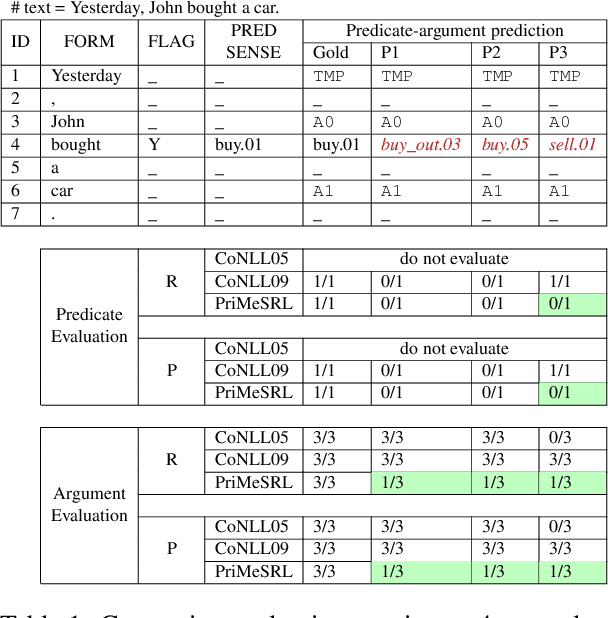
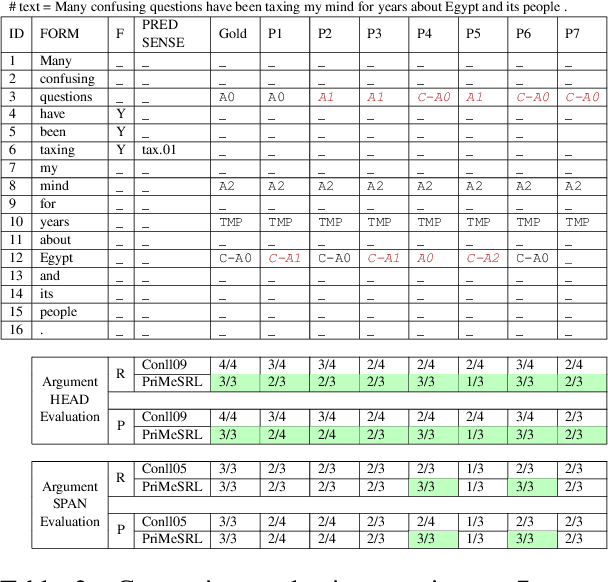
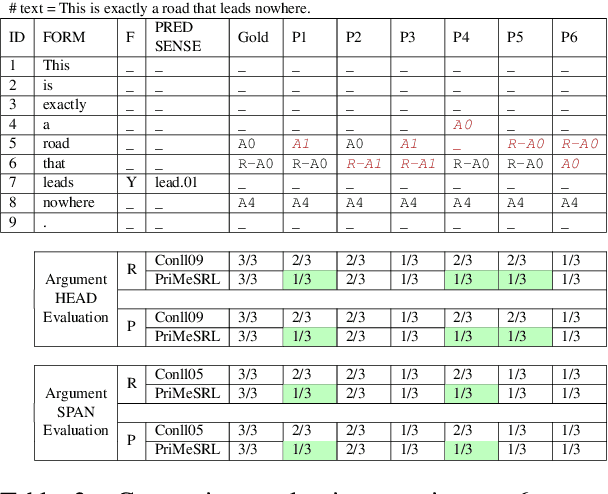
Semantic role labeling (SRL) identifies the predicate-argument structure in a sentence. This task is usually accomplished in four steps: predicate identification, predicate sense disambiguation, argument identification, and argument classification. Errors introduced at one step propagate to later steps. Unfortunately, the existing SRL evaluation scripts do not consider the full effect of this error propagation aspect. They either evaluate arguments independent of predicate sense (CoNLL09) or do not evaluate predicate sense at all (CoNLL05), yielding an inaccurate SRL model performance on the argument classification task. In this paper, we address key practical issues with existing evaluation scripts and propose a more strict SRL evaluation metric PriMeSRL. We observe that by employing PriMeSRL, the quality evaluation of all SoTA SRL models drops significantly, and their relative rankings also change. We also show that PriMeSRLsuccessfully penalizes actual failures in SoTA SRL models.
Improved Semantic Role Labeling using Parameterized Neighborhood Memory Adaptation
Nov 29, 2020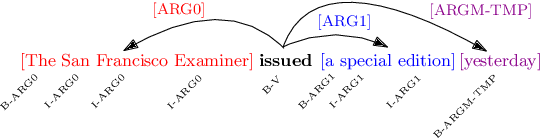
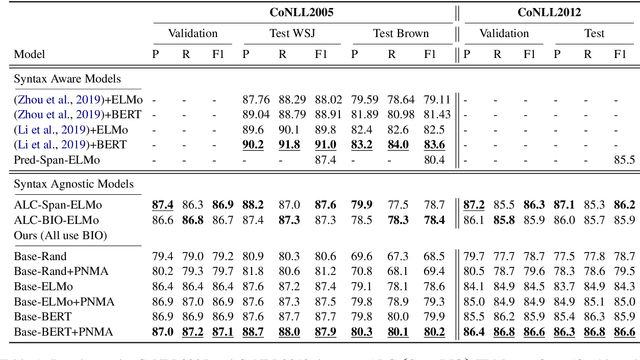
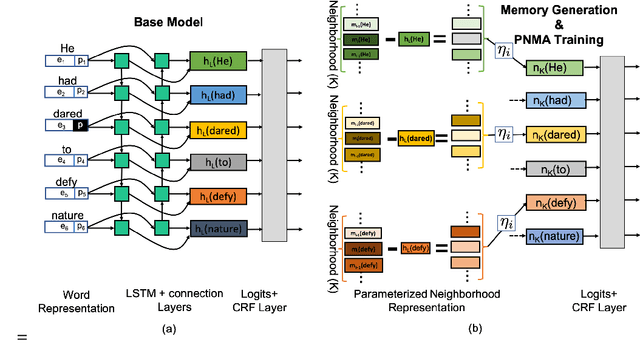
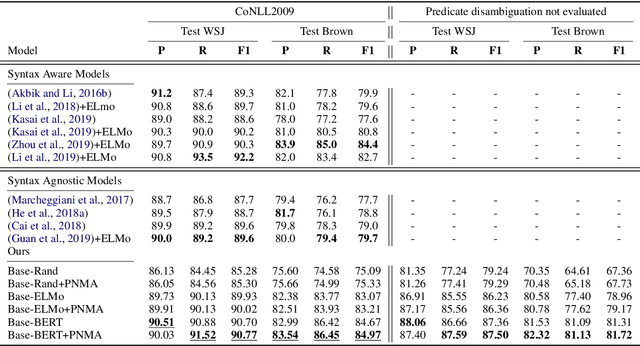
Deep neural models achieve some of the best results for semantic role labeling. Inspired by instance-based learning that utilizes nearest neighbors to handle low-frequency context-specific training samples, we investigate the use of memory adaptation techniques in deep neural models. We propose a parameterized neighborhood memory adaptive (PNMA) method that uses a parameterized representation of the nearest neighbors of tokens in a memory of activations and makes predictions based on the most similar samples in the training data. We empirically show that PNMA consistently improves the SRL performance of the base model irrespective of types of word embeddings. Coupled with contextualized word embeddings derived from BERT, PNMA improves over existing models for both span and dependency semantic parsing datasets, especially on out-of-domain text, reaching F1 scores of 80.2, and 84.97 on CoNLL2005, and CoNLL2009 datasets, respectively.
CLAR: A Cross-Lingual Argument Regularizer for Semantic Role Labeling
Nov 09, 2020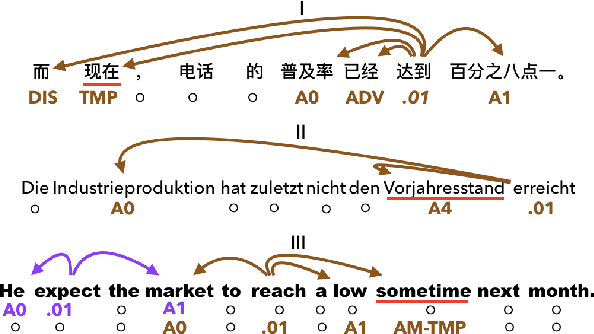



Semantic role labeling (SRL) identifies predicate-argument structure(s) in a given sentence. Although different languages have different argument annotations, polyglot training, the idea of training one model on multiple languages, has previously been shown to outperform monolingual baselines, especially for low resource languages. In fact, even a simple combination of data has been shown to be effective with polyglot training by representing the distant vocabularies in a shared representation space. Meanwhile, despite the dissimilarity in argument annotations between languages, certain argument labels do share common semantic meaning across languages (e.g. adjuncts have more or less similar semantic meaning across languages). To leverage such similarity in annotation space across languages, we propose a method called Cross-Lingual Argument Regularizer (CLAR). CLAR identifies such linguistic annotation similarity across languages and exploits this information to map the target language arguments using a transformation of the space on which source language arguments lie. By doing so, our experimental results show that CLAR consistently improves SRL performance on multiple languages over monolingual and polyglot baselines for low resource languages.
Small but Mighty: New Benchmarks for Split and Rephrase
Sep 17, 2020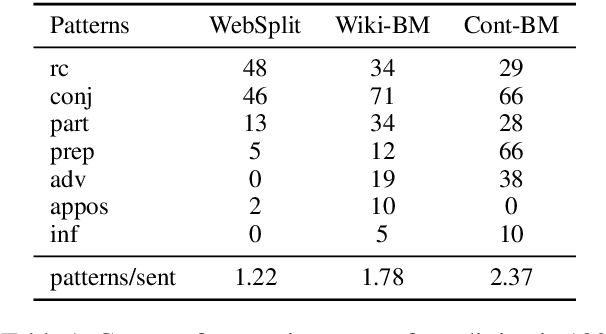
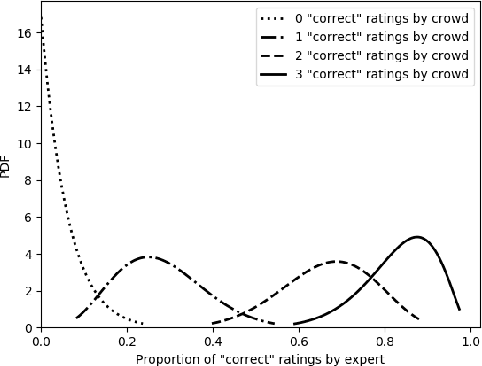
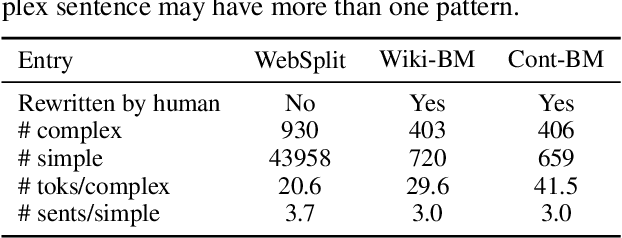
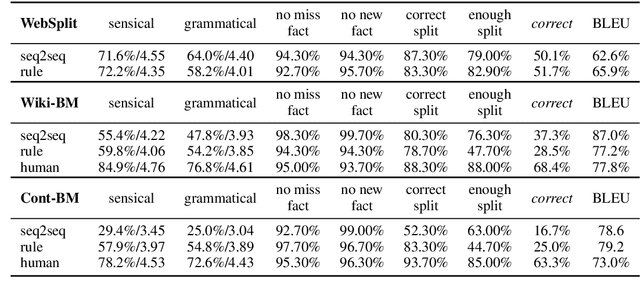
Split and Rephrase is a text simplification task of rewriting a complex sentence into simpler ones. As a relatively new task, it is paramount to ensure the soundness of its evaluation benchmark and metric. We find that the widely used benchmark dataset universally contains easily exploitable syntactic cues caused by its automatic generation process. Taking advantage of such cues, we show that even a simple rule-based model can perform on par with the state-of-the-art model. To remedy such limitations, we collect and release two crowdsourced benchmark datasets. We not only make sure that they contain significantly more diverse syntax, but also carefully control for their quality according to a well-defined set of criteria. While no satisfactory automatic metric exists, we apply fine-grained manual evaluation based on these criteria using crowdsourcing, showing that our datasets better represent the task and are significantly more challenging for the models.