 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Retrieval via Diffusion Transformer with Metric-Ordered Sequence Training and Hybrid-Policy Preference Optimization
Jun 25, 2026Embedding-based retrieval ranks items by their similarity to a query in a shared vector space and usually aims to return the highest-scoring items. In many production settings this is not what is wanted: given a seed set that expresses a fine-grained pattern, one needs more items that both satisfy a target attribute and stay within that pattern. We formalize this as pattern-preserving attribute retrieval. The two goals pull against each other: averaging the seeds preserves the pattern but stays in a low-attribute region, while global attribute retrieval drifts to unrelated patterns. We approach the task with continuous generative retrieval, where a model reads a sequence of item embeddings and generates query embeddings for nearest-neighbor search. We propose MO-DiT+HPPO, a staged framework with raw-sequence pretraining, multi-domain metric-ordered continuation pretraining, tail-centroid fine-tuning, and HPPO. Metric-ordered training turns sparse online retrieval labels into in-pattern trajectories ordered from low to high predicted attribute density, teaching one model the metric-improvement direction across domains. HPPO aligns the generated query distribution with the true online objective by labeling a hybrid candidate pool with the online intersection metric and applying reference-anchored preference optimization. A Pareto pair filter keeps only winner pairs that do not lower same-pattern purity, raising the attribute metric without sacrificing the pattern. Across four attribute domains under item- and pattern-holdout protocols, metric-ordered DiT improves the intersection metric over a pretrained generative retriever, and HPPO improves it further, with significant gains on seven of eight domain-split cells and a marginal tie on the hardest split. Metric-predictor validation, order ablations, CPT/SFT comparisons, and a candidate-policy ablation show where the gains come from.
Measuring and Mitigating Post-hoc Rationalization in Reverse Chain-of-Thought Generation
Feb 16, 2026Reverse Chain-of-Thought Generation (RCG) synthesizes reasoning traces from query-answer pairs, but runs the risk of producing post-hoc rationalizations: when models can see the answer during generation, the answer serves as a cognitive anchor that shapes the entire explanation. We formalize this phenomenon through a three-level measurement hierarchy: lexical, entropic, and probabilistic anchoring, each captures surface artifacts, entropy dynamics, and latent answer dependence, respectively. We analyze semantic suppression, the intuitive mitigation strategy that instructs models to ignore the answer, to find out its counterproduction: while it reduces lexical overlap, it paradoxically increases entropic and probabilistic anchoring. Drawing on Ironic Process Theory from cognitive psychology, we attribute this failure to active monitoring of the forbidden answer, which inadvertently deepens dependence on it. To break this cycle, we propose Structural Skeleton-guided Reasoning (SSR), a two-phase approach that first generates an answer-invariant functional skeleton structure, then uses this skeleton to guide full trace generation. By redirecting the information flow to structural planning rather than answer monitoring, SSR consistently reduces anchoring across all three levels. We further introduce Distilled SSR (SSR-D), which fine-tunes models on teacher-generated SSR traces to ensure reliable structural adherence. Experiments across open-ended reasoning benchmarks demonstrate that SSR-D achieves up to 10% improvement over suppression baselines while preserving out-of-distribution (OOD) generalization.
Nanbeige4.1-3B: A Small General Model that Reasons, Aligns, and Acts
Feb 13, 2026We present Nanbeige4.1-3B, a unified generalist language model that simultaneously achieves strong agentic behavior, code generation, and general reasoning with only 3B parameters. To the best of our knowledge, it is the first open-source small language model (SLM) to achieve such versatility in a single model. To improve reasoning and preference alignment, we combine point-wise and pair-wise reward modeling, ensuring high-quality, human-aligned responses. For code generation, we design complexity-aware rewards in Reinforcement Learning, optimizing both correctness and efficiency. In deep search, we perform complex data synthesis and incorporate turn-level supervision during training. This enables stable long-horizon tool interactions, allowing Nanbeige4.1-3B to reliably execute up to 600 tool-call turns for complex problem-solving. Extensive experimental results show that Nanbeige4.1-3B significantly outperforms prior models of similar scale, such as Nanbeige4-3B-2511 and Qwen3-4B, even achieving superior performance compared to much larger models, such as Qwen3-30B-A3B. Our results demonstrate that small models can achieve both broad competence and strong specialization simultaneously, redefining the potential of 3B parameter models.
PACE: Prefix-Protected and Difficulty-Aware Compression for Efficient Reasoning
Feb 12, 2026Language Reasoning Models (LRMs) achieve strong performance by scaling test-time computation but often suffer from ``overthinking'', producing excessively long reasoning traces that increase latency and memory usage. Existing LRMs typically enforce conciseness with uniform length penalties, which over-compress crucial early deduction steps at the sequence level and indiscriminately penalize all queries at the group level. To solve these limitations, we propose \textbf{\model}, a dual-level framework for prefix-protected and difficulty-aware compression under hierarchical supervision. At the sequence level, prefix-protected optimization employs decaying mixed rollouts to maintain valid reasoning paths while promoting conciseness. At the group level, difficulty-aware penalty dynamically scales length constraints based on query complexity, maintaining exploration for harder questions while curbing redundancy on easier ones. Extensive experiments on DeepSeek-R1-Distill-Qwen (1.5B/7B) demonstrate that \model achieves a substantial reduction in token usage (up to \textbf{55.7\%}) while simultaneously improving accuracy (up to \textbf{4.1\%}) on math benchmarks, with generalization ability to code, science, and general domains.
Harder Tasks Need More Experts: Dynamic Routing in MoE Models
Mar 12, 2024In this paper, we introduce a novel dynamic expert selection framework for Mixture of Experts (MoE) models, aiming to enhance computational efficiency and model performance by adjusting the number of activated experts based on input difficulty. Unlike traditional MoE approaches that rely on fixed Top-K routing, which activates a predetermined number of experts regardless of the input's complexity, our method dynamically selects experts based on the confidence level in expert selection for each input. This allows for a more efficient utilization of computational resources, activating more experts for complex tasks requiring advanced reasoning and fewer for simpler tasks. Through extensive evaluations, our dynamic routing method demonstrates substantial improvements over conventional Top-2 routing across various benchmarks, achieving an average improvement of 0.7% with less than 90% activated parameters. Further analysis shows our model dispatches more experts to tasks requiring complex reasoning skills, like BBH, confirming its ability to dynamically allocate computational resources in alignment with the input's complexity. Our findings also highlight a variation in the number of experts needed across different layers of the transformer model, offering insights into the potential for designing heterogeneous MoE frameworks. The code and models are available at https://github.com/ZhenweiAn/Dynamic_MoE.
A Step Closer to Comprehensive Answers: Constrained Multi-Stage Question Decomposition with Large Language Models
Nov 13, 2023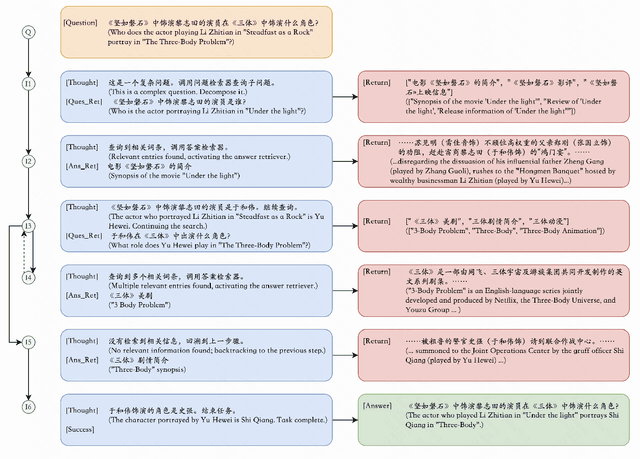
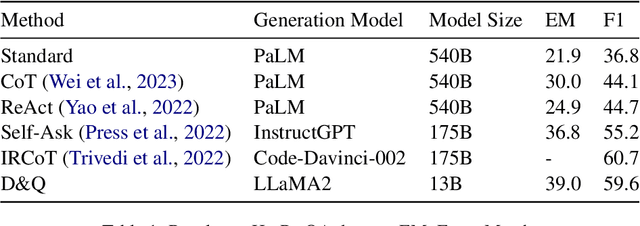
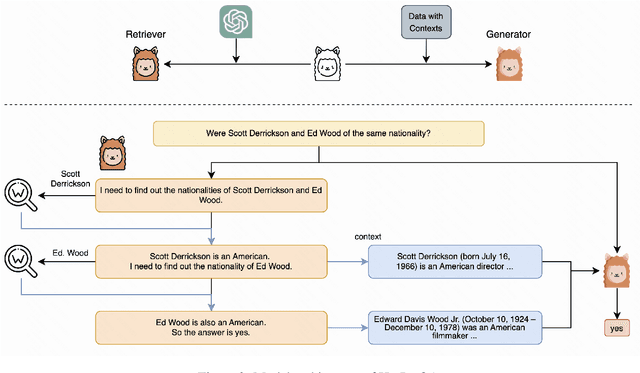

While large language models exhibit remarkable performance in the Question Answering task, they are susceptible to hallucinations. Challenges arise when these models grapple with understanding multi-hop relations in complex questions or lack the necessary knowledge for a comprehensive response. To address this issue, we introduce the "Decompose-and-Query" framework (D&Q). This framework guides the model to think and utilize external knowledge similar to ReAct, while also restricting its thinking to reliable information, effectively mitigating the risk of hallucinations. Experiments confirm the effectiveness of D&Q: On our ChitChatQA dataset, D&Q does not lose to ChatGPT in 67% of cases; on the HotPotQA question-only setting, D&Q achieved an F1 score of 59.6%. Our code is available at https://github.com/alkaidpku/DQ-ToolQA.
Lawyer LLaMA Technical Report
May 24, 2023



Large Language Models (LLMs), like LLaMA, have exhibited remarkable performances across various tasks. Nevertheless, when deployed to specific domains such as law or medicine, the models still confront the challenge of a deficiency in domain-specific knowledge and an inadequate capability to leverage that knowledge to resolve domain-related problems. In this paper, we focus on the legal domain and explore how to inject domain knowledge during the continual training stage and how to design proper supervised finetune tasks to help the model tackle practical issues. Moreover, to alleviate the hallucination problem during model's generation, we add a retrieval module and extract relevant articles before the model answers any queries. Augmenting with the extracted evidence, our model could generate more reliable responses. We release our data and model at https://github.com/AndrewZhe/lawyer-llama.
Do Charge Prediction Models Learn Legal Theory?
Oct 31, 2022The charge prediction task aims to predict the charge for a case given its fact description. Recent models have already achieved impressive accuracy in this task, however, little is understood about the mechanisms they use to perform the judgment.For practical applications, a charge prediction model should conform to the certain legal theory in civil law countries, as under the framework of civil law, all cases are judged according to certain local legal theories. In China, for example, nearly all criminal judges make decisions based on the Four Elements Theory (FET).In this paper, we argue that trustworthy charge prediction models should take legal theories into consideration, and standing on prior studies in model interpretation, we propose three principles for trustworthy models should follow in this task, which are sensitive, selective, and presumption of innocence.We further design a new framework to evaluate whether existing charge prediction models learn legal theories. Our findings indicate that, while existing charge prediction models meet the selective principle on a benchmark dataset, most of them are still not sensitive enough and do not satisfy the presumption of innocence. Our code and dataset are released at https://github.com/ZhenweiAn/EXP_LJP.