 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTRAG: A Multi-Turn Conversational Benchmark for Evaluating Retrieval-Augmented Generation Systems
Jan 07, 2025



Retrieval-augmented generation (RAG) has recently become a very popular task for Large Language Models (LLMs). Evaluating them on multi-turn RAG conversations, where the system is asked to generate a response to a question in the context of a preceding conversation is an important and often overlooked task with several additional challenges. We present MTRAG: an end-to-end human-generated multi-turn RAG benchmark that reflects several real-world properties across diverse dimensions for evaluating the full RAG pipeline. MTRAG contains 110 conversations averaging 7.7 turns each across four domains for a total of 842 tasks. We also explore automation paths via synthetic data and LLM-as-a-Judge evaluation. Our human and automatic evaluations show that even state-of-the-art LLM RAG systems struggle on MTRAG. We demonstrate the need for strong retrieval and generation systems that can handle later turns, unanswerable questions, non-standalone questions, and multiple domains. MTRAG is available at https://github.com/ibm/mt-rag-benchmark.
PrimeQA: The Prime Repository for State-of-the-Art Multilingual Question Answering Research and Development
Jan 25, 2023



The field of Question Answering (QA) has made remarkable progress in recent years, thanks to the advent of large pre-trained language models, newer realistic benchmark datasets with leaderboards, and novel algorithms for key components such as retrievers and readers. In this paper, we introduce PRIMEQA: a one-stop and open-source QA repository with an aim to democratize QA re-search and facilitate easy replication of state-of-the-art (SOTA) QA methods. PRIMEQA supports core QA functionalities like retrieval and reading comprehension as well as auxiliary capabilities such as question generation.It has been designed as an end-to-end toolkit for various use cases: building front-end applications, replicating SOTA methods on pub-lic benchmarks, and expanding pre-existing methods. PRIMEQA is available at : https://github.com/primeqa.
CLAI: A Platform for AI Skills on the Command Line
Jan 31, 2020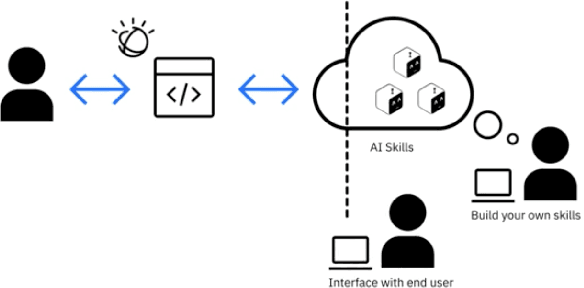


This paper reports on the open source project CLAI (Command Line AI), aimed at bringing the power of AI to the command line interface. The platform sets up the CLI as a new environment for AI researchers to conquer by surfacing the command line as a generic environment that researchers can interface to using a simple sense-act API much like the traditional AI agent architecture. In this paper, we discuss the design and implementation of the platform in detail, through illustrative use cases of new end user interaction patterns enabled by this design, and through quantitative evaluation of the system footprint of a CLAI-enabled terminal. We also report on some early user feedback on its features from an internal survey.
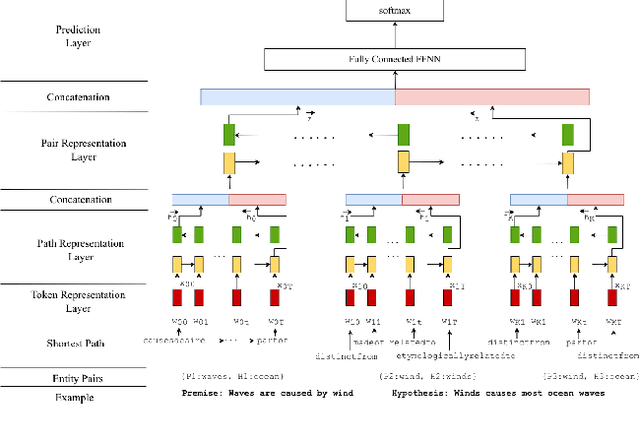
Infusing Knowledge into the Textual Entailment Task Using Graph Convolutional Networks
Nov 22, 2019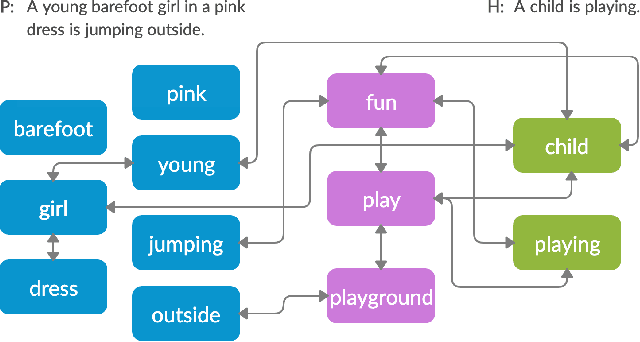

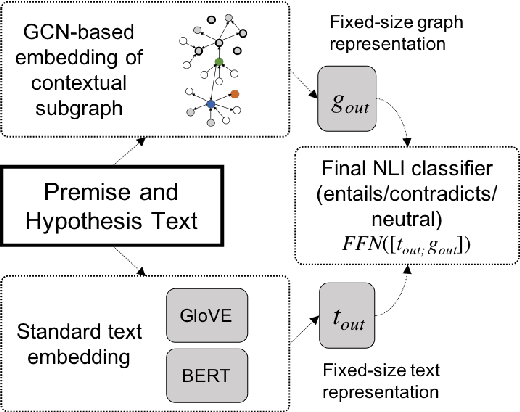
Textual entailment is a fundamental task in natural language processing. Most approaches for solving the problem use only the textual content present in training data. A few approaches have shown that information from external knowledge sources like knowledge graphs (KGs) can add value, in addition to the textual content, by providing background knowledge that may be critical for a task. However, the proposed models do not fully exploit the information in the usually large and noisy KGs, and it is not clear how it can be effectively encoded to be useful for entailment. We present an approach that complements text-based entailment models with information from KGs by (1) using Personalized PageR- ank to generate contextual subgraphs with reduced noise and (2) encoding these subgraphs using graph convolutional networks to capture KG structure. Our technique extends the capability of text models exploiting structural and semantic information found in KGs. We evaluate our approach on multiple textual entailment datasets and show that the use of external knowledge helps improve prediction accuracy. This is particularly evident in the challenging BreakingNLI dataset, where we see an absolute improvement of 5-20% over multiple text-based entailment models.
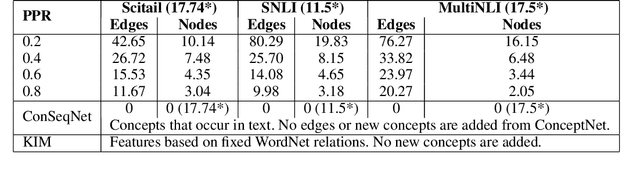
Heuristics for Interpretable Knowledge Graph Contextualization
Nov 05, 2019


In this paper, we introduce the problem of knowledge graph contextualization that is, given a specific context, the problem of extracting the most relevant sub-graph of a given knowledge graph. The context in the case of this paper is defined to be the textual entailment problem, and more specifically an instance of that problem where the entailment relationship between two sentences P and H has to be predicted automatically. This prediction takes the form of a classification task, and we seek to provide that task with the most relevant external knowledge while eliminating as much noise as possible. We base our methodology on finding the shortest paths in the cost-customized external knowledge graph that connect P and H, and build a series of methods starting with manually curated search heuristics and culminating in automatically extracted heuristics to find such paths and build the most relevant sub-graph. We evaluate our approaches by measuring the accuracy of the classification on the textual entailment problem, and show that modulating the external knowledge that is used has an impact on performance.
Knowledge-incorporating ESIM models for Response Selection in Retrieval-based Dialog Systems
Jul 11, 2019
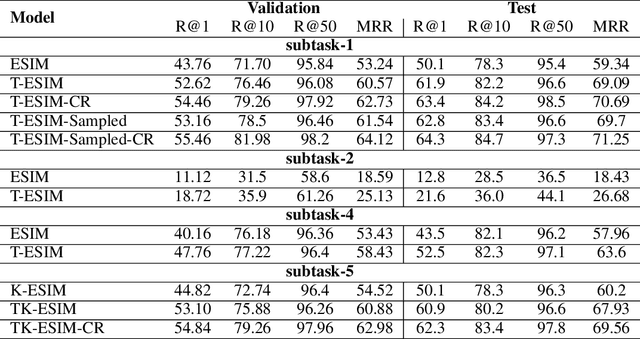

Goal-oriented dialog systems, which can be trained end-to-end without manually encoding domain-specific features, show tremendous promise in the customer support use-case e.g. flight booking, hotel reservation, technical support, student advising etc. These dialog systems must learn to interact with external domain knowledge to achieve the desired goal e.g. recommending courses to a student, booking a table at a restaurant etc. This paper presents extended Enhanced Sequential Inference Model (ESIM) models: a) K-ESIM (Knowledge-ESIM), which incorporates the external domain knowledge and b) T-ESIM (Targeted-ESIM), which leverages information from similar conversations to improve the prediction accuracy. Our proposed models and the baseline ESIM model are evaluated on the Ubuntu and Advising datasets in the Sentence Selection track of the latest Dialog System Technology Challenge (DSTC7), where the goal is to find the correct next utterance, given a partial conversation, from a set of candidates. Our preliminary results suggest that incorporating external knowledge sources and leveraging information from similar dialogs leads to performance improvements for predicting the next utterance.