 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Retrieval via Diffusion Transformer with Metric-Ordered Sequence Training and Hybrid-Policy Preference Optimization
Jun 25, 2026Embedding-based retrieval ranks items by their similarity to a query in a shared vector space and usually aims to return the highest-scoring items. In many production settings this is not what is wanted: given a seed set that expresses a fine-grained pattern, one needs more items that both satisfy a target attribute and stay within that pattern. We formalize this as pattern-preserving attribute retrieval. The two goals pull against each other: averaging the seeds preserves the pattern but stays in a low-attribute region, while global attribute retrieval drifts to unrelated patterns. We approach the task with continuous generative retrieval, where a model reads a sequence of item embeddings and generates query embeddings for nearest-neighbor search. We propose MO-DiT+HPPO, a staged framework with raw-sequence pretraining, multi-domain metric-ordered continuation pretraining, tail-centroid fine-tuning, and HPPO. Metric-ordered training turns sparse online retrieval labels into in-pattern trajectories ordered from low to high predicted attribute density, teaching one model the metric-improvement direction across domains. HPPO aligns the generated query distribution with the true online objective by labeling a hybrid candidate pool with the online intersection metric and applying reference-anchored preference optimization. A Pareto pair filter keeps only winner pairs that do not lower same-pattern purity, raising the attribute metric without sacrificing the pattern. Across four attribute domains under item- and pattern-holdout protocols, metric-ordered DiT improves the intersection metric over a pretrained generative retriever, and HPPO improves it further, with significant gains on seven of eight domain-split cells and a marginal tie on the hardest split. Metric-predictor validation, order ablations, CPT/SFT comparisons, and a candidate-policy ablation show where the gains come from.
ResAdapt: Adaptive Resolution for Efficient Multimodal Reasoning
Mar 31, 2026Multimodal Large Language Models (MLLMs) achieve stronger visual understanding by scaling input fidelity, yet the resulting visual token growth makes jointly sustaining high spatial resolution and long temporal context prohibitive. We argue that the bottleneck lies not in how post-encoding representations are compressed but in the volume of pixels the encoder receives, and address it with ResAdapt, an Input-side adaptation framework that learns how much visual budget each frame should receive before encoding. ResAdapt couples a lightweight Allocator with an unchanged MLLM backbone, so the backbone retains its native visual-token interface while receiving an operator-transformed input. We formulate allocation as a contextual bandit and train the Allocator with Cost-Aware Policy Optimization (CAPO), which converts sparse rollout feedback into a stable accuracy-cost learning signal. Across budget-controlled video QA, temporal grounding, and image reasoning tasks, ResAdapt improves low-budget operating points and often lies on or near the efficiency-accuracy frontier, with the clearest gains on reasoning-intensive benchmarks under aggressive compression. Notably, ResAdapt supports up to 16x more frames at the same visual budget while delivering over 15% performance gain. Code is available at https://github.com/Xnhyacinth/ResAdapt.
WideSeek: Advancing Wide Research via Multi-Agent Scaling
Feb 02, 2026Search intelligence is evolving from Deep Research to Wide Research, a paradigm essential for retrieving and synthesizing comprehensive information under complex constraints in parallel. However, progress in this field is impeded by the lack of dedicated benchmarks and optimization methodologies for search breadth. To address these challenges, we take a deep dive into Wide Research from two perspectives: Data Pipeline and Agent Optimization. First, we produce WideSeekBench, a General Broad Information Seeking (GBIS) benchmark constructed via a rigorous multi-phase data pipeline to ensure diversity across the target information volume, logical constraints, and domains. Second, we introduce WideSeek, a dynamic hierarchical multi-agent architecture that can autonomously fork parallel sub-agents based on task requirements. Furthermore, we design a unified training framework that linearizes multi-agent trajectories and optimizes the system using end-to-end RL. Experimental results demonstrate the effectiveness of WideSeek and multi-agent RL, highlighting that scaling the number of agents is a promising direction for advancing the Wide Research paradigm.
Following the Autoregressive Nature of LLM Embeddings via Compression and Alignment
Feb 17, 2025A new trend uses LLMs as dense text encoders via contrastive learning. However, since LLM embeddings predict the probability distribution of the next token, they are inherently generative and distributive, conflicting with contrastive learning, which requires embeddings to capture full-text semantics and align via cosine similarity. This discrepancy hinders the full utilization of LLMs' pre-training capabilities, resulting in inefficient learning. In response to this issue, we propose AutoRegEmbed, a new contrastive learning method built on embedding conditional probability distributions, which integrates two core tasks: information compression and conditional distribution alignment. The information compression task encodes text into the embedding space, ensuring that the embedding vectors capture global semantics. The conditional distribution alignment task focuses on aligning text embeddings with positive samples embeddings by leveraging the conditional distribution of embeddings while simultaneously reducing the likelihood of generating negative samples from text embeddings, thereby achieving embedding alignment and uniformity. Experimental results demonstrate that our method significantly outperforms traditional contrastive learning approaches and achieves performance comparable to state-of-the-art models when using the same amount of data.
VaiBot: Shuttle Between the Instructions and Parameters
Feb 04, 2025How to interact with LLMs through \emph{instructions} has been widely studied by researchers. However, previous studies have treated the emergence of instructions and the training of LLMs on task data as separate processes, overlooking the inherent unity between the two. This paper proposes a neural network framework, VaiBot, that integrates VAE and VIB, designed to uniformly model, learn, and infer both deduction and induction tasks under LLMs. Through experiments, we demonstrate that VaiBot performs on par with existing baseline methods in terms of deductive capabilities while significantly surpassing them in inductive capabilities. We also find that VaiBot can scale up using general instruction-following data and exhibits excellent one-shot induction abilities. We finally synergistically integrate the deductive and inductive processes of VaiBot. Through T-SNE dimensionality reduction, we observe that its inductive-deductive process significantly improves the distribution of training parameters, enabling it to outperform baseline methods in inductive reasoning tasks. The code and data for this paper can be found at https://anonymous.4open.science/r/VaiBot-021F.
Generative Calibration for In-context Learning
Oct 16, 2023



As one of the most exciting features of large language models (LLMs), in-context learning is a mixed blessing. While it allows users to fast-prototype a task solver with only a few training examples, the performance is generally sensitive to various configurations of the prompt such as the choice or order of the training examples. In this paper, we for the first time theoretically and empirically identify that such a paradox is mainly due to the label shift of the in-context model to the data distribution, in which LLMs shift the label marginal $p(y)$ while having a good label conditional $p(x|y)$. With this understanding, we can simply calibrate the in-context predictive distribution by adjusting the label marginal, which is estimated via Monte-Carlo sampling over the in-context model, i.e., generation of LLMs. We call our approach as generative calibration. We conduct exhaustive experiments with 12 text classification tasks and 12 LLMs scaling from 774M to 33B, generally find that the proposed method greatly and consistently outperforms the ICL as well as state-of-the-art calibration methods, by up to 27% absolute in macro-F1. Meanwhile, the proposed method is also stable under different prompt configurations.
Unsupervised Text Style Transfer with Deep Generative Models
Aug 31, 2023



We present a general framework for unsupervised text style transfer with deep generative models. The framework models each sentence-label pair in the non-parallel corpus as partially observed from a complete quadruplet which additionally contains two latent codes representing the content and style, respectively. These codes are learned by exploiting dependencies inside the observed data. Then a sentence is transferred by manipulating them. Our framework is able to unify previous embedding and prototype methods as two special forms. It also provides a principled perspective to explain previously proposed techniques in the field such as aligned encoder and adversarial training. We further conduct experiments on three benchmarks. Both automatic and human evaluation results show that our methods achieve better or competitive results compared to several strong baselines.
Interpreting Sentiment Composition with Latent Semantic Tree
Aug 31, 2023
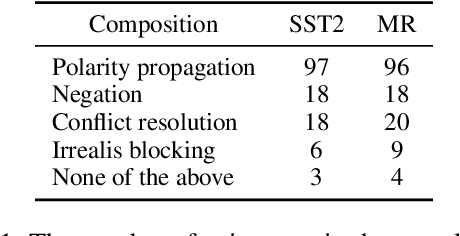
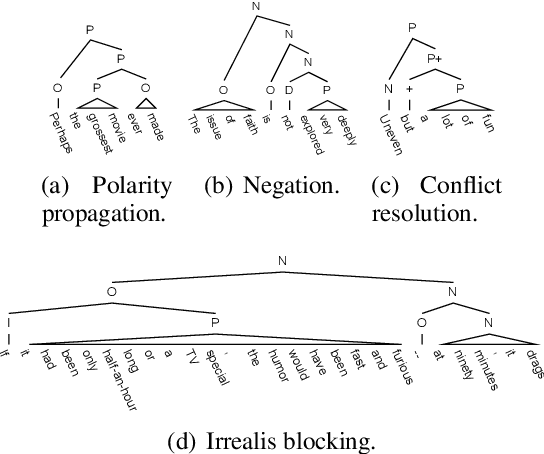

As the key to sentiment analysis, sentiment composition considers the classification of a constituent via classifications of its contained sub-constituents and rules operated on them. Such compositionality has been widely studied previously in the form of hierarchical trees including untagged and sentiment ones, which are intrinsically suboptimal in our view. To address this, we propose semantic tree, a new tree form capable of interpreting the sentiment composition in a principled way. Semantic tree is a derivation of a context-free grammar (CFG) describing the specific composition rules on difference semantic roles, which is designed carefully following previous linguistic conclusions. However, semantic tree is a latent variable since there is no its annotation in regular datasets. Thus, in our method, it is marginalized out via inside algorithm and learned to optimize the classification performance. Quantitative and qualitative results demonstrate that our method not only achieves better or competitive results compared to baselines in the setting of regular and domain adaptation classification, and also generates plausible tree explanations.
The Logic Traps in Evaluating Post-hoc Interpretations
Sep 12, 2021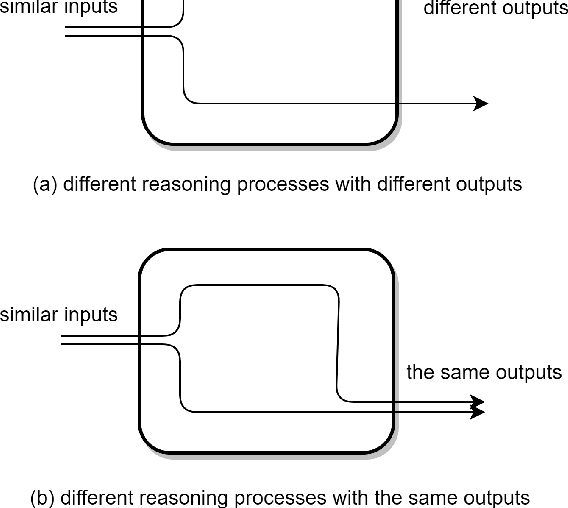
Post-hoc interpretation aims to explain a trained model and reveal how the model arrives at a decision. Though research on post-hoc interpretations has developed rapidly, one growing pain in this field is the difficulty in evaluating interpretations. There are some crucial logic traps behind existing evaluation methods, which are ignored by most works. In this opinion piece, we summarize four kinds evaluation methods and point out the corresponding logic traps behind them. We argue that we should be clear about these traps rather than ignore them and draw conclusions assertively.