 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-loop Long-horizon Robotic Planning via Equilibrium Sequence Modeling
Oct 02, 2024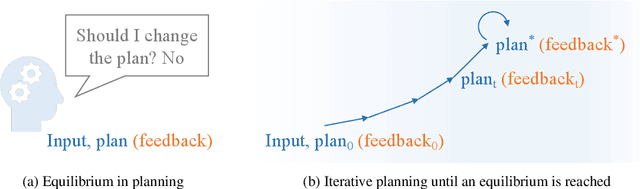

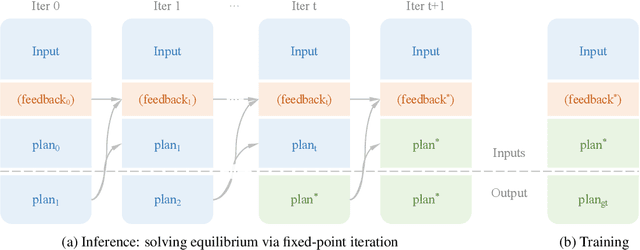
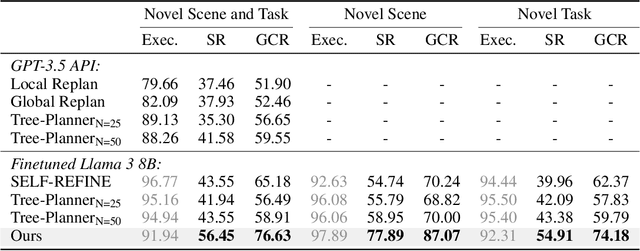
In the endeavor to make autonomous robots take actions, task planning is a major challenge that requires translating high-level task descriptions into long-horizon action sequences. Despite recent advances in language model agents, they remain prone to planning errors and limited in their ability to plan ahead. To address these limitations in robotic planning, we advocate a self-refining scheme that iteratively refines a draft plan until an equilibrium is reached. Remarkably, this process can be optimized end-to-end from an analytical perspective without the need to curate additional verifiers or reward models, allowing us to train self-refining planners in a simple supervised learning fashion. Meanwhile, a nested equilibrium sequence modeling procedure is devised for efficient closed-loop planning that incorporates useful feedback from the environment (or an internal world model). Our method is evaluated on the VirtualHome-Env benchmark, showing advanced performance with better scaling for inference computation. Code is available at https://github.com/Singularity0104/equilibrium-planner.
AVESFormer: Efficient Transformer Design for Real-Time Audio-Visual Segmentation
Aug 03, 2024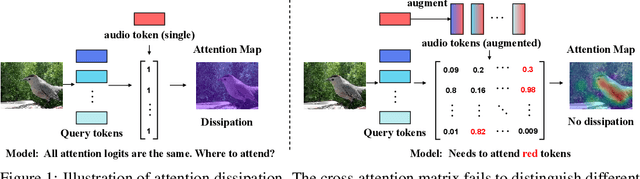

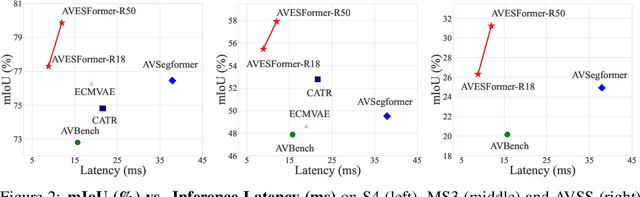

Recently, transformer-based models have demonstrated remarkable performance on audio-visual segmentation (AVS) tasks. However, their expensive computational cost makes real-time inference impractical. By characterizing attention maps of the network, we identify two key obstacles in AVS models: 1) attention dissipation, corresponding to the over-concentrated attention weights by Softmax within restricted frames, and 2) inefficient, burdensome transformer decoder, caused by narrow focus patterns in early stages. In this paper, we introduce AVESFormer, the first real-time Audio-Visual Efficient Segmentation transformer that achieves fast, efficient and light-weight simultaneously. Our model leverages an efficient prompt query generator to correct the behaviour of cross-attention. Additionally, we propose ELF decoder to bring greater efficiency by facilitating convolutions suitable for local features to reduce computational burdens. Extensive experiments demonstrate that our AVESFormer significantly enhances model performance, achieving 79.9% on S4, 57.9% on MS3 and 31.2% on AVSS, outperforming previous state-of-the-art and achieving an excellent trade-off between performance and speed. Code can be found at https://github.com/MarkXCloud/AVESFormer.git.