 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiTAG: Inverse Design for Natural Text Generation with Accurate Causal Graph Annotations
Apr 08, 2026A fundamental obstacle to causal discovery from text is the lack of causally annotated text data for use as ground truth, due to high annotation costs. This motivates an important task of generating text with causal graph annotations. Early template-based generation methods sacrifice text naturalness in exchange for high causal graph annotation accuracy. Recent Large Language Model (LLM)-dependent methods directly generate natural text from target graphs through LLMs, but do not guarantee causal graph annotation accuracy. Therefore, we propose iTAG, which performs real-world concept assignment to nodes before converting causal graphs into text in existing LLM-dependent methods. iTAG frames this process as an inverse problem with the causal graph as the target, iteratively examining and refining concept selection through Chain-of-Thought (CoT) reasoning so that the induced relations between concepts are as consistent as possible with the target causal relationships described by the causal graph. iTAG demonstrates both extremely high annotation accuracy and naturalness across extensive tests, and the results of testing text-based causal discovery algorithms with the generated data show high statistical correlation with real-world data. This suggests that iTAG-generated data can serve as a practical surrogate for scalable benchmarking of text-based causal discovery algorithms.
QueryCraft: Transformer-Guided Query Initialization for Enhanced Human-Object Interaction Detection
Aug 12, 2025Human-Object Interaction (HOI) detection aims to localize human-object pairs and recognize their interactions in images. Although DETR-based methods have recently emerged as the mainstream framework for HOI detection, they still suffer from a key limitation: Randomly initialized queries lack explicit semantics, leading to suboptimal detection performance. To address this challenge, we propose QueryCraft, a novel plug-and-play HOI detection framework that incorporates semantic priors and guided feature learning through transformer-based query initialization. Central to our approach is \textbf{ACTOR} (\textbf{A}ction-aware \textbf{C}ross-modal \textbf{T}ransf\textbf{OR}mer), a cross-modal Transformer encoder that jointly attends to visual regions and textual prompts to extract action-relevant features. Rather than merely aligning modalities, ACTOR leverages language-guided attention to infer interaction semantics and produce semantically meaningful query representations. To further enhance object-level query quality, we introduce a \textbf{P}erceptual \textbf{D}istilled \textbf{Q}uery \textbf{D}ecoder (\textbf{PDQD}), which distills object category awareness from a pre-trained detector to serve as object query initiation. This dual-branch query initialization enables the model to generate more interpretable and effective queries for HOI detection. Extensive experiments on HICO-Det and V-COCO benchmarks demonstrate that our method achieves state-of-the-art performance and strong generalization. Code will be released upon publication.
Prompt Guidance and Human Proximal Perception for HOT Prediction with Regional Joint Loss
Jul 02, 2025



The task of Human-Object conTact (HOT) detection involves identifying the specific areas of the human body that are touching objects. Nevertheless, current models are restricted to just one type of image, often leading to too much segmentation in areas with little interaction, and struggling to maintain category consistency within specific regions. To tackle this issue, a HOT framework, termed \textbf{P3HOT}, is proposed, which blends \textbf{P}rompt guidance and human \textbf{P}roximal \textbf{P}erception. To begin with, we utilize a semantic-driven prompt mechanism to direct the network's attention towards the relevant regions based on the correlation between image and text. Then a human proximal perception mechanism is employed to dynamically perceive key depth range around the human, using learnable parameters to effectively eliminate regions where interactions are not expected. Calculating depth resolves the uncertainty of the overlap between humans and objects in a 2D perspective, providing a quasi-3D viewpoint. Moreover, a Regional Joint Loss (RJLoss) has been created as a new loss to inhibit abnormal categories in the same area. A new evaluation metric called ``AD-Acc.'' is introduced to address the shortcomings of existing methods in addressing negative samples. Comprehensive experimental results demonstrate that our approach achieves state-of-the-art performance in four metrics across two benchmark datasets. Specifically, our model achieves an improvement of \textbf{0.7}$\uparrow$, \textbf{2.0}$\uparrow$, \textbf{1.6}$\uparrow$, and \textbf{11.0}$\uparrow$ in SC-Acc., mIoU, wIoU, and AD-Acc. metrics, respectively, on the HOT-Annotated dataset. Code is available at https://github.com/YuxiaoWang-AI/P3HOT.
Precision-Enhanced Human-Object Contact Detection via Depth-Aware Perspective Interaction and Object Texture Restoration
Dec 13, 2024



Human-object contact (HOT) is designed to accurately identify the areas where humans and objects come into contact. Current methods frequently fail to account for scenarios where objects are frequently blocking the view, resulting in inaccurate identification of contact areas. To tackle this problem, we suggest using a perspective interaction HOT detector called PIHOT, which utilizes a depth map generation model to offer depth information of humans and objects related to the camera, thereby preventing false interaction detection. Furthermore, we use mask dilatation and object restoration techniques to restore the texture details in covered areas, improve the boundaries between objects, and enhance the perception of humans interacting with objects. Moreover, a spatial awareness perception is intended to concentrate on the characteristic features close to the points of contact. The experimental results show that the PIHOT algorithm achieves state-of-the-art performance on three benchmark datasets for HOT detection tasks. Compared to the most recent DHOT, our method enjoys an average improvement of 13%, 27.5%, 16%, and 18.5% on SC-Acc., C-Acc., mIoU, and wIoU metrics, respectively.
Pyramidal Flow Matching for Efficient Video Generative Modeling
Oct 08, 2024Video generation requires modeling a vast spatiotemporal space, which demands significant computational resources and data usage. To reduce the complexity, the prevailing approaches employ a cascaded architecture to avoid direct training with full resolution. Despite reducing computational demands, the separate optimization of each sub-stage hinders knowledge sharing and sacrifices flexibility. This work introduces a unified pyramidal flow matching algorithm. It reinterprets the original denoising trajectory as a series of pyramid stages, where only the final stage operates at the full resolution, thereby enabling more efficient video generative modeling. Through our sophisticated design, the flows of different pyramid stages can be interlinked to maintain continuity. Moreover, we craft autoregressive video generation with a temporal pyramid to compress the full-resolution history. The entire framework can be optimized in an end-to-end manner and with a single unified Diffusion Transformer (DiT). Extensive experiments demonstrate that our method supports generating high-quality 5-second (up to 10-second) videos at 768p resolution and 24 FPS within 20.7k A100 GPU training hours. All code and models will be open-sourced at https://pyramid-flow.github.io.
Harder Tasks Need More Experts: Dynamic Routing in MoE Models
Mar 12, 2024In this paper, we introduce a novel dynamic expert selection framework for Mixture of Experts (MoE) models, aiming to enhance computational efficiency and model performance by adjusting the number of activated experts based on input difficulty. Unlike traditional MoE approaches that rely on fixed Top-K routing, which activates a predetermined number of experts regardless of the input's complexity, our method dynamically selects experts based on the confidence level in expert selection for each input. This allows for a more efficient utilization of computational resources, activating more experts for complex tasks requiring advanced reasoning and fewer for simpler tasks. Through extensive evaluations, our dynamic routing method demonstrates substantial improvements over conventional Top-2 routing across various benchmarks, achieving an average improvement of 0.7% with less than 90% activated parameters. Further analysis shows our model dispatches more experts to tasks requiring complex reasoning skills, like BBH, confirming its ability to dynamically allocate computational resources in alignment with the input's complexity. Our findings also highlight a variation in the number of experts needed across different layers of the transformer model, offering insights into the potential for designing heterogeneous MoE frameworks. The code and models are available at https://github.com/ZhenweiAn/Dynamic_MoE.
Few-shot Knowledge Transfer for Fine-grained Cartoon Face Generation
Jul 27, 2020

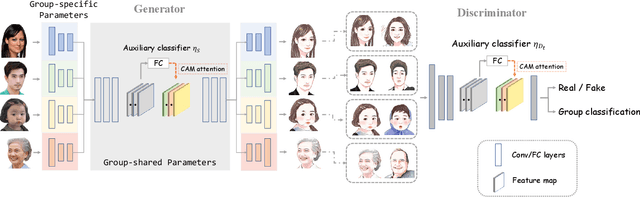

In this paper, we are interested in generating fine-grained cartoon faces for various groups. We assume that one of these groups consists of sufficient training data while the others only contain few samples. Although the cartoon faces of these groups share similar style, the appearances in various groups could still have some specific characteristics, which makes them differ from each other. A major challenge of this task is how to transfer knowledge among groups and learn group-specific characteristics with only few samples. In order to solve this problem, we propose a two-stage training process. First, a basic translation model for the basic group (which consists of sufficient data) is trained. Then, given new samples of other groups, we extend the basic model by creating group-specific branches for each new group. Group-specific branches are updated directly to capture specific appearances for each group while the remaining group-shared parameters are updated indirectly to maintain the distribution of intermediate feature space. In this manner, our approach is capable to generate high-quality cartoon faces for various groups.
Fast Intent Classification for Spoken Language Understanding
Dec 03, 2019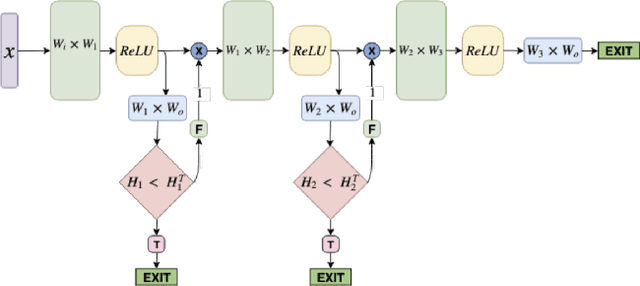
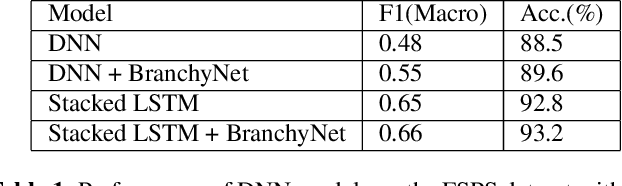
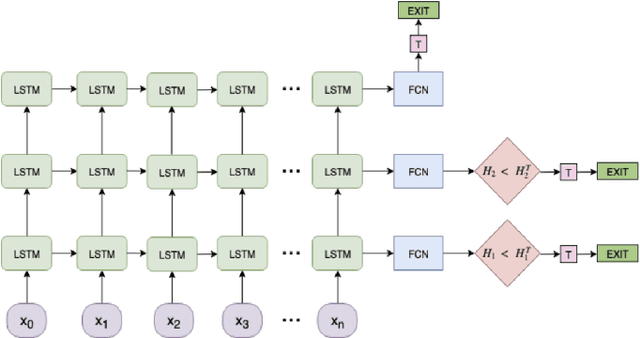
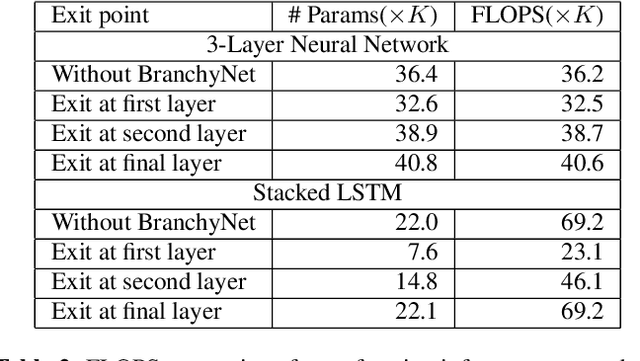
Spoken Language Understanding (SLU) systems consist of several machine learning components operating together (e.g. intent classification, named entity recognition and resolution). Deep learning models have obtained state of the art results on several of these tasks, largely attributed to their better modeling capacity. However, an increase in modeling capacity comes with added costs of higher latency and energy usage, particularly when operating on low complexity devices. To address the latency and computational complexity issues, we explore a BranchyNet scheme on an intent classification scheme within SLU systems. The BranchyNet scheme when applied to a high complexity model, adds exit points at various stages in the model allowing early decision making for a set of queries to the SLU model. We conduct experiments on the Facebook Semantic Parsing dataset with two candidate model architectures for intent classification. Our experiments show that the BranchyNet scheme provides gains in terms of computational complexity without compromising model accuracy. We also conduct analytical studies regarding the improvements in the computational cost, distribution of utterances that egress from various exit points and the impact of adding more complexity to models with the BranchyNet scheme.