 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramidal Flow Matching for Efficient Video Generative Modeling
Oct 08, 2024Video generation requires modeling a vast spatiotemporal space, which demands significant computational resources and data usage. To reduce the complexity, the prevailing approaches employ a cascaded architecture to avoid direct training with full resolution. Despite reducing computational demands, the separate optimization of each sub-stage hinders knowledge sharing and sacrifices flexibility. This work introduces a unified pyramidal flow matching algorithm. It reinterprets the original denoising trajectory as a series of pyramid stages, where only the final stage operates at the full resolution, thereby enabling more efficient video generative modeling. Through our sophisticated design, the flows of different pyramid stages can be interlinked to maintain continuity. Moreover, we craft autoregressive video generation with a temporal pyramid to compress the full-resolution history. The entire framework can be optimized in an end-to-end manner and with a single unified Diffusion Transformer (DiT). Extensive experiments demonstrate that our method supports generating high-quality 5-second (up to 10-second) videos at 768p resolution and 24 FPS within 20.7k A100 GPU training hours. All code and models will be open-sourced at https://pyramid-flow.github.io.
Closed-loop Long-horizon Robotic Planning via Equilibrium Sequence Modeling
Oct 02, 2024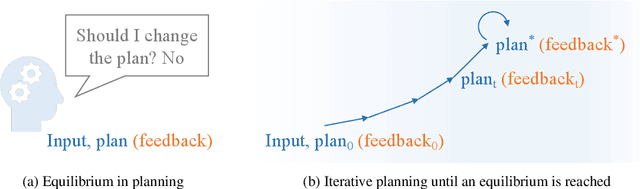

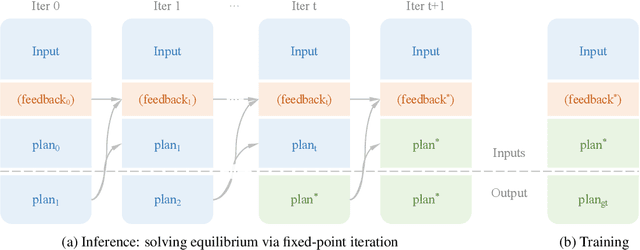
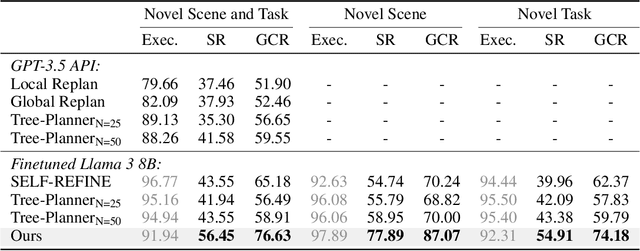
In the endeavor to make autonomous robots take actions, task planning is a major challenge that requires translating high-level task descriptions into long-horizon action sequences. Despite recent advances in language model agents, they remain prone to planning errors and limited in their ability to plan ahead. To address these limitations in robotic planning, we advocate a self-refining scheme that iteratively refines a draft plan until an equilibrium is reached. Remarkably, this process can be optimized end-to-end from an analytical perspective without the need to curate additional verifiers or reward models, allowing us to train self-refining planners in a simple supervised learning fashion. Meanwhile, a nested equilibrium sequence modeling procedure is devised for efficient closed-loop planning that incorporates useful feedback from the environment (or an internal world model). Our method is evaluated on the VirtualHome-Env benchmark, showing advanced performance with better scaling for inference computation. Code is available at https://github.com/Singularity0104/equilibrium-planner.
RectifID: Personalizing Rectified Flow with Anchored Classifier Guidance
May 23, 2024Customizing diffusion models to generate identity-preserving images from user-provided reference images is an intriguing new problem. The prevalent approaches typically require training on extensive domain-specific images to achieve identity preservation, which lacks flexibility across different use cases. To address this issue, we exploit classifier guidance, a training-free technique that steers diffusion models using an existing classifier, for personalized image generation. Our study shows that based on a recent rectified flow framework, the major limitation of vanilla classifier guidance in requiring a special classifier can be resolved with a simple fixed-point solution, allowing flexible personalization with off-the-shelf image discriminators. Moreover, its solving procedure proves to be stable when anchored to a reference flow trajectory, with a convergence guarantee. The derived method is implemented on rectified flow with different off-the-shelf image discriminators, delivering advantageous personalization results for human faces, live subjects, and certain objects. Code is available at https://github.com/feifeiobama/RectifID.
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization
Feb 06, 2024



In light of recent advances in multimodal Large Language Models (LLMs), there is increasing attention to scaling them from image-text data to more informative real-world videos. Compared to static images, video poses unique challenges for effective large-scale pre-training due to the modeling of its spatiotemporal dynamics. In this paper, we address such limitations in video-language pre-training with an efficient video decomposition that represents each video as keyframes and temporal motions. These are then adapted to an LLM using well-designed tokenizers that discretize visual and temporal information as a few tokens, thus enabling unified generative pre-training of videos, images, and text. At inference, the generated tokens from the LLM are carefully recovered to the original continuous pixel space to create various video content. Our proposed framework is both capable of comprehending and generating image and video content, as demonstrated by its competitive performance across 13 multimodal benchmarks in image and video understanding and generation. Our code and models will be available at https://video-lavit.github.io.
Regularizing Second-Order Influences for Continual Learning
Apr 20, 2023Continual learning aims to learn on non-stationary data streams without catastrophically forgetting previous knowledge. Prevalent replay-based methods address this challenge by rehearsing on a small buffer holding the seen data, for which a delicate sample selection strategy is required. However, existing selection schemes typically seek only to maximize the utility of the ongoing selection, overlooking the interference between successive rounds of selection. Motivated by this, we dissect the interaction of sequential selection steps within a framework built on influence functions. We manage to identify a new class of second-order influences that will gradually amplify incidental bias in the replay buffer and compromise the selection process. To regularize the second-order effects, a novel selection objective is proposed, which also has clear connections to two widely adopted criteria. Furthermore, we present an efficient implementation for optimizing the proposed criterion. Experiments on multiple continual learning benchmarks demonstrate the advantage of our approach over state-of-the-art methods. Code is available at https://github.com/feifeiobama/InfluenceCL.