 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWideSeek: Advancing Wide Research via Multi-Agent Scaling
Feb 02, 2026Search intelligence is evolving from Deep Research to Wide Research, a paradigm essential for retrieving and synthesizing comprehensive information under complex constraints in parallel. However, progress in this field is impeded by the lack of dedicated benchmarks and optimization methodologies for search breadth. To address these challenges, we take a deep dive into Wide Research from two perspectives: Data Pipeline and Agent Optimization. First, we produce WideSeekBench, a General Broad Information Seeking (GBIS) benchmark constructed via a rigorous multi-phase data pipeline to ensure diversity across the target information volume, logical constraints, and domains. Second, we introduce WideSeek, a dynamic hierarchical multi-agent architecture that can autonomously fork parallel sub-agents based on task requirements. Furthermore, we design a unified training framework that linearizes multi-agent trajectories and optimizes the system using end-to-end RL. Experimental results demonstrate the effectiveness of WideSeek and multi-agent RL, highlighting that scaling the number of agents is a promising direction for advancing the Wide Research paradigm.
Learning from Next-Frame Prediction: Autoregressive Video Modeling Encodes Effective Representations
Dec 24, 2025



Recent advances in pretraining general foundation models have significantly improved performance across diverse downstream tasks. While autoregressive (AR) generative models like GPT have revolutionized NLP, most visual generative pretraining methods still rely on BERT-style masked modeling, which often disregards the temporal information essential for video analysis. The few existing autoregressive visual pretraining methods suffer from issues such as inaccurate semantic localization and poor generation quality, leading to poor semantics. In this work, we propose NExT-Vid, a novel autoregressive visual generative pretraining framework that utilizes masked next-frame prediction to jointly model images and videos. NExT-Vid introduces a context-isolated autoregressive predictor to decouple semantic representation from target decoding, and a conditioned flow-matching decoder to enhance generation quality and diversity. Through context-isolated flow-matching pretraining, our approach achieves strong representations. Extensive experiments on large-scale pretrained models demonstrate that our proposed method consistently outperforms previous generative pretraining methods for visual representation learning via attentive probing in downstream classification.
Broadband Near-Infrared Compressive Spectral Imaging System with Reflective Structure
Aug 20, 2025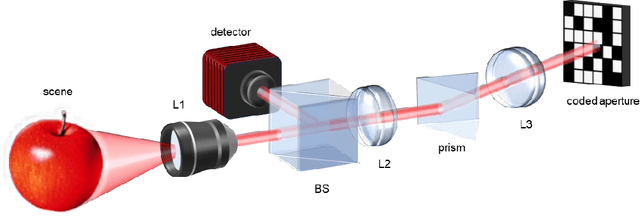


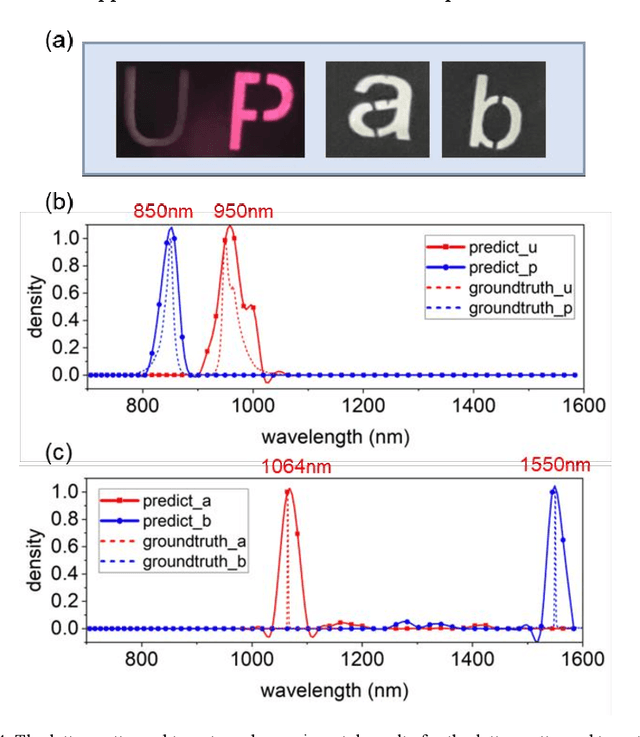
Near-infrared (NIR) hyperspectral imaging has become a critical tool in modern analytical science. However, conventional NIR hyperspectral imaging systems face challenges including high cost, bulky instrumentation, and inefficient data collection. In this work, we demonstrate a broadband NIR compressive spectral imaging system that is capable of capturing hyperspectral data covering a broad spectral bandwidth ranging from 700 to 1600 nm. By segmenting wavelengths and designing specialized optical components, our design overcomes hardware spectral limitations to capture broadband data, while the reflective optical structure makes the system compact. This approach provides a novel technical solution for NIR hyperspectral imaging.
Integrated Snapshot Near-infrared Hypersepctral Imaging Framework with Diffractive Optics
Aug 20, 2025



We propose an integrated snapshot near-infrared hyperspectral imaging framework that combines designed DOE with NIRSA-Net. The results demonstrate near-infrared spectral imaging at 700-1000nm with 10nm resolution while achieving improvement of PSNR 1.47dB and SSIM 0.006.
InstanceBEV: Unifying Instance and BEV Representation for Global Modeling
May 20, 2025



Occupancy Grid Maps are widely used in navigation for their ability to represent 3D space occupancy. However, existing methods that utilize multi-view cameras to construct Occupancy Networks for perception modeling suffer from cubic growth in data complexity. Adopting a Bird's-Eye View (BEV) perspective offers a more practical solution for autonomous driving, as it provides higher semantic density and mitigates complex object occlusions. Nonetheless, BEV-based approaches still require extensive engineering optimizations to enable efficient large-scale global modeling. To address this challenge, we propose InstanceBEV, the first method to introduce instance-level dimensionality reduction for BEV, enabling global modeling with transformers without relying on sparsification or acceleration operators. Different from other BEV methods, our approach directly employs transformers to aggregate global features. Compared to 3D object detection models, our method samples global feature maps into 3D space. Experiments on OpenOcc-NuScenes dataset show that InstanceBEV achieves state-of-the-art performance while maintaining a simple, efficient framework without requiring additional optimizations.
Efficient training for large-scale optical neural network using an evolutionary strategy and attention pruning
May 19, 2025MZI-based block optical neural networks (BONNs), which can achieve large-scale network models, have increasingly drawn attentions. However, the robustness of the current training algorithm is not high enough. Moreover, large-scale BONNs usually contain numerous trainable parameters, resulting in expensive computation and power consumption. In this article, by pruning matrix blocks and directly optimizing the individuals in population, we propose an on-chip covariance matrix adaptation evolution strategy and attention-based pruning (CAP) algorithm for large-scale BONNs. The calculated results demonstrate that the CAP algorithm can prune 60% and 80% of the parameters for MNIST and Fashion-MNIST datasets, respectively, while only degrades the performance by 3.289% and 4.693%. Considering the influence of dynamic noise in phase shifters, our proposed CAP algorithm (performance degradation of 22.327% for MNIST dataset and 24.019% for Fashion-MNIST dataset utilizing a poor fabricated chip and electrical control with a standard deviation of 0.5) exhibits strongest robustness compared with both our previously reported block adjoint training algorithm (43.963% and 41.074%) and the covariance matrix adaptation evolution strategy (25.757% and 32.871%), respectively. Moreover, when 60% of the parameters are pruned, the CAP algorithm realizes 88.5% accuracy in experiment for the simplified MNIST dataset, which is similar to the simulation result without noise (92.1%). Additionally, we simulationally and experimentally demonstrate that using MZIs with only internal phase shifters to construct BONNs is an efficient way to reduce both the system area and the required trainable parameters. Notably, our proposed CAP algorithm show excellent potential for larger-scale network models and more complex tasks.
Following the Autoregressive Nature of LLM Embeddings via Compression and Alignment
Feb 17, 2025A new trend uses LLMs as dense text encoders via contrastive learning. However, since LLM embeddings predict the probability distribution of the next token, they are inherently generative and distributive, conflicting with contrastive learning, which requires embeddings to capture full-text semantics and align via cosine similarity. This discrepancy hinders the full utilization of LLMs' pre-training capabilities, resulting in inefficient learning. In response to this issue, we propose AutoRegEmbed, a new contrastive learning method built on embedding conditional probability distributions, which integrates two core tasks: information compression and conditional distribution alignment. The information compression task encodes text into the embedding space, ensuring that the embedding vectors capture global semantics. The conditional distribution alignment task focuses on aligning text embeddings with positive samples embeddings by leveraging the conditional distribution of embeddings while simultaneously reducing the likelihood of generating negative samples from text embeddings, thereby achieving embedding alignment and uniformity. Experimental results demonstrate that our method significantly outperforms traditional contrastive learning approaches and achieves performance comparable to state-of-the-art models when using the same amount of data.
Revisiting Robust RAG: Do We Still Need Complex Robust Training in the Era of Powerful LLMs?
Feb 17, 2025Retrieval-augmented generation (RAG) systems often suffer from performance degradation when encountering noisy or irrelevant documents, driving researchers to develop sophisticated training strategies to enhance their robustness against such retrieval noise. However, as large language models (LLMs) continue to advance, the necessity of these complex training methods is increasingly questioned. In this paper, we systematically investigate whether complex robust training strategies remain necessary as model capacity grows. Through comprehensive experiments spanning multiple model architectures and parameter scales, we evaluate various document selection methods and adversarial training techniques across diverse datasets. Our extensive experiments consistently demonstrate that as models become more powerful, the performance gains brought by complex robust training methods drop off dramatically. We delve into the rationale and find that more powerful models inherently exhibit superior confidence calibration, better generalization across datasets (even when trained with randomly selected documents), and optimal attention mechanisms learned with simpler strategies. Our findings suggest that RAG systems can benefit from simpler architectures and training strategies as models become more powerful, enabling more scalable applications with minimal complexity.
Detecting Malicious Concepts Without Image Generation in AIGC
Feb 13, 2025The task of text-to-image generation has achieved tremendous success in practice, with emerging concept generation models capable of producing highly personalized and customized content. Fervor for concept generation is increasing rapidly among users, and platforms for concept sharing have sprung up. The concept owners may upload malicious concepts and disguise them with non-malicious text descriptions and example images to deceive users into downloading and generating malicious content. The platform needs a quick method to determine whether a concept is malicious to prevent the spread of malicious concepts. However, simply relying on concept image generation to judge whether a concept is malicious requires time and computational resources. Especially, as the number of concepts uploaded and downloaded on the platform continues to increase, this approach becomes impractical and poses a risk of generating malicious content. In this paper, we propose Concept QuickLook, the first systematic work to incorporate malicious concept detection into research, which performs detection based solely on concept files without generating any images. We define malicious concepts and design two work modes for detection: concept matching and fuzzy detection. Extensive experiments demonstrate that the proposed Concept QuickLook can detect malicious concepts and demonstrate practicality in concept sharing platforms. We also design robustness experiments to further validate the effectiveness of the solution. We hope this work can initiate malicious concept detection tasks and provide some inspiration.
Integration of Communication and Computational Imaging
Oct 29, 2024



Communication enables the expansion of human visual perception beyond the limitations of time and distance, while computational imaging overcomes the constraints of depth and breadth. Although impressive achievements have been witnessed with the two types of technologies, the occlusive information flow between the two domains is a bottleneck hindering their ulterior progression. Herein, we propose a novel framework that integrates communication and computational imaging (ICCI) to break through the inherent isolation between communication and computational imaging for remote perception. By jointly considering the sensing and transmitting of remote visual information, the ICCI framework performs a full-link information transfer optimization, aiming to minimize information loss from the generation of the information source to the execution of the final vision tasks. We conduct numerical analysis and experiments to demonstrate the ICCI framework by integrating communication systems and snapshot compressive imaging systems. Compared with straightforward combination schemes, which sequentially execute sensing and transmitting, the ICCI scheme shows greater robustness against channel noise and impairments while achieving higher data compression. Moreover, an 80 km 27-band hyperspectral video perception with a rate of 30 fps is experimentally achieved. This new ICCI remote perception paradigm offers a highefficiency solution for various real-time computer vision tasks.