 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeuristics for Interpretable Knowledge Graph Contextualization
Paper and Code


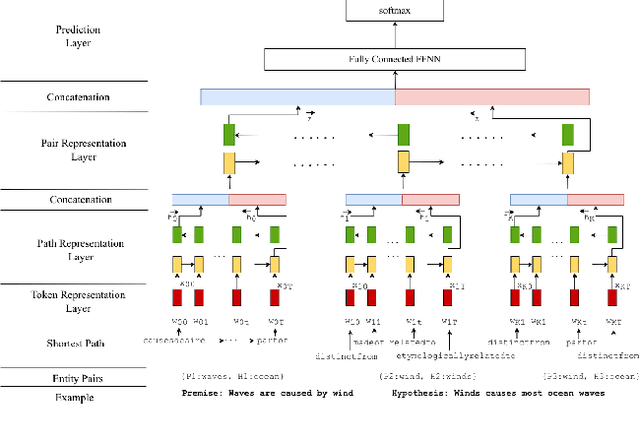

In this paper, we introduce the problem of knowledge graph contextualization that is, given a specific context, the problem of extracting the most relevant sub-graph of a given knowledge graph. The context in the case of this paper is defined to be the textual entailment problem, and more specifically an instance of that problem where the entailment relationship between two sentences P and H has to be predicted automatically. This prediction takes the form of a classification task, and we seek to provide that task with the most relevant external knowledge while eliminating as much noise as possible. We base our methodology on finding the shortest paths in the cost-customized external knowledge graph that connect P and H, and build a series of methods starting with manually curated search heuristics and culminating in automatically extracted heuristics to find such paths and build the most relevant sub-graph. We evaluate our approaches by measuring the accuracy of the classification on the textual entailment problem, and show that modulating the external knowledge that is used has an impact on performance.