 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualising the Attractor Landscape of Neural Cellular Automata
Apr 12, 2026As Neural Cellular Automata (NCAs) are increasingly applied outside of the toy models in Artificial Life, there is a pressing need to understand how they behave and to build appropriate routes to interpret what they have learnt. By their very nature, the benefits of training NCAs are balanced with a lack of interpretability: we can engineer emergent behaviour, but have limited ability to understand what has been learnt. In this paper, we apply a variety of techniques to pry open the NCA black box and glean some understanding of what it has learnt to do. We apply techniques from manifold learning (principal components analysis and both dense and sparse autoencoders) along with techniques from topological data analysis (persistent homology) to capture the NCA's underlying behavioural manifold, with varying success. Results show that when analysis is performed at a macroscopic level (i.e. taking the entire NCA state as a single data point), the underlying manifold is often quite simple and can be captured and analysed quite well. When analysis is performed at a microscopic level (i.e. taking the state of individual cells as a single data point), the manifold is highly complex and more complicated techniques are required in order to make sense of it.
Speech and Text-Based Emotion Recognizer
Dec 10, 2023Affective computing is a field of study that focuses on developing systems and technologies that can understand, interpret, and respond to human emotions. Speech Emotion Recognition (SER), in particular, has got a lot of attention from researchers in the recent past. However, in many cases, the publicly available datasets, used for training and evaluation, are scarce and imbalanced across the emotion labels. In this work, we focused on building a balanced corpus from these publicly available datasets by combining these datasets as well as employing various speech data augmentation techniques. Furthermore, we experimented with different architectures for speech emotion recognition. Our best system, a multi-modal speech, and text-based model, provides a performance of UA(Unweighed Accuracy) + WA (Weighed Accuracy) of 157.57 compared to the baseline algorithm performance of 119.66
Steam Recommendation System
May 03, 2023


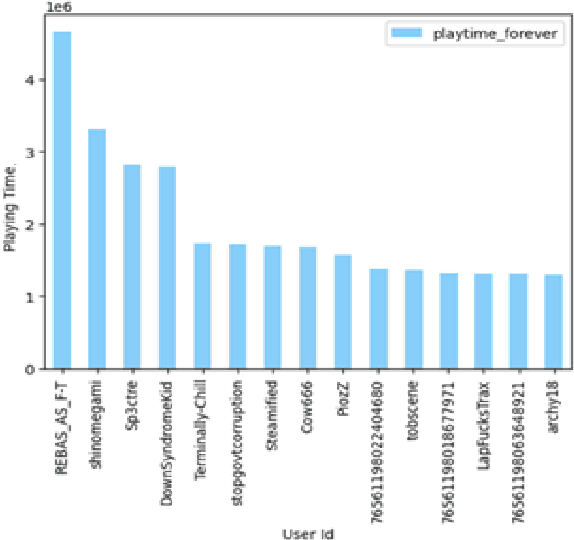
We aim to leverage the interactions between users and items in the Steam community to build a game recommendation system that makes personalized suggestions to players in order to boost Steam's revenue as well as improve the users' gaming experience. The whole project is built on Apache Spark and deals with Big Data. The final output of the project is a recommendation system that gives a list of the top 5 items that the users will possibly like.6
Literature on Hand GESTURE Recognition using Graph based methods
Jul 01, 2022

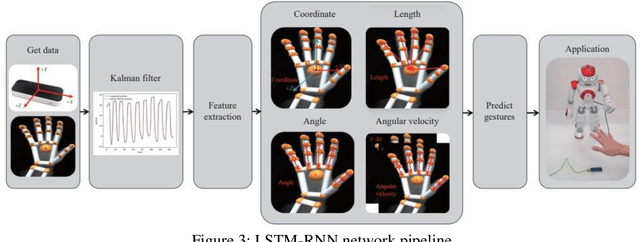

Skeleton based recognition systems are gaining popularity and machine learning models focusing on points or joints in a skeleton have proved to be computationally effective and application in many areas like Robotics. It is easy to track points and thereby preserving spatial and temporal information, which plays an important role in abstracting the required information, classification becomes an easy task. In this paper, we aim to study these points but using a cloud mechanism, where we define a cloud as collection of points. However, when we add temporal information, it may not be possible to retrieve the coordinates of a point in each frame and hence instead of focusing on a single point, we can use k-neighbors to retrieve the state of the point under discussion. Our focus is to gather such information using weight sharing but making sure that when we try to retrieve the information from neighbors, we do not carry noise with it. LSTM which has capability of long-term modelling and can carry both temporal and spatial information. In this article we tried to summarise graph based gesture recognition method.
Fast Intent Classification for Spoken Language Understanding
Dec 03, 2019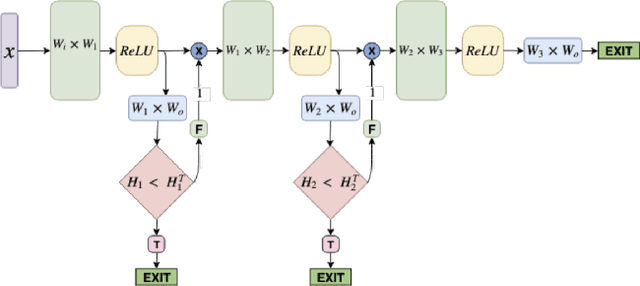
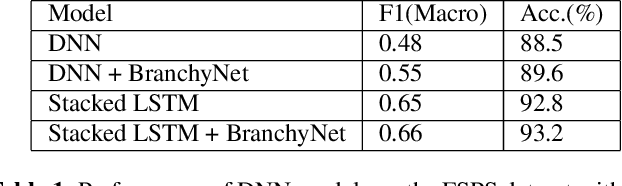
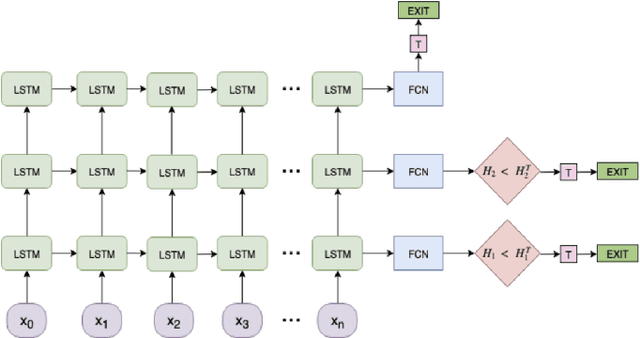
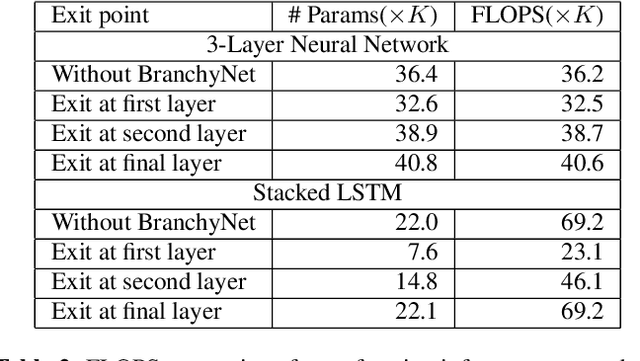
Spoken Language Understanding (SLU) systems consist of several machine learning components operating together (e.g. intent classification, named entity recognition and resolution). Deep learning models have obtained state of the art results on several of these tasks, largely attributed to their better modeling capacity. However, an increase in modeling capacity comes with added costs of higher latency and energy usage, particularly when operating on low complexity devices. To address the latency and computational complexity issues, we explore a BranchyNet scheme on an intent classification scheme within SLU systems. The BranchyNet scheme when applied to a high complexity model, adds exit points at various stages in the model allowing early decision making for a set of queries to the SLU model. We conduct experiments on the Facebook Semantic Parsing dataset with two candidate model architectures for intent classification. Our experiments show that the BranchyNet scheme provides gains in terms of computational complexity without compromising model accuracy. We also conduct analytical studies regarding the improvements in the computational cost, distribution of utterances that egress from various exit points and the impact of adding more complexity to models with the BranchyNet scheme.