 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Steerability 360: A Toolkit for Steering Large Language Models
Mar 08, 2026The AI Steerability 360 toolkit is an extensible, open-source Python library for steering LLMs. Steering abstractions are designed around four model control surfaces: input (modification of the prompt), structural (modification of the model's weights or architecture), state (modification of the model's activations and attentions), and output (modification of the decoding or generation process). Steering methods exert control on the model through a common interface, termed a steering pipeline, which additionally allows for the composition of multiple steering methods. Comprehensive evaluation and comparison of steering methods/pipelines is facilitated by use case classes (for defining tasks) and a benchmark class (for performance comparison on a given task). The functionality provided by the toolkit significantly lowers the barrier to developing and comprehensively evaluating steering methods. The toolkit is Hugging Face native and is released under an Apache 2.0 license at https://github.com/IBM/AISteer360.
DeepVoting: Learning Voting Rules with Tailored Embeddings
Aug 24, 2024



Aggregating the preferences of multiple agents into a collective decision is a common step in many important problems across areas of computer science including information retrieval, reinforcement learning, and recommender systems. As Social Choice Theory has shown, the problem of designing algorithms for aggregation rules with specific properties (axioms) can be difficult, or provably impossible in some cases. Instead of designing algorithms by hand, one can learn aggregation rules, particularly voting rules, from data. However, the prior work in this area has required extremely large models, or been limited by the choice of preference representation, i.e., embedding. We recast the problem of designing a good voting rule into one of learning probabilistic versions of voting rules that output distributions over a set of candidates. Specifically, we use neural networks to learn probabilistic social choice functions from the literature. We show that embeddings of preference profiles derived from the social choice literature allows us to learn existing voting rules more efficiently and scale to larger populations of voters more easily than other work if the embedding is tailored to the learning objective. Moreover, we show that rules learned using embeddings can be tweaked to create novel voting rules with improved axiomatic properties. Namely, we show that existing voting rules require only minor modification to combat a probabilistic version of the No Show Paradox.
Learning Global Transparent Models from Local Contrastive Explanations
Feb 19, 2020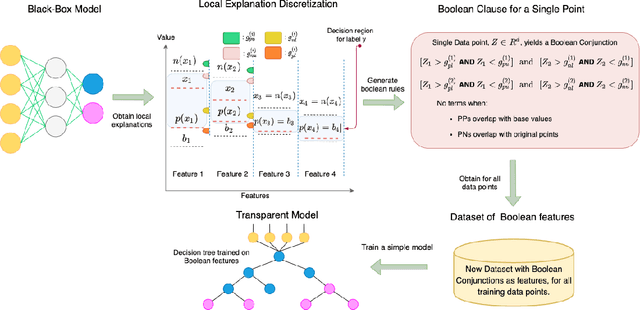
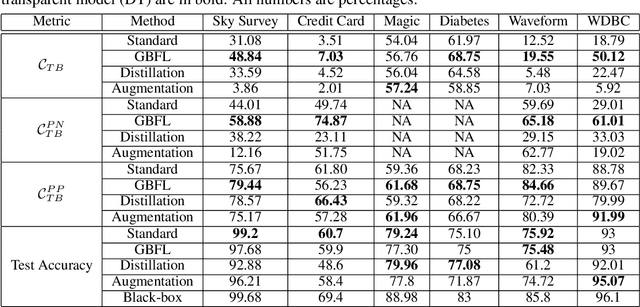
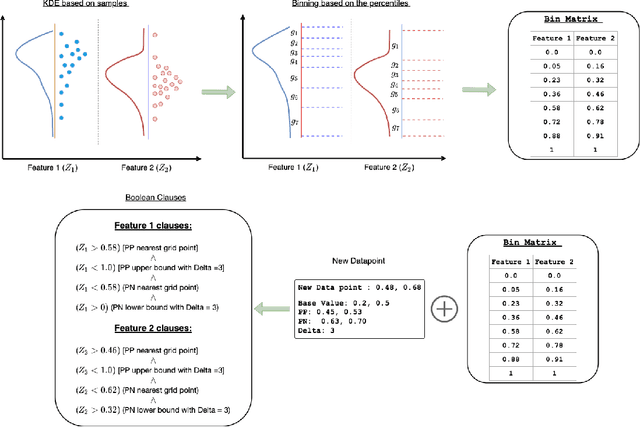
There is a rich and growing literature on producing local point wise contrastive/counterfactual explanations for complex models. These methods highlight what is important to justify the classification and/or produce a contrast point that alters the final classification. Other works try to build globally interpretable models like decision trees and rule lists directly by efficient model search using the data or by transferring information from a complex model using distillation-like methods. Although these interpretable global models can be useful, they may not be consistent with local explanations from a specific complex model of choice. In this work, we explore the question: Can we produce a transparent global model that is consistent with/derivable from local explanations? Based on a key insight we provide a novel method where every local contrastive/counterfactual explanation can be turned into a Boolean feature. These Boolean features are sparse conjunctions of binarized features. The dataset thus constructed is consistent with local explanations by design and one can train an interpretable model like a decision tree on it. We note that this approach strictly loses information due to reliance only on sparse local explanations, nonetheless, we demonstrate empirically that in many cases it can still be competitive with respect to the complex model's performance and also other methods that learn directly from the original dataset. Our approach also provides an avenue to benchmark local explanation methods in a quantitative manner.
Infusing Knowledge into the Textual Entailment Task Using Graph Convolutional Networks
Nov 22, 2019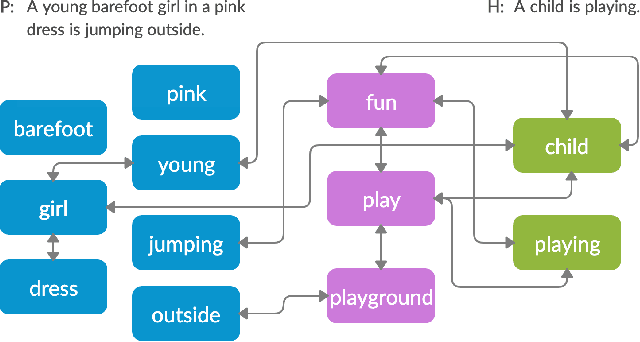

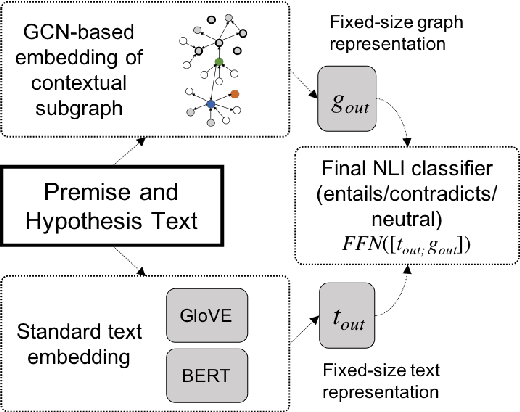
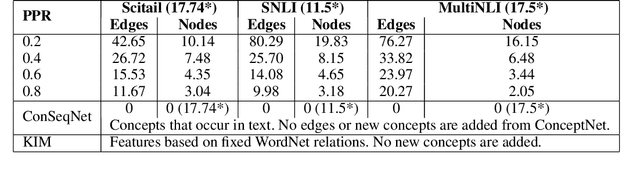
Textual entailment is a fundamental task in natural language processing. Most approaches for solving the problem use only the textual content present in training data. A few approaches have shown that information from external knowledge sources like knowledge graphs (KGs) can add value, in addition to the textual content, by providing background knowledge that may be critical for a task. However, the proposed models do not fully exploit the information in the usually large and noisy KGs, and it is not clear how it can be effectively encoded to be useful for entailment. We present an approach that complements text-based entailment models with information from KGs by (1) using Personalized PageR- ank to generate contextual subgraphs with reduced noise and (2) encoding these subgraphs using graph convolutional networks to capture KG structure. Our technique extends the capability of text models exploiting structural and semantic information found in KGs. We evaluate our approach on multiple textual entailment datasets and show that the use of external knowledge helps improve prediction accuracy. This is particularly evident in the challenging BreakingNLI dataset, where we see an absolute improvement of 5-20% over multiple text-based entailment models.
Model Agnostic Contrastive Explanations for Structured Data
May 31, 2019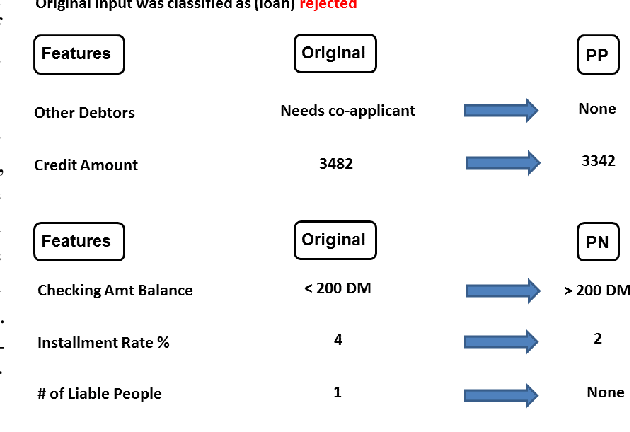
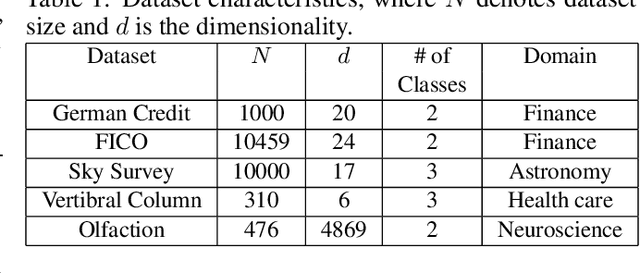
Recently, a method [7] was proposed to generate contrastive explanations for differentiable models such as deep neural networks, where one has complete access to the model. In this work, we propose a method, Model Agnostic Contrastive Explanations Method (MACEM), to generate contrastive explanations for \emph{any} classification model where one is able to \emph{only} query the class probabilities for a desired input. This allows us to generate contrastive explanations for not only neural networks, but models such as random forests, boosted trees and even arbitrary ensembles that are still amongst the state-of-the-art when learning on structured data [13]. Moreover, to obtain meaningful explanations we propose a principled approach to handle real and categorical features leading to novel formulations for computing pertinent positives and negatives that form the essence of a contrastive explanation. A detailed treatment of the different data types of this nature was not performed in the previous work, which assumed all features to be positive real valued with zero being indicative of the least interesting value. We part with this strong implicit assumption and generalize these methods so as to be applicable across a much wider range of problem settings. We quantitatively and qualitatively validate our approach over 5 public datasets covering diverse domains.
Word Mover's Embedding: From Word2Vec to Document Embedding
Oct 30, 2018
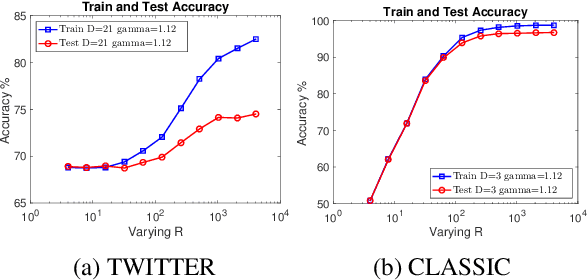
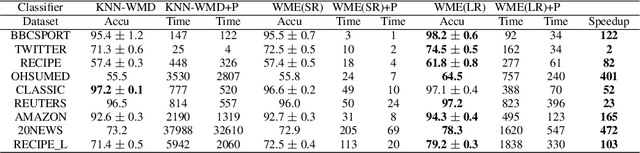
While the celebrated Word2Vec technique yields semantically rich representations for individual words, there has been relatively less success in extending to generate unsupervised sentences or documents embeddings. Recent work has demonstrated that a distance measure between documents called \emph{Word Mover's Distance} (WMD) that aligns semantically similar words, yields unprecedented KNN classification accuracy. However, WMD is expensive to compute, and it is hard to extend its use beyond a KNN classifier. In this paper, we propose the \emph{Word Mover's Embedding } (WME), a novel approach to building an unsupervised document (sentence) embedding from pre-trained word embeddings. In our experiments on 9 benchmark text classification datasets and 22 textual similarity tasks, the proposed technique consistently matches or outperforms state-of-the-art techniques, with significantly higher accuracy on problems of short length.
Incorporating Behavioral Constraints in Online AI Systems
Sep 15, 2018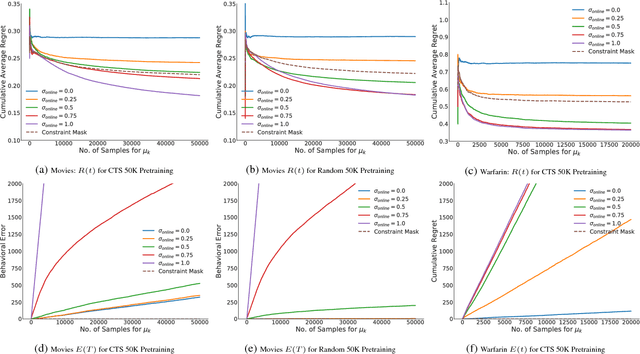
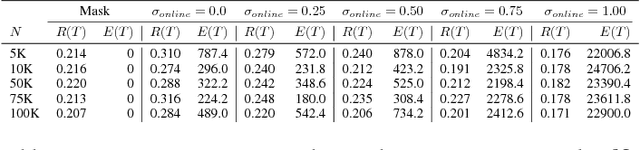
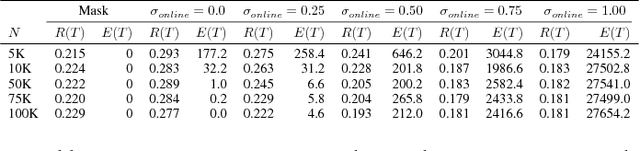
AI systems that learn through reward feedback about the actions they take are increasingly deployed in domains that have significant impact on our daily life. However, in many cases the online rewards should not be the only guiding criteria, as there are additional constraints and/or priorities imposed by regulations, values, preferences, or ethical principles. We detail a novel online agent that learns a set of behavioral constraints by observation and uses these learned constraints as a guide when making decisions in an online setting while still being reactive to reward feedback. To define this agent, we propose to adopt a novel extension to the classical contextual multi-armed bandit setting and we provide a new algorithm called Behavior Constrained Thompson Sampling (BCTS) that allows for online learning while obeying exogenous constraints. Our agent learns a constrained policy that implements the observed behavioral constraints demonstrated by a teacher agent, and then uses this constrained policy to guide the reward-based online exploration and exploitation. We characterize the upper bound on the expected regret of the contextual bandit algorithm that underlies our agent and provide a case study with real world data in two application domains. Our experiments show that the designed agent is able to act within the set of behavior constraints without significantly degrading its overall reward performance.
Variational Inference of Disentangled Latent Concepts from Unlabeled Observations
Nov 07, 2017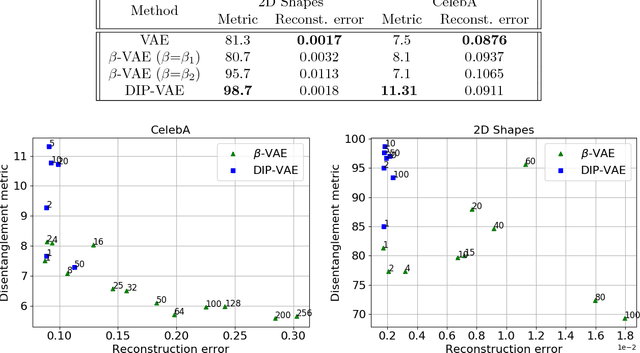
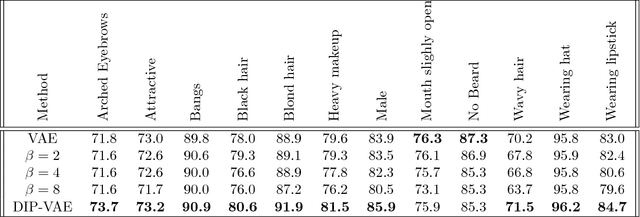
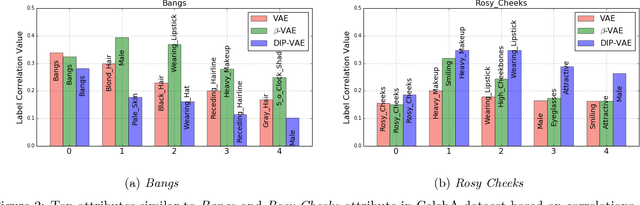
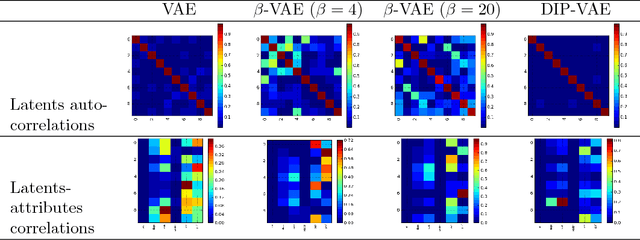
Disentangled representations, where the higher level data generative factors are reflected in disjoint latent dimensions, offer several benefits such as ease of deriving invariant representations, transferability to other tasks, interpretability, etc. We consider the problem of unsupervised learning of disentangled representations from large pool of unlabeled observations, and propose a variational inference based approach to infer disentangled latent factors. We introduce a regularizer on the expectation of the approximate posterior over observed data that encourages the disentanglement. We evaluate the proposed approach using several quantitative metrics and empirically observe significant gains over existing methods in terms of both disentanglement and data likelihood (reconstruction quality).